UTF-8 Handling for Modern C++ ♦ FastUtf8::Uniseries Guide and Reference
By Kirk J Krauss
What’s here
- A guide to the FastUtf8::Uniseries C++ class outlined in the FastUtf8 overview and defined in fastutf8.cpp;
- A description of each Uniseries operator and method; and
- Example code.
Working with FastUtf8
The FastUtf8 namespace provides functionality that allows you to efficiently handle UTF-8 content, adaptively relying on the standard C library for optimized handling of ASCII text. Methods for handling content are provided via the FastUtf8::Uniseries class. In addition to covering the fundamentals of working with internationalized content, the class includes methods for searching semistructured content more efficiently than prior ASCII-centric techniques could search through ASCII text, and with simpler coding too. Usage of each FastUtf8::Uniseries method is described here.
An object of the FastUtf8::Uniseries class stores the following data:
- A content buffer, and
- An item of metadata.
The metadata item comprises a small set of flags and a length field. It fits into a single address on a 64-bit system, for speedy access. Though that optimization and others underlying the Uniseries class involve a degree of complexity, the class’s methods allow for easily comprehensible management of UTF-8 content and enable these operations:
- Creation, validation, duplication, and deletion of UTF-8 content;
- Slicing (substring extraction) and concatenation of UTF-8 content;
- Optimized slicing and concatenation of ASCII content;
- Separation of UTF-8 content based on UTF-8 separator tokens;
- Optimized separation of ASCII content based on ASCII tokens;
- Whole content comparison: case-sensitive and case-insensitive;
- Partial content comparison (basic full-text search): case-sensitive and case-insensitive;
- Wildcard-based content comparison: case-sensitive and case-insensitive;
- Conversion of 8-bit ASCII text to equivalent UTF-8 content;
- Content length and size determination, in code points and in bytes; and
- Trim (removal of outboard white space), index, and case fold operations.
The Uniseries class provides an iterator that can be obtained via the class’s begin() or end() method. An iterator obtained via end() refers to the position of a terminating null at the end of the content buffer. The iterator concepts indicate the capability to access content by index, i.e., using operator[], which is implemented as a method of the Uniseries class. But indexing into UTF-8 content, unless it comprises entirely 7-bit ASCII text, entails quite a performance drag.
To find a code point using the increment and decrement operators, such as operator++, the necessary UTF-8 traversal involves calls to the C-style functions CodePointAdvanceUtf8() and CodePointBacktrackUtf8(), found just in fastutf8.cpp. Individual code point comparison via operator== involves a call to CodePointCompareUtf8(), also just in fastutf8.cpp. The other FastUtf8 functionality is performed by C-style functions either declared in fastutf8.h (and also defined in fastutf8.cpp) or available in the standard C library.
Flags
The metadata for the Uniseries class includes these flags:
- IS_7BIT_CHAR_STRING;
- IS_CASE_INSENSITIVE;
- IS_LENGTH_LIMITED; and
- IS_DEALLOCATED_EXTERNALLY.
As these names suggest, the flags indicate whether the content is to be treated as 7-bit ASCII, as case-insensitive, and/or as length-limited. There are length-limited varieties of every relevant C-style function that gets invoked by the Uniseries methods; there also are equivalent – but faster – functions that operate over content until reaching any terminating null. Which to choose? See the “Null Terminators Significantly Outperform Length Limits” sidebar in the FastUtf8 overview.
A Uniseries object is constructed with default flag settings that determine its behavior, as follows. Every data-intensive Uniseries method is designed to handle multi-byte UTF-8 content by invoking a legacy-C-style function also declared in fastutf8.h and defined in fastutf8.cpp. Many of the Uniseries methods invoke standard C library functions when they’re handling 7-bit ASCII text, or they invoke similar char * functionality, for best ASCII performance. In most cases, one of several C-style functions is selected, based on settings of the Uniseries object’s flags. Unless default flag settings are changed, most Uniseries constructors set the flags for use with case-sensitive functionality that expects a terminating null, rather than set up a length check for each access to the object throughout its lifetime. Regarding that default behavior, the copy constructor is an exception; it copies the flags as part of the Uniseries object being copied.
The IS_DEALLOCATED_EXTERNALLY flag tells the Uniseries destructor to avoid deallocating content that is part of a larger buffer. This becomes useful if a relatively large buffer is separated into smaller null-terminated portions via the Uniseries::pSeparate() method, which works approximately like the C standard library’s strtok() function, except that it provides for tokenset search, plus it’s thread-safe.
The metadata also includes the length of the Uniseries object’s content buffer. There are 60 bits available for the content length, so it can represent content that’s up to 152 quadrillion code points in length. The length is specified as a count of code points, not bytes.
Public functionality
The Uniseries content and metadata is declared as private in fastutf8.h. All other Uniseries operators and methods are public, and all reside in the FastUtf8 namespace. In the example code provided here, they are presented as if the directive...
using namespace FastUtf8;...is in place, for brevity. All Uniseries content is intended to be compatible with 7-bit ASCII or with UTF-8. The Uniseries arrangements are not compatible with other natural language encodings.
Uniseries construction and destruction
Parameterized Constructors
This constructor validates the content in the inbound buffer and makes a deep copy by invoking C-style functions implemented in fastutf8.cpp. If the content includes any invalid code point(s), the constructor treats the entire buffer as 8-bit ASCII and converts it, as such, into valid UTF-8 content.
Signature
Uniseries(uint8_t *pInbound, bool bWrapBuffer = false);
Uniseries(char *pInbound, bool bWrapBuffer = false);
Parameters
[in] pInbound
A pointer to the inbound buffer.
[in, optional] bWrapBuffer
A flag indicating whether to perform a deep copy of the content. If this flag is true, the new Uniseries object’s content buffer will refer to the existing buffer referenced by pInbound. If this flag is false, the constructor will perform a deep copy into a new buffer. The flag’s default value is false.
Discussion
The first time the a Uniseries constructor is invoked during a run, it sets up mappings for case folding. To do so, it instantiates an object of the FastUtf8::Initializer class, which invokes CaseMappingSetupUtf8(). The Initializer class is instantiated just once per run.
The constructor invokes std::malloc() for buffer allocation. The C-style memory management is compatible with the underlying C-style functions, which rely on the standard C library. The constructor evaluates the content, records its length in the new object’s metadata, flags it as 7-bit ASCII in case that’s applicable, and (unless bWrapBuffer is set) invokes CopyUtf8() to copy inbound content. If the inbound content is invalid, the constructor considers it 8-bit ASCII and converts it, via Convert8BitAsciiToUtf8(), to valid UTF-8 content.
Standard constructor
The standard constructor creates an empty Uniseries object with a content buffer capacity specified in bytes. The metadata has no flags set upon construction.
Signature
Uniseries(size_t nBytes = 0);
Parameter
[in, optional] nBytes
The number of bytes to allocate, for the new Uniseries object’s content buffer.
Copy constructor
This constructor creates a Uniseries object from the content buffer and metadata of an existing one, with no validation, performing a deep copy like the parameterized constructors.
Signature
Uniseries(const Uniseries& that);
Parameter
[in] that
The Uniseries object whose content is to be copied.
Range-based slice constructors
Either of these constructors creates a Uniseries object from a buffer, or from a portion of a buffer, designated by the pFirst and pLast pointers.
Signature
Uniseries(const uint8_t *pFirst, const uint8_t *pLast);
Uniseries(uint8_t *pFirst, uint8_t *pLast);
Parameters
[in] pFirst
A pointer to the beginning of the inbound content.
[in] pLast
A pointer to the end of the inbound content.
Discussion
These constructors operate similarly to the parameterized constructors. Refer to the Discussion about them.
Destructor
The destructor deallocates the content buffer.
Signature
~Uniseries(void);
Uniseries assignment operators
Assignment of raw buffer content
These assignment operators replace the content and metadata associated with an existing Uniseries object, first validating the content in the inbound buffer and then making a deep copy by calling the CopyUtf8() function. If the content includes any invalid code point(s), the operator treats the entire buffer as 8-bit ASCII and converts it, via Convert8BitAsciiToUtf8(), to valid UTF-8 content.
Signature
Uniseries& operator=(uint8_t *pInbound);
Uniseries& operator=(char *pInbound);
Parameter
[in] pInbound
A pointer to the inbound buffer.
Assignment of Uniseries content
These assignment operators replace the content and metadata associated with the current Uniseries object with the content buffer and metadata of another existing one, with no validation, performing a deep copy like the copy constructor.
Signature
Uniseries& operator=(const Uniseries& that);
Uniseries& operator=(const Uniseries *pThat);
Parameter
[in] that or pThat
The Uniseries object whose content is to be copied, or a pointer to that object.
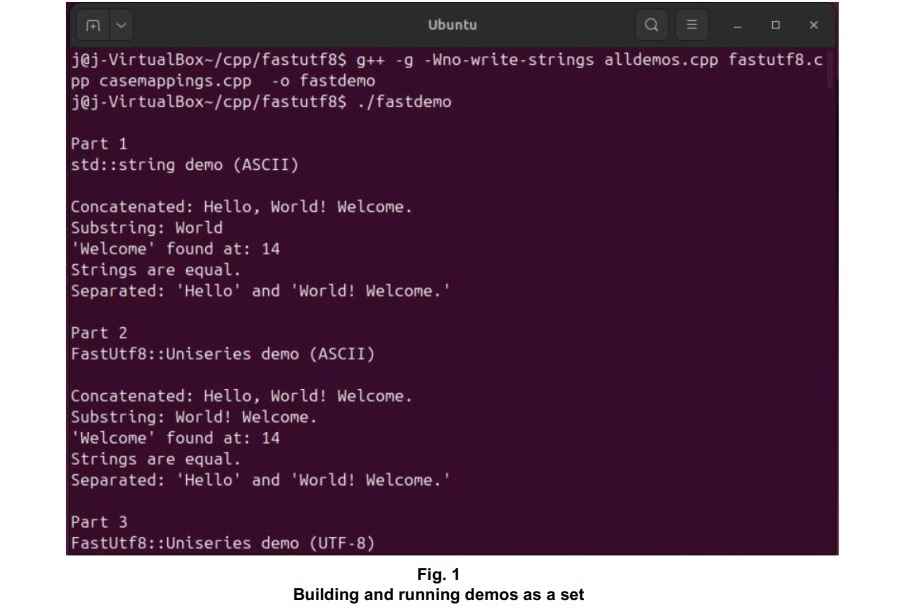
Example: Tokenset search demo
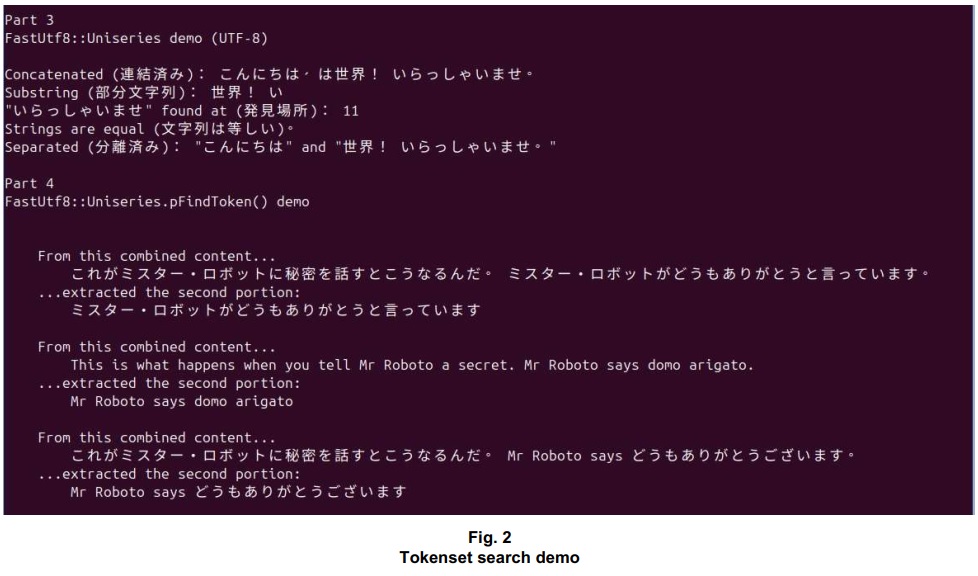
The UniseriespFindTokenDemo() function is part of the tokenset search demo (TokensetSearchDemo.cpp). Output from the demo program is shown in Fig. 2.
// C++ demo for UTF-8-ready routines.
//
// Certain functions in this file comprise machine-generated code and are
// described as such in the relevant comments. All other code in this file
// is copyright 2026 Kirk J Krauss and is a Derivative Work based on material
// that is copyright 2025 Kirk J Krauss and available at
//
// https://developforperformance.com/MatchingWildcardsInGoSwiftAndCpp.html
//
// Licensed under the Apache License, Version 2.0 (the "License"); you may not
// use this file except in compliance with the License. You may obtain a copy
// of the License at
//
// https://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
// WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
// License for the specific language governing permissions and limitations
// under the License.
//
#if !defined(__cplusplus)
#error "This is a demo program for the FastUtf8 C++ class."
#error "Testcases for the C-style functions in fastutf8.cpp are available."
#error "See testutf8.cpp and its documentation."
#endif
#if defined(_WIN32)
#include ‹windows.h› // For SetConsoleOutputCP()
#endif // _WIN32
#include ‹iostream›
#include ‹cstdio›
#include ‹cstring›
#include ‹string›
#include ‹cmath›
#include ‹chrono›
#include "fastutf8.h"
using namespace FastUtf8;
int UniseriespFindTokenDemo(void)
{
// Define a pair of short Japanese buns and equivalent English sentences,
// plus a mix of the two.
FastUtf8::Uniseries sJapanesePart1 = u8"これがミスター・ロボットに秘密を話すとこうなるんだ。 ";
FastUtf8::Uniseries sEnglishPart1 =
u8"This is what happens when you tell Mr Robot a secret. ";
FastUtf8::Uniseries sJapanesePart2 = u8"ミスター・ロボットがどうもありがとうと言っています。 ";
FastUtf8::Uniseries sEnglishPart2 = u8"Mr Roboto says domo arigato.";
FastUtf8::Uniseries sMixedPart2 = u8"Mr Roboto says どうもありがとうございます。";
// Combine uniseries in the two languages.
FastUtf8::Uniseries sJapaneseSentences = sJapanesePart1 + sJapanesePart2;
FastUtf8::Uniseries sEnglishSentences = sEnglishPart1 + sEnglishPart2;
FastUtf8::Uniseries sMixedSentences = sJapanesePart1 + sMixedPart2;
// Define a token set with both the Latin period (.) and Japanese kuten (。).
FastUtf8::Uniseries sKutenSet = u8"。.";
// Define a search pattern with a space followed by a wildcard.
FastUtf8::Uniseries sSearchPattern = u8" *";
// Extract the second portion of the combined Japanese bun.
uint8_t *puzKuten = sJapaneseSentences.pFindToken(sKutenSet);
uint8_t *puzFirst = sJapaneseSentences.pFindWild(sSearchPattern, &puzKuten);
uint8_t *puzLast = sJapaneseSentences.pFindToken(puzFirst, sKutenSet);
FastUtf8::Uniseries sJapanesePart2a(puzFirst, puzLast);
std::cout ‹‹ std::endl ‹‹ " From this combined content..." ‹‹
std::endl ‹‹ " " ‹‹ sJapanesePart1 ‹‹
sJapanesePart2;
std::cout ‹‹ std::endl ‹‹ " ...extracted the second portion:" ‹‹
std::endl ‹‹" " ‹‹ sJapanesePart2a ‹‹ std::endl;
// Extract the second portion of the combined English sentences.
puzKuten = sEnglishSentences.pFindToken(sKutenSet);
puzFirst = sEnglishSentences.pFindWild(sSearchPattern, &puzKuten);
puzLast = sEnglishSentences.pFindToken(puzFirst, sKutenSet);
FastUtf8::Uniseries sEnglishPart2a(puzFirst, puzLast);
std::cout ‹‹ std::endl ‹‹ " From this combined content..." ‹‹
std::endl ‹‹ " " ‹‹ sEnglishPart1 ‹‹
sEnglishPart2;
std::cout ‹‹ std::endl ‹‹ " ...extracted the second portion:" ‹‹
std::endl ‹‹" " ‹‹ sEnglishPart2a ‹‹ std::endl;
// Extract the second portion of the mixed combination.
puzKuten = sMixedSentences.pFindToken(sKutenSet);
puzFirst = sMixedSentences.pFindWild(sSearchPattern, &puzKuten);
puzLast = sMixedSentences.pFindToken(puzFirst, sKutenSet);
FastUtf8::Uniseries sMixedPart2a(puzFirst, puzLast);
std::cout ‹‹ std::endl ‹‹ " From this combined content..." ‹‹
std::endl ‹‹ " " ‹‹ sMixedSentences;
std::cout ‹‹ std::endl ‹‹ " ...extracted the second portion:" ‹‹
std::endl ‹‹ " " ‹‹ sMixedPart2a ‹‹ std::endl;
return 0;
}
// Entry point for demo.
//
int main(void)
{
#if defined(_WIN32)
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
#endif
// Demo of search for any of a set of tokens.
std::cout ‹‹ "FastUtf8::Uniseries.pFindToken() demo" ‹‹ std::endl;
UniseriespFindTokenDemo();
return 0;
}
Uniseries::slice() methods
Range-Based Slice Methods
The index-driven range-based ::slice() method constructs a new Uniseries object from an existing one, making a deep copy of a portion of its content specified by the iFirst and iLast parameters.
Signature
Uniseries slice(const int iFirst, const int iLast = 0) const;
Parameters
[in] iFirst
An index of the beginning of the inbound content.
[in] iLast
An index of the end of the inbound content.
Discussion
Indexing is arranged in code point counts. The method operates by calling a *Slice*() function. The ::find() demo has example code that invokes ::slice().
If the last index value is less than the first index value, the returned object will comprise an empty string. If the indices are negative, indexing is done based on the end of the content; i.e., by counting backward from the end of the content to get the code points beginning at the first index relative to the end, and ending at the code point prior to the last index relative to the end. A negative first index (iFirst) value and zero last index (iLast) value fetches the last portion of the content, beginning -(iFirst) code points from its end.
The pointer-driven range-based ::slice() method constructs a new Uniseries object from an existing one, making a deep copy of a portion of its content specified by the pFirst and pLast parameters. The method does no pointer validation.
Signature
Uniseries slice(const uint8_t *pFirst, const uint8_t *pLast) const;
Parameters
[in] pFirst
A pointer to the beginning of the inbound content.
[in] pLast
A pointer to the end of the inbound content.
Discussion
To create a slice successfully, the method must be given pointers that each refer to the beginning of a UTF-8 code point, and both pointers must refer within the range of a single content buffer.
Range-based constructors
Each of the ::fromSlice() methods constructs a new Uniseries object from a range of UTF-8 content.
Signature
Uniseries& fromSlice(const uint8_t *pFirst, const uint8_t *pLast);
Uniseries& fromSlice(const char *pFirst, const char *pLast);
Parameters
[in] pFirst
A pointer to the beginning of the inbound content.
[in] pLast
A pointer to the end of the inbound content.
Discussion
To create a slice successfully, the method must be given pointers that each refer to the beginning of a UTF-8 code point, and both pointers must refer within the range of a single content buffer.
Uniseries concatenation operators
Concatenation of raw buffer content
The pointer-driven concatenation operators reallocate the content buffer and perform a deep copy of the additional content. The metadata is left as close as possible to the original metadata without falsifying it. Any length limit is adjusted to accommodate the added content.
Signature
Uniseries& operator+=(uint8_t *pInbound);
Uniseries& operator+=(char *pInbound);
Parameter
[in] pInbound
A pointer to the inbound buffer whose content is to be concatenated onto the this object’s content.
Discussion
Length-limited concatenation may well be the slowest of the Uniseries operations. Concatenation based on terminating nulls alone is much faster. These methods call the *ConcatenateUtf8() content concatenation functions. The FetchAuthorByTitleUsingFastUtf8Uniseries() function in the FastUtf8 overview has example code that invokes operator+=.
Concatenation of Uniseries content
The Uniseries-object-driven concatenation operators reallocate the content buffer and perform a deep copy of the additional content. The metadata is left as close as possible to the original metadata without falsifying it. Any length limit is adjusted to accommodate the added content.
Signature
Uniseries& operator+=(const Uniseries& that);
Uniseries operator+(const Uniseries& that);
Parameter
[in] that
A reference to a Uniseries object whose content is to be concatenated onto the this object’s content.
Discussion
Length-limited concatenation may well be the slowest of the Uniseries operations. These methods call the *ConcatenateUtf8() content concatenation functions.
Uniseries content separation methods
::pSeparate() methods returning objects
Each of these pointer-driven ::pSeparate() methods accepts a pointer to a buffer containing a tokenset and constructs a Uniseries object from a portion of the existing (this) object’s content. The portion is derived based on a search for any of the tokens in the set. The new Uniseries object encompasses the content “ahead of” a found token. The existing this object is modified to encompass any remaining content ”after” the token. Its content is modified such that a token is replaced with a null.
If the search can find no token, the method effectively copies the content to the new object – but it’s not a deep copy; the new object and existing object will share the content buffer. The method optionally trims white space from the new object’s content.
Signature
std::unique_ptr
bool bTrim = false);
std::unique_ptr
bool bTrim = false);
Parameters
[in] p?zTokenSet
A pointer to the beginning of the tokenset.
[in] bTrim
Discussion
Given a pointer to a buffer comprising one or more delimiter code points, these methods search the this object’s content for the first occurrence of any delimiter. They replace that code point in the content with a null terminator, including enough nulls to replace the entire code point, and return a pointer to any first delimited content, or nullptr if there is no content. The ::caseCompare() and ::pSeparate() demo with ASCII text has example code that invokes ::pSeparate().
These methods call one or another of the Separate*() content separation functions. They perform no UTF-8 validation other than null checking.
The tokenset search functionality for FastUtf8 checks from the starting location (for these ::pSeparate() methods, the beginning of the this object’s content) for the first occurrence of any token in the set. Short tokensets provide for best performance.
The Uniseries-object-driven tokenset-based ::pSeparate() method accepts a Uniseries-object containing a tokenset and constructs a Uniseries object from any first token-deimited portion found in the this object’s content.
Signature
std::unique_ptr
bool bTrim = false);
Parameters
[in] tokenSet
A Uniseries object whose content comprises a tokenset.
[in] bTrim
A flag indicating whether to remove white space code points from the content. If the flag is set, the returned object’s content will begin with the first non-white-space code point after a token, and any trailing white space code point(s) at the end of the content will be replaced with nulls. The flag is not set by default.
Discussion
Given a Uniseries object whose content comprises one or more delimiter code points, this method searches the this object’s content for the first occurrence of any delimiter. It replaces that code point in the content with a null terminator, including enough nulls to replace the entire code point, and returns a pointer to any first delimited content, or nullptr if there is no content. The ::caseCompare() and ::pSeparate() demo with ASCII text has example code that invokes ::pSeparate().
This method calls one or another of the Separate*() content separation functions. It performs no UTF-8 validation other than null checking.
The tokenset search functionality for FastUtf8 checks from the starting location (for this ::pSeparate() method, the beginning of the this object’s content) for the first occurrence of any token in the set. Short tokensets provide for best performance.
The character-driven token-based ::pSeparate() method accepts a single ASCII character as a token and constructs a Uniseries object from any first token-deimited portion found in the this object’s content.
Signature
std::unique_ptr
char cToken,
bool bTrim = false);
Parameters
[in] cToken
An ASCII character comprising a token.
[in] bTrim
A flag indicating whether to remove white space code points from the content. If the flag is set, the returned object’s content will begin with the first non-white-space code point after the token, and any trailing white space code point(s) at the end of the content will be replaced with nulls. The flag is not set by default.
::pSeparate() methods returning pointers
Pointer-returning ::pSeparate() overloads begin their tokenset search from an address within the this object’s content. The address is specified via the first parameter. The caller is responsible for ensuring that it refers within the content.
The address returned is the address of the first portion of delimited content. The this content subsequently refers to any portion of the orginal content that remains, beyond the token. This method modifies the object’s content by replacing tokens with nulls.Signature
uint8_t * pSeparate(uint8_t **ppContent,
const uint8_t *puzTokenSet,
bool bTrim = false);
uint8_t * pSeparate(uint8_t **ppContent,
const char *pszTokenSet,
bool bTrim = false);
uint8_t * pSeparate(uint8_t **ppContent,
const char cToken,
bool bTrim = false);
uint8_t * pSeparate(uint8_t **ppContent,
const Uniseries& tokenSet,
bool bTrim = false);
Parameters
Refer to the Parameters descriptions for the ::pSeparate() Methods Returning Objects (above).
Discussion
Given a pointer to UTF-8 content and a pointer to one or more delimiter code points, these methods search the content for the first occurrence of any delimiter. They replace that code point in the content with a null terminator, including enough nulls to replace the entire code point, and return a pointer to any first delimited content, or nullptr if there is no content.
These methods call one or another of the Separate*() content separation functions. They perform no UTF-8 validation other than null checking.
The tokenset search functionality for FastUtf8 checks from the starting location (for these pSeparate() methods, the location referenced by *ppContent) for the first occurrence of any token in the set. Short tokensets provide for best performance.
Example: ::caseCompare() and ::pSeparate() demo with ASCII text
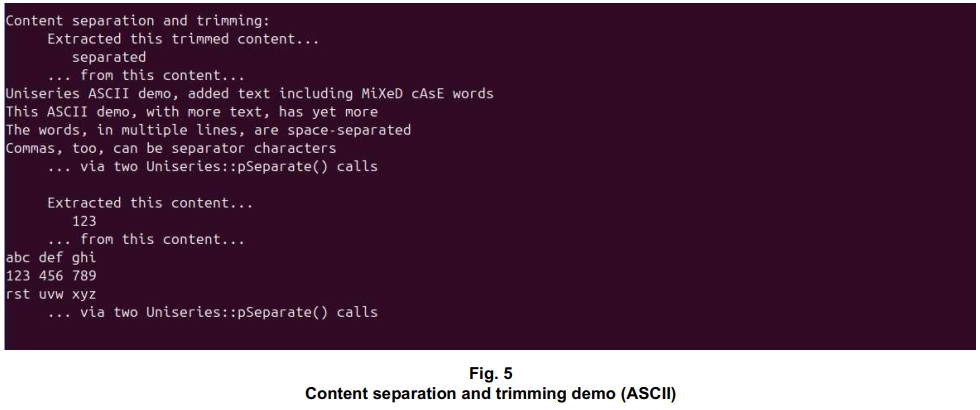
The AsciiUniseriesMultiFuncDemo() function is part of the ::caseCompare() and ::pSeparate() demo. Output from the "Content separation and trimming" portion of the demo program is shown in Fig. 5.
using namespace FastUtf8;
// Demonstrates this FastUtf8::Uniseries functionality for ASCII:
//
// Fast one-call whole content case folding (lowercasing);
// Case-insensitive whole content comparison;
// Case-insensitive partial content comparison and find (returning an index);
// Wildcard comparison, with / without case sensitivity;
// Content separation over a buffer that remains in place (speedy!); and
// Trimming of outboard white space.
//
int AsciiUniseriesMultiFuncDemo(void)
{
// Declarations of multilingual variants of "Uniseries ASCII demo."
Uniseries sDemo = "Uniseries ASCII demo";
// Case-folding demo.
std::cout ‹‹ "Case-folding (lowercasing) example:" ‹‹ std::endl;
// This first call is for UTF-8 compatibility. Can use strlen() for ASCII,
// as an alternative.
size_t sizeFolded = Uniseries::getSizeFolded(sDemo);
Uniseries sDemoFolded1 = Uniseries::getFolded(sDemo, sizeFolded);
Uniseries sDemoFolded2 = "uniseries ascii demo";
if (sDemoFolded1 == sDemoFolded2)
{
std::cout ‹‹ " Mixed case ASCII: " ‹‹
sDemo ‹‹ std::endl;
std::cout ‹‹ " Case-folded ASCII: " ‹‹
sDemoFolded1 ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of case-insensitive whole content comparison.
std::cout ‹‹ "Case-insensitive whole content comparison:" ‹‹ std::endl;
if (sDemo.caseCompare(sDemoFolded1))
{
std::cout ‹‹ " " ‹‹ sDemoFolded1 ‹‹ " matches " ‹‹
sDemo ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of case-insensitive partial content comparison.
std::cout ‹‹ "Case-insensitive partial content comparison:" ‹‹ std::endl;
Uniseries sAscii1 = sDemo + ", added text including MiXeD cAsE words";
sAscii1.setCaseInsensitive();
if (sAscii1.contains("mixed case"))
{
std::cout ‹‹ " This content..." ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ sAscii1 ‹‹ std::endl;
std::cout ‹‹ " ...contains the words..." ‹‹ std::endl;
std::cout ‹‹ " mixed case" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of case-sensitive and case-insensitive partial content lookup.
std::cout ‹‹ "Case-insensitive partial content lookup:" ‹‹ std::endl;
Uniseries sAscii2 = "This ASCII demo, with more text, has yet more";
Uniseries sAscii3 = "The words, in multiple lines, are space-separated ";
Uniseries sAscii4 = "Commas, too, can be separator characters";
Uniseries sAsciiCombo = sAscii1 + "\n" + sAscii2 + "\n" + sAscii3 +
"\n" + sAscii4;
// When we call ::find() on a Uniseries object that's set up for case-
// sensitive comparison, we won't find an all-lowercase portion unless
// there's an all-lowercase match.
std::cout ‹‹ " -- Setting case sensitivity to true -- " ‹‹ std::endl;
sAsciiCombo.setCaseSensitivity(true);
int iCommas1 = sAsciiCombo.find(sAscii4);
int iCommas2 = sAsciiCombo.find("commas");
if (iCommas1 > 0)
{
std::cout ‹‹ " " ‹‹ sAscii4 ‹‹ " has index " ‹‹
iCommas1 ‹‹ std::endl;
}
// Here, "Commas" fails to match "commas".
if (iCommas2 > 0)
{
std::cout ‹‹ " " ‹‹ "\"commas\"" ‹‹ " has index " ‹‹
iCommas2 ‹‹ std::endl;
}
else
{
std::cout ‹‹
" Cannot find \"commas\"" ‹‹
std::endl;
}
// By switching case sensitivity off, we change the default behavior for
// the comparison methods including ::find().
std::cout ‹‹ " -- Setting case sensitivity to false -- " ‹‹ std::endl;
sAsciiCombo.setCaseSensitivity(false);
// Now that we've made that change, "Commas" matches "commas".
iCommas2 = sAsciiCombo.find("commas");
if (iCommas2 > 0)
{
std::cout ‹‹ " " ‹‹ "\"commas\"" ‹‹ " has index " ‹‹
iCommas2 ‹‹ std::endl;
}
else
{
std::cout ‹‹
" Cannot find \"commas\"" ‹‹
std::endl;
}
std::cout ‹‹ std::endl;
// Matching wildcards demo.
std::cout ‹‹ "Matching wildcards:" ‹‹ std::endl;
if (sAsciiCombo.caseCompareWild("*ascii DEMO? WITH more*"))
{
std::cout ‹‹
" This content..." ‹‹ std::endl ‹‹ sAsciiCombo ‹‹ std::endl;
std::cout ‹‹
" ...matches the wildcarded and inverse-cased sequence..." ‹‹
std::endl;
std::cout ‹‹ " *ascii DEMO? WITH more*" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of content separation and trimming.
std::cout ‹‹ "Content separation and trimming:" ‹‹ std::endl;
// We'll extract "separated" from the four lines of text we've created.
// First we duplicate the Uniseries object. The pSeparate() calls modify
// the content by replacing separator tokens with null terminators. The
// tokens are the code points (in this case, ASCII characters) passed to
// Uniseries::pSeparate().
Uniseries sComboDup = sAsciiCombo;
// Separate the content by '-' characters. For this demo, we capture
// but ignore the first portion. (The compiler may warn us about that.)
// The pSeparate() method relies on std::make_unique‹FastUtf8::Uniseries›
// to get the pointer that it returns.
std::unique_ptr‹FastUtf8::Uniseries› psComboPart1 =
sComboDup.pSeparate("-");
// Separate the second portion by newline characters.
std::unique_ptr‹FastUtf8::Uniseries› psComboPart2 =
sComboDup.pSeparate("\n", /* bTrim = */ true);
if (*psComboPart2 == "separated") // note: without the trailing space
{
std::cout ‹‹ " Extracted this trimmed content..." ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ *psComboPart2 ‹‹ std::endl;
std::cout ‹‹ " ... from this content..." ‹‹
std::endl ‹‹ sAsciiCombo ‹‹ std::endl;
std::cout ‹‹ " ... via two Uniseries::pSeparate() calls" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Another example.
// We'll find a numeric sequence in text separated by spaces and lines.
Uniseries s123 = "123";
Uniseries sTwoSeparatorCombo = "abc def ghi\n123 456 789\nrst uvw xyz";
// We duplicate the Uniseries object like we did previously.
sComboDup = sTwoSeparatorCombo;
// Separate the text by newline characters only, then separate the second
// portion by either newline or space characters. The content buffers
// previously allocated for the reused objects get deallocated here. The
// Uniseries objects otherwise remain allocated until they go out of scope.
psComboPart1 = sComboDup.pSeparate("\n");
psComboPart2 = sComboDup.pSeparate(" \n");
if (*psComboPart2 == s123)
{
std::cout ‹‹ " Extracted this content..." ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ *psComboPart2 ‹‹ std::endl;
std::cout ‹‹ " ... from this content..." ‹‹
std::endl ‹‹ sTwoSeparatorCombo ‹‹ std::endl;
std::cout ‹‹ " ... via two Uniseries::pSeparate() calls" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
return 0;
}
Further Uniseries tokenset search methods
::pFindToken() methods for raw buffer content
Each ::pFindToken() content comparison method searches the this object’s content for any token within a set of tokens. The tokenset search begins from an address, within the content, specified via the first parameter. The caller is responsible for ensuring that the address is within the content. If a token is found, the method returns a pointer to the code point immediately prior to it. Otherwise, the method returns nullptr.
Methods that accept a pointer to a tokenset buffer:
Signature
uint8_t * pFindToken(
const uint8_t *pContent,
const uint8_t *pTokenSet) const;
uint8_t * pFindToken(
const char *pContent,
const char *pTokenSet) const;
Parameters
[in] pContent
A pointer to a content buffer in which to search for tokens.
[in] pTokenSet
A pointer to a buffer comprising a tokenset.
Methods that accept a Uniseries object comprising the tokenset buffer:
Signature
uint8_t * pFindToken(
const uint8_t *pContent,
const Uniseries& sTokenSet) const;
uint8_t * pFindToken(
const char *pContent,
const Uniseries& sTokenSet) const;
Parameters
[in] pContent
A pointer to a content buffer in which to search for tokens.
[in] sTokenSet
A reference to a Uniseries object whose content comprises a tokenset.
Discussion
Given a pointer to UTF-8 content and a pointer to a set of one or more delimiter code points, these methods search the content for the first occurrence of any delimiter. They bypass any initial delimiters at the content’s start. In case a delimiter is found within the subsequent content, they return a pointer to the code point immediately prior to it. They return nullptr if no delimiter is found.
The tokenset search functionality for FastUtf8 checks from the starting location (for these pFindToken() methods, the location referenced by pContent) for the first occurrence of any token in the set. Short tokensets provide for best performance. These methods call one or another of the Token*Find*() tokenset search functions. The FetchAuthorByTitleUsingFastUtf8Uniseries() function in the FastUtf8 overview has example code that invokes ::pFindToken().
::pFindToken() methods for Uniseries content
Single-parameter overloads of pFindToken() begin their search at the top of the this content.
Methods that accept a pointer to a tokenset buffer:
Signature
uint8_t * pFindToken(
const uint8_t *pTokenSet) const;
uint8_t * pFindToken(
const char *pTokenSet) const;
Parameter
[in] pTokenSet
A pointer to a buffer comprising a tokenset.
Method that accepts a Uniseries object comprising the tokenset buffer:
Signature
uint8_t * pFindToken(
const Uniseries& sTokenSet) const;
Parameter
[in] pTokenSet
A reference to a Uniseries object whose content comprises a tokenset.
Discussion
Given one or more delimiter code points, these methods search the this object’s content for the first occurrence of any delimiter. They bypass any initial delimiters at the content’s start. In case a delimiter is found within the subsequent content, they return a pointer to the code point immediately prior to it. They return nullptr if no delimiter is found.
The tokenset search functionality for FastUtf8 checks from the starting location (for these pFindToken() methods, the beginning of the this object’s content) for the first occurrence of any token in the set. Short tokensets provide for best performance. These methods call one or another of the Token*Find*() tokenset search functions. The FetchAuthorByTitleUsingFastUtf8Uniseries() function in the FastUtf8 overview has example code that invokes ::pFindToken().
Uniseries iterator
The methods within the iterator class apply to individual code points within the content buffer of a Uniseries object.
The iterator constructor provides for a buffer comprising a range of contiguous code points.
Signature
Iterator(uint8_t *pSeries, uint8_t *pSeriesBase,
uint8_t *pSeriesLimit, Uniseries& series);
Discussion
The iterator is designed for working with a Uniseries object or with a UTF-8 content slice. The base and limit parameters determine the locations where iteration is to begin and end. For iterating over a slice of content, these locations may be different from the base and limit of a Uniseries object containing the slice.
Basic dereference operators include operator* and operator->.
Signature
reference operator*() const;
pointer operator->() const;
Discussion
The * dereference operator returns a uint32_t value representing a UTF-8 code point. The code point’s substantive byte(s) occupy the value’s least significant byte(s). The value can be used for comparison with other code points represented similarly.
The -> dereference operator is intended to point to a UTF-8 code point in memory regardless of its alignment.
The prefix and postfix increment operators each advance the iterator by a code point.
Signature
Iterator& operator++();
Iterator operator++(int);
The prefix and postfix decrement operators each backtrack the iterator by a code point.
Signature
Iterator& operator--();
Iterator operator--(int);
These are equality operators for individual code points in content.
Signature
bool operator==(const Iterator& thatItr);
bool operator!=(const Iterator& thatItr);
The begin() iterator references the first code point in Uniseries content. The end() iterator refers immediately past the last code point.
Signature
Iterator begin();
Iterator end();
Example: Iterator demo
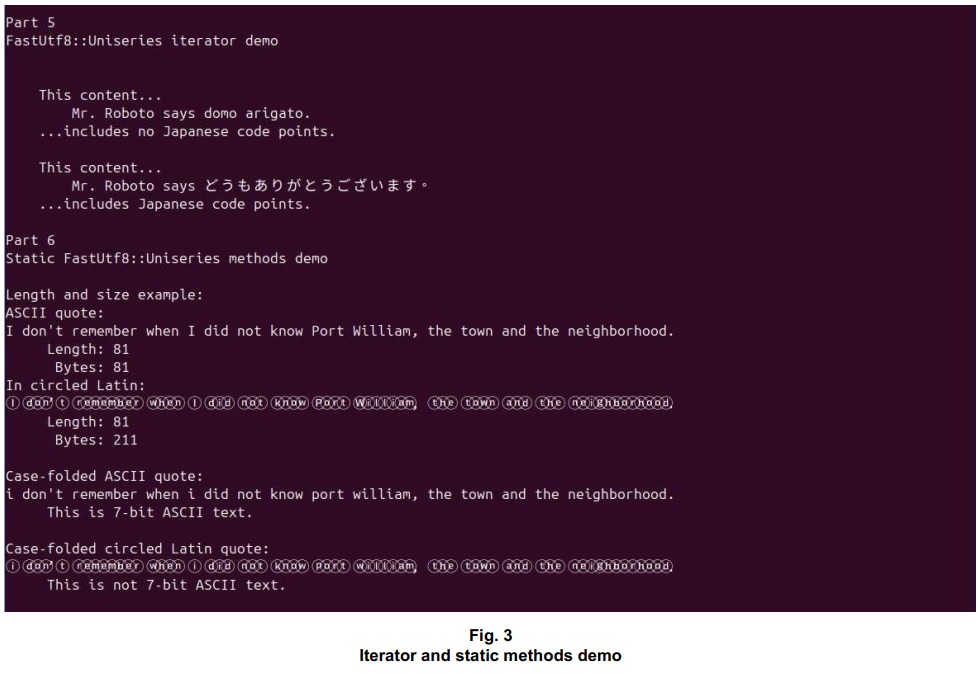
The UniseriesIteratorDemo() and ContainsJapanese() functions are part of the iterator demo (IteratorDemo.cpp). Output is shown in Fig. 3.
// Returns true if the query content includes Japanese code points, and false
// if it doesn't.
bool ContainsJapanese(FastUtf8::Uniseries sQuery)
{
bool bRetVal = false;
for (FastUtf8::Uniseries::Iterator itr = sQuery.begin();
itr != sQuery.end(); ++itr)
{
uint32_t n = *itr; // UTF-8 code point in sQuery
if ((n >= 0xE38180 && n ‹= 0xE383BF) || // Hiragana/Katakana range
(n >= 0xE4B880 && n ‹= 0xE9BFBF) || // CJK unified ideographs
(n >= 0xEFBDA5 && n ‹= 0xEFBE9F)) // Shift-JIS encodings
{
bRetVal = true;
}
}
return bRetVal;
}
int UniseriesIteratorDemo(void)
{
FastUtf8::Uniseries sEnglish = u8"Mr. Roboto says domo arigato.";
FastUtf8::Uniseries sMixed = u8"Mr. Roboto says どうもありがとうございます。";
if (!ContainsJapanese(sEnglish))
{
std::cout ‹‹ std::endl ‹‹ " This content..." ‹‹ std::endl ‹‹
" " ‹‹ sEnglish;
std::cout ‹‹ std::endl ‹‹ " ...includes no Japanese code points." ‹‹
std::endl;
}
if (ContainsJapanese(sMixed))
{
std::cout ‹‹ std::endl ‹‹ " This content..." ‹‹ std::endl ‹‹
" " ‹‹ sMixed;
std::cout ‹‹ std::endl ‹‹ " ...includes Japanese code points." ‹‹
std::endl;
}
return 0;
}
Uniseries get and set methods
::getContent() methods
These are basic getter / setter methods for whole content and its metadata. This first one gets a pointer to the this object’s content buffer. The static methods demo has example code.
Signature
uint8_t * getContent(void) const;
These ::getContent() methods make a deep copy of the whole content. The developer is responsible for ensuring that the buffer receiving the content is sufficient.
Signature
void getContent(uint8_t *pOutbound);
void getContent(char *pOutbound);
::getMetadata() method
This method returns a uint64_t value comprising the this object’s metadata.
Signature
uint64_t getMetadata(void) const;
::is7Bit() methods
Is the inbound content all 7-bit ASCII characters? If so, the ::is7Bit() method sets the IS_7BIT_CHAR_STRING flag for this and returns true. Otherwise, the method clears that flag and returns false. To get its result, it calls the Is7BitUtf8() function. The static methods demo has example code that invokes ::is7Bit().
Signature
static bool is7Bit(const uint8_t *pInbound);
static bool is7Bit(const char *pInbound);
bool is7Bit(void);
static bool is7Bit(const Uniseries& that);
Methods for setting case sensitivity
The IS_CASE_INSENSITIVE flag for this can be set via any of the next methods.
Signature
void setCaseSensitivity(bool bCaseSensitive);
void setCaseInsensitive(void);
void clearCaseInsensitive(void);
Methods for setting the length limit
The length limit for this can be set via any of the next methods. Selecting a nonzero length limit also sets the IS_LENGTH_LIMITED flag.
Signature
void setLengthLimit(int lenContent);
void setLengthLimited(void);
void clearLengthLimited(void);
::getLength() methods
Given a byte count, this method returns the corresponding count of code points between the beginning of the this object’s content and the last complete code point encompassing the given number of bytes. To get its result, it calls the LenSizeOfUtf8() function. The ::getLength() methods perform no UTF-8 validation other than null checking. .
Signature
int getLength(const size_t sizeContent);
This method returns the object’s current content length as a count of its code points. To get its result, it calls the CodePointCountUtf8() function.
Signature
These static ::getLength() methods return the length of the inbound content as a count of its code points, which they get by calling the CodePointCountUtf8() function. The static methods demo has example code.
Signature
static int getLength(const uint8_t *pInbound);
static int getLength(const char *pInbound);
static int getLength(const Uniseries& that);
::getSize() methods
This ::getSize() method returns the this object’s content’s size in bytes. The ::getSize() methods get their findings by calling one or another of the SizeOf*Utf8() functions. They perform no UTF-8 validation other than null checking.
Signature
These static ::getSize() implementations return the size of the inbound content, in bytes. The static methods demo has example code.
Signature
static size_t getSize(const uint8_t *pInbound);
static size_t getSize(const char *pInbound);
static size_t getSize(const Uniseries& that);
Uniseries case folding methods
The static ::getSizeFolded() methods returns the number of bytes needed to store the inbound content after case folding. This size may be larger or smaller than the unfolded size. The nonstatic method determines the folded size for the this object. These methods call one or another of the SizeOfFolded*Utf8() functions. The static methods demo has example code that invokes ::getSizeFolded().
Signature
static size_t getSizeFolded(const uint8_t *pInbound);
static size_t getSizeFolded(const char *pInbound);
size_t getSizeFolded(void) const;
static size_t getSizeFolded(const Uniseries& that);
::getFolded() methods
Each ::getFolded() method makes a deep copy of the whole content after case folding. The developer is responsible for ensuring that the buffer receiving the content is sufficient. The size needed for folded content may be greater or less than the original content’s size, in bytes. To predetermine the needed size, invoke the getSizeFolded() method (described immediately above).
Signature
static Uniseries getFolded(uint8_t *pOutbound, size_t sizeOutbound);
static Uniseries getFolded(char *pOutbound, size_t sizeOutbound);
Uniseries getFolded(void) const;
static Uniseries getFolded(const Uniseries& that);
static Uniseries getFolded(const Uniseries& that, size_t sizeOutbound);
Discussion
These methods construct Uniseries() objects whose content is case-folded. Among these methods, the first two accept pointers to buffers containing UTF-8 content, the middle one has void input and operates on the this object’s content, and the last two accept a given Uniseries() object and operate on its content. The content of a resulting Uniseries() object can be compared with other case-folded UTF-8 content for case-insensitive matching. These methods call the ToFoldedUtf8() function.
Example: Static methods demo
The UniseriesStaticMethodsDemo() function is part of the static methods demo (StaticMethodsDemo.cpp). The demo program’s output is shown in Fig. 3.
// Demonstrates the static FastUtf8::Uniseries methods:
//
// getLength() Get content length in code points.
// getSize() Get content size in bytes.
// getSizeFolded() Get content size anticipated after case folding.
// getFolded() Get case-folded content.
// is7Bit() Is the current content all 7-bit ASCII characters?
//
// The static methods are provided for ease of access without requiring a
// Uniseries instance.
//
int UniseriesStaticMethodsDemo(void)
{
// Declare an ASCII string and a circled Latin series.
char szBerryQuote[88] =
"I don't remember when I did not know Port William, the town and the neighborhood.";
uint8_t uzCircledLatinQuote[353] =
u8"Ⓘ ⓓⓞⓝ’ⓣ ⓡⓔⓜⓔⓜⓑⓔⓡ ⓦⓗⓔⓝ Ⓘ ⓓⓘⓓ ⓝⓞⓣ ⓚⓝⓞⓦ Ⓟⓞⓡⓣ Ⓦⓘⓛⓛⓘⓐⓜ, ⓣⓗⓔ ⓣⓞⓦⓝ ⓐⓝⓓ ⓣⓗⓔ ⓝⓔⓘⓖⓗⓑⓞⓡⓗⓞⓞⓓ.";
// Demonstrate methods that get the length and size of each.
std::cout ‹‹ "Length and size example:" ‹‹ std::endl;
int lenBerry = FastUtf8::Uniseries::getLength(szBerryQuote);
int lenCircled = FastUtf8::Uniseries::getLength(uzCircledLatinQuote);
size_t sizeBerry = FastUtf8::Uniseries::getSize(szBerryQuote);
size_t sizeCircled = FastUtf8::Uniseries::getSize(uzCircledLatinQuote);
std::cout ‹‹ "ASCII quote:" ‹‹ std::endl ‹‹ szBerryQuote ‹‹ std::endl;
std::cout ‹‹ " Length: " ‹‹ lenBerry ‹‹ std::endl;
std::cout ‹‹ " Bytes: " ‹‹ sizeBerry ‹‹ std::endl ‹‹ std::endl;
std::cout ‹‹ "In circled Latin:" ‹‹ std::endl ‹‹ uzCircledLatinQuote ‹‹
std::endl;
std::cout ‹‹ " Length: " ‹‹ lenCircled ‹‹ std::endl;
std::cout ‹‹ " Bytes: " ‹‹ sizeCircled ‹‹ std::endl ‹‹ std::endl;
// Allocate buffers sufficient for the case-folded ASCII and circled Latin
// content.
size_t sizeFoldedBerry = FastUtf8::Uniseries::getSizeFolded(szBerryQuote);
size_t sizeFoldedCircled = FastUtf8::Uniseries::getSizeFolded(
uzCircledLatinQuote);
char *pszFoldedBerry =
reinterpret_cast‹char *› (std::malloc(sizeFoldedBerry));
uint8_t *puzFoldedCircled =
reinterpret_cast‹uint8_t *› (std::malloc(sizeFoldedCircled));
// Place the case-folded ASCII and circled Latin content into the buffers.
if (pszFoldedBerry && puzFoldedCircled)
{
Uniseries sFoldedBerry = FastUtf8::Uniseries::getFolded(szBerryQuote);
Uniseries sFoldedCircled = FastUtf8::Uniseries::getFolded(
uzCircledLatinQuote);
strncpy(pszFoldedBerry,
reinterpret_cast‹char *› (sFoldedBerry.getContent()),
sizeFoldedBerry);
strncpy(reinterpret_cast‹char *› (puzFoldedCircled),
reinterpret_cast‹char *› (sFoldedCircled.getContent()),
sizeFoldedCircled);
// Show the case-folded content, and demonstrate 7-bit ASCII check.
std::cout ‹‹ "Case-folded ASCII quote:" ‹‹ std::endl ‹‹
pszFoldedBerry ‹‹ std::endl;
if (FastUtf8::Uniseries::is7Bit(pszFoldedBerry))
{
std::cout ‹‹ " This is 7-bit ASCII text." ‹‹ std::endl;
}
else
{
std::cout ‹‹ " This is not 7-bit ASCII text." ‹‹ std::endl;
}
std::cout ‹‹ std::endl ‹‹
"Case-folded circled Latin quote:" ‹‹ std::endl ‹‹
puzFoldedCircled ‹‹ std::endl;
if (FastUtf8::Uniseries::is7Bit(puzFoldedCircled))
{
std::cout ‹‹ " This is 7-bit ASCII text." ‹‹ std::endl;
}
else
{
std::cout ‹‹ " This is not 7-bit ASCII text." ‹‹ std::endl;
}
free(pszFoldedBerry);
free(puzFoldedCircled);
}
return 0;
}
Whole Uniseries comparison operators and methods
Equality operators
These are equality operators for whole content comparison. They call one or another of the *CompareUtf8() functions or str*cmp() functions. The ::caseCompare() and ::pSeparate() demo with ASCII text has example code that invokes operator==.
Signature
bool operator==(const Uniseries& that) const;
bool operator!=(const Uniseries& that) const;
::caseCompare() methods
The caseCompare() method is identical to the equality operator but strictly case-insensitive; it doesn’t check the IS_CASE_INSENSITIVE flag. It calls one or another of the *CaseCompareUtf8() functions or str*casecmp() functions. The ::caseCompare() and ::pSeparate() demo with ASCII text has example code that invokes ::caseCompare().
Signature
bool caseCompare(const uint8_t *pInbound) const;
bool caseCompare(const char *pInbound) const;
bool caseCompare(const Uniseries& that) const;
Comparison operator for pointer == object
This Uniseries comparison operator applies for pointer == object.
Signature
bool operator==(const Uniseries* puSeries, const Uniseries& uSeries);
Comparison pperator for object == pointer
This Uniseries comparison operator applies for object == pointer.
Signature
bool operator==(const Uniseries& uSeries, const Uniseries* puSeries);
Uniseries() partial content comparison methods
::contains() methods for raw buffer content
The ::contains() partial content comparison methods for inbound buffer content return true if the this object’s content contains the inbound content, and false otherwise.
Signature
bool contains(const uint8_t *pInbound) const;
bool contains(const char *pInbound) const;
Parameter
[in] pInbound
A pointer to the beginning of the inbound content.
Discussion
This partial content comparison method is essentially a full-text search that returns a Boolean result: the UTF-8 equivalent of the classic ASCII “if (strstr())” logic that was based around the C standard library. The difference with FastUtf8 is this: where the if statement adds a little complexity over and above the full-text strstr() search, the ::contains() method eliminates the overhead of determining an index to be returned. If you need an index or pointer, you can look it up using the ::find() or ::pFind() method, respectively.
The ::contains() partial content comparison methods call one or another of the *Find*() functions or the strstr() function. The ::caseCompare() and ::pSeparate() demo with UTF-8 content has example code that invokes ::contains().
This ASCII-character-driven ::contains() partial content comparison method returns true if the this object’s content contains the inbound ASCII character, and false otherwise.
Signature
bool contains(const char cInbound) const;
Parameter
[in] cInbound
A character to be matched against each code point of this.
Discussion
Refer to the Discussion for the first pair of ::contains() methods, above.
::contains() method for Uniseries content
This partial content comparison method returns true if the this object‘s content contains the that object‘s content, and false otherwise.
Signature
bool contains(const FastUtf8::Uniseries& that) const;
Discussion
Refer to the Discussion for the first pair of ::contains() methods, above.
::find() methods for raw buffer content
The ::find() partial content comparison method for inbound buffer content returns an index of the inbound content within the this object’s content – that is, a count of the code points between the beginning of this content and any first match – or a negative return value (-1) in case that content isn’t found.
Signature
int find(const uint8_t *pInbound) const;
int find(const char *pInbound) const;
Discussion
This partial content comparison method is essentially a full-text search that returns an index of any first occurrence of the inbound content. To get a Boolean result as to whether this includes the inbound content, call the ::contains() method rather than the ::find() method. Refer to the Discussion for the first pair of ::contains() methods, above. The ::caseCompare() and ::pSeparate() demo with ASCII text has example code that invokes ::find().
This ASCII-character-driven ::find() partial content comparison method returns an index of the inbound ASCII character within the this object’s content – that is, a count of the code points between the beginning of this content and any first match – or a negative return value (-1) in case the character is not found.
Signature
int find(const char cInbound) const;
Discussion
This partial content comparison method is essentially a full-text search that returns an index of any first occurrence of a character. To get a Boolean result as to whether this includes the character, call the ::contains() method rather than the ::find() method.
::find() method for Uniseries content
This partial content comparison method returns an index of the that object’s content within the this object’s content – that is, a count of the code points between the beginning of this content and any first match – or a negative return value (-1) in case that content is not found.
Signature
int find(const FastUtf8::Uniseries& that) const;
Discussion
This partial content comparison method is essentially a full-text search that returns an index of any first occurrence of that within this. To get a Boolean result as to whether this includes the inbound content, call the ::contains() method rather than the ::find() method.
Example: ::find() demo with UTF-8 content
The Utf8UniseriesDemo() function is part of the fundamentals demo (FundamentalsDemo.cpp). Output from the demo program is shown in Fig. 2.
// This code is similar to the above AsciiUniseriesDemo() code but with
// Japanese content.
//
int Utf8UniseriesDemo(void)
{
// 1. Creation and Concatenation
Uniseries s1 = "こんにちは";
Uniseries s2 = "は世界";
// Using + operator
Uniseries s3 = s1 + "、" + s2 + "!"; // "Hello, World!"
s3 = s3 + " いらっしゃいませ。"; // "Hello, World! Welcome."
std::cout << "Concatenated (連結済み): " << s3 << std::endl;
// 2. Substring (Position, Length)
// Extract "World"
Uniseries sub = s3.slice(/* iFirst = */ 7, /* iLast = */ 12);
std::cout << "Substring (部分文字列): " << sub << std::endl;
// 3. Substring Find
int iFound = s3.find("いらっしゃいませ");
if (iFound != -1)
{
std::cout << "\"いらっしゃいませ\" found at (発見場所): " << iFound << std::endl;
}
// 4. Whole String Comparison
Uniseries s4 = "こんにちは、は世界! いらっしゃいませ。";
if (s3 == s4)
{
std::cout << "Strings are equal (文字列は等しい)。" << std::endl;
}
// 5. Separate (Splitting by code point)
int iCommaPos = s3.find("、");
if (iCommaPos != -1)
{
Uniseries sFirstPart = s3.slice(0, iCommaPos);
Uniseries sSecondPart = s3.slice(iCommaPos + 2); // Skip ", "
std::cout << "Separated (分離済み): \"" << sFirstPart << "\" and \"" <<
sSecondPart << "\"" << std::endl;
}
return 0;
}
::pFind() methods for raw buffer content
The ::pFind() partial content comparison methods for inbound buffer content return a pointer to the location of a match for the inbound content within the this object’s content – that is, a pointer to the beginning of any first match within this – or a nullptr return value in case the content is not found. The optional pFirst parameter refers to a location, in the this content, to begin seeking a match. Each method updates the optional *ppLast parameter to return the ending location of any first match within this.
Signature
uint8_t * pFind(const uint8_t *pSearchContent,
const uint8_t *pFirst = nullptr,
uint8_t **ppLast = nullptr) const;
uint8_t * pFind(const char *pSearchContent,
const char *pFirst = nullptr,
uint8_t **ppLast = nullptr) const;
Parameters
[in] pSearchContent
Needle.
[in, optional] pFirst
Beginning location.
[out, optional] ppLast
Returned location where match ends.
Discussion
Based on the pFirst parameter, which refers to a location in the this object’s content, given a pointer to a prospectively matching portion of content – i.e., what may be a substring – the method returns a pointer to any first matching sequence within the larger content. It returns nullptr and sets the optional *ppLast pointer (if it’s provided) to nullptr if no match is found.
In case no pFirst parameter is specified, the method begins the search for a match from the beginning of the this content.
Like the other Uniseries partial content comparison methods, the pFind() methods call one or another of the *Find*() functions or the strstr() function. The ::pFind() demo has example code that invokes ::pFind().
The ASCII-character-driven ::pFind() partial content comparison method returns a pointer to the location of the inbound character within the this object’s content – that is, a pointer to the beginning of any first match within this – or a nullptr return value in case that content is not found. The optional pFirst parameter refers to a location, in the this content, to begin seeking a match. The method updates the optional *ppLast parameter to return the ending location of any first match within this.
Signature
uint8_t * pFind(
const char cInbound,
const uint8_t *pFirst = nullptr,
uint8_t **ppLast = nullptr) const;
Parameters
[in] pSearchContent
Single ASCII character needle.
[in, optional] pFirst
Beginning location.
[out, optional] ppLast
Returned location where match ends.
Discussion
Based on the pFirst parameter, which refers to a location in the this object’s content, given a single ASCII character, the method returns a pointer to any first occurrence of the character within the content. It returns nullptr and sets the optional *ppLast pointer (if it is provided) to nullptr if no match is found.
In case no pFirst parameter is specified, the method begins the search for the character from the beginning of the this content.
::pFind() method for Uniseries content
This pFind() partial content comparison method returns a pointer to any first occurrence of the that object’s content within the this object’s content, or nullptr in case that content is not found.
Signature
uint8_t * pFind(const FastUtf8::Uniseries& that,
const uint8_t *pFirst = nullptr,
uint8_t **ppLast = nullptr) const;
Parameters
[in] pSearchContent
Object containing needle.
[in, optional] pFirst
Beginning location.
[out, optional] ppLast
Returned location where match ends.
Discussion
Refer to the Discussion for the first pair of ::pFind() methods, above.
::caseContains() methods for raw buffer content
The ::caseContains() case-insensitive partial content comparison methods for inbound buffer content return true if the this object’s content contains the inbound content, and false otherwise. It disregards the IS_CASE_INSENSITIVE flag.
Signature
bool caseContains(const uint8_t *pInbound) const;
bool caseContains(const char *pInbound) const;
Parameter
[in] pInbound
A pointer to the beginning of the inbound content.
Discussion
Refer to the Discussion for the ::contains() methods for raw buffer content.
::caseContains() method for Uniseries content
This case-insensitive partial content comparison method returns true if the this object‘s content contains the that object‘s content, and false otherwise. It disregards the IS_CASE_INSENSITIVE flag.
Signature
bool caseContains(const FastUtf8::Uniseries& that) const;
Discussion
Refer to the Discussion for the ::contains() method for Uniseries content.
::caseFind() methods for raw buffer content
The ::caseFind() case-insensitive partial content comparison method for inbound buffer content returns an index of the inbound content within the this object’s content – that is, a count of the code points between the beginning of this content and any first match – or a negative return value (-1) in case that content is not found. It disregards the IS_CASE_INSENSITIVE flag.
Signature
int caseFind(const uint8_t *pInbound) const;
int caseFind(const char *pInbound) const;
Discussion
Refer to the Discussion for the ::find() methods for raw buffer content.
::caseFind() method for Uniseries content
This case-insensitive partial content comparison method returns an index of the that object’s content within the this object’s content – that is, a count of the code points between the beginning of this content and any first match – or a negative return value (-1) in case that content is not found. It disregards the IS_CASE_INSENSITIVE flag.
Signature
int caseFind(const FastUtf8::Uniseries& that) const;
Discussion
Refer to the Discussion for the ::find() method for Uniseries content.
::casepFind() methods for raw buffer content
The ::casepFind() case-insensitive partial content comparison methods for inbound buffer content return a pointer to the location of a match on the inbound content within the this object’s content – that is, a pointer to the beginning of any first match within this – or a nullptr return value in case that content is not found. The optional pFirst parameter refers to a location, in the this content, to begin seeking a match. Each method updates the optional *ppLast parameter to return the ending location of any first match within this. These methods disregard the IS_CASE_INSENSITIVE flag.
Signature
uint8_t * casepFind(const uint8_t *pSearchContent,
const uint8_t *pFirst = nullptr,
uint8_t **ppLast = nullptr) const;
uint8_t * casepFind(const char *pSearchContent,
const char *pFirst = nullptr,
uint8_t **ppLast = nullptr) const;
Parameters
[in] pSearchContent
Needle.
[in, optional] pFirst
Beginning location.
Returned location where match ends.
Discussion
Refer to the Discussion for the ::pFind() methods.
::casepFind() method for Uniseries content
This casepFind() case-insensitive partial content comparison method returns a pointer to any first occurrence of the that object’s content within the this object’s content, or nullptr in case that content is not found. It disregards the IS_CASE_INSENSITIVE flag.
Signature
uint8_t * casepFind(const FastUtf8::Uniseries& that,
const uint8_t *pFirst = nullptr,
uint8_t **ppLast = nullptr) const;
Parameters
[in] pSearchContent
Object containing needle .
[in, optional] pFirst
Beginning location.
[out, optional] ppLast
Returned location where match ends.
Discussion
Refer to the Discussion for the ::pFind() method.
Example: ::pFind() demo with ASCII content
The AsciiUniseriespFindMute() function is invoked for timing comparisons as explained in the FastUtf8 overview. The function is part of the fundamentals demo (FundamentalsDemo.cpp). Output showing timing comparisons is shown in the overview’s Fig. 8.
int AsciiUniseriespFindMute(void)
{
// 1. Creation and Concatenation
Uniseries s1 = "Hello";
Uniseries s2 = "World";
// Using + operator
Uniseries s3 = s1 + ", " + s2 + "!"; // "Hello, World!"
s3 = s3 + " Welcome."; // "Hello, World! Welcome."
// 2. Substring (Position, Length)
// Extract "World! Welcome."
Uniseries sub = s3.slice(/* iFirst = */ 7, /* iLast = */ 22);
if (sub == s1)
{
return 1;
}
// 3. Substring Find
uint8_t *pFound = s3.pFind("Welcome");
if (!pFound)
{
return 1;
}
// 4. Whole String Comparison
Uniseries s4 = "Hello, World! Welcome.";
if (s3 != s4)
{
return 1;
}
// 5. Separate (Splitting by character)
uint8_t *pFirstPart = s3.pFind(',');
if (!std::strcmp(
reinterpret_cast‹char *› (const_cast‹uint8_t *› (pFirstPart)),
reinterpret_cast‹char *› (const_cast‹uint8_t *› (s3.getContent()))))
{
return 1; // "Hello" != " World! Welcome."
}
return 0;
}
Uniseries() methods for matching wildcards
::wildCompare() methods
The ::wildCompare() methods provide for wildcard-based content comparison. The this content is the content that may include the ‘*’ or ‘?’ wildcards.
Signature
bool wildCompare(const uint8_t *pTame) const;
bool wildCompare(const char *pTame) const;
bool wildCompare(const FastUtf8::Uniseries& tame) const;
Parameter
The methods accept either a pointer to an inbound buffer or a reference to a Uniseries object. Each method treats the this content as the content that may have wildcards, and the inbound content as content without wildcards.
Discussion
These methods compare UTF-8 content, matching wildcards. They accept ‘?’ as a single-code-point wildcard. For each ‘*’ wildcard, a ::wildCompare() method seeks out a matching sequence of any code points beyond it. It otherwise compares the content a code point at a time. It performs these operations by calling one or another of the Wild*CompareUtf8() functions.
The case-insensitive code for matching wildcards is quite similar to the code of the case-sensitive FastWildCompareUtf8() function. The code for the case-sensitive implementation invoked by the ::wildCompare() methods is virtually identical to that function. The FastWildCompareUtf8() code is based on the FastWildCompare() code of 2018. That FastWildCompare() code is ASCII-specific and isn’t included with FastUtf8.
::wildCaseCompare() methods
The ::wildCaseCompare() methods provide for strictly case-insensitive wildcard-based content comparison. They don’t check the IS_CASE_INSENSITIVE flag. The this content is the content that may include the ‘*’ or ‘?’ wildcards.
Signature
bool wildCaseCompare(const uint8_t *pTame) const;
bool wildCaseCompare(const char *pTame) const;
bool wildCaseCompare(const FastUtf8::Uniseries& tame) const;
Discussion
Refer to the Discussion for the ::wildCompare() methods (above).
::compareWild() methods
The ::compareWild() methods provide for wildcard-based content comparison. The inbound content is the content that may include the ‘*’ or ‘?’ wildcards.
Signature
bool compareWild(const uint8_t *pWild) const;
bool compareWild(const char *pWild) const;
bool compareWild(const FastUtf8::Uniseries& wild) const;
Parameter
The methods accept either a pointer to an inbound buffer or a reference to a Uniseries object. Each method treats the inbound content as the content that may have wildcards, and the this content as content without wildcards.
Discussion
These methods compare UTF-8 content, matching wildcards. They accept ‘?’ as a single-code-point wildcard. For each ‘*’ wildcard, a ::wildCompare() method seeks out a matching sequence of any code points beyond it. It otherwise compares the content a code point at a time.
::caseCompareWild() methods
The ::caseCompareWild() methods provide for strictly case-insensitive wildcard-based content comparison. They don’t check the IS_CASE_INSENSITIVE flag. The inbound content is the content that may include the ‘*’ or ‘?’ wildcards.
Signature
bool caseCompareWild(const uint8_t *pWild) const;
bool caseCompareWild(const char *pWild) const;
bool caseCompareWild(const FastUtf8::Uniseries& wild) const;
Discussion
Refer to the Discussion for the ::compareWild() methods (above). The ::caseCompare() and ::pSeparate() demo with UTF-8 content (below) has example code that invokes ::caseCompareWild(). The ::caseCompare() and ::pSeparate() demo with ASCII content also invokes ::caseCompareWild(), to get output shown in Fig. 4.
Example: ::caseCompare() and ::pSeparate() demo with UTF-8 content
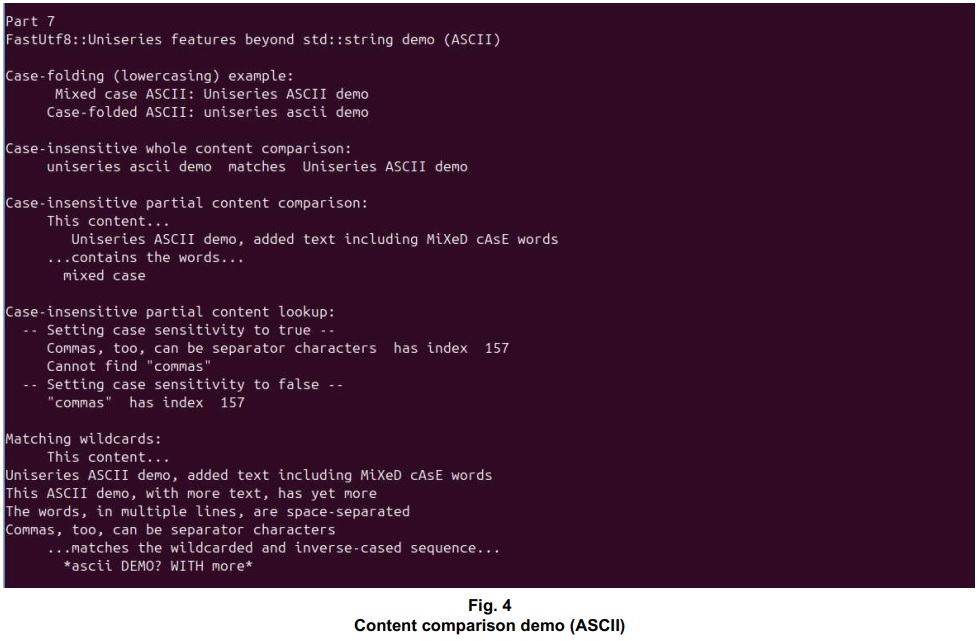
The Utf8UniseriesMultiFuncDemo() function is part of the ::caseCompare() and ::pSeparate() demo (CaseCompareAndSeparateDemo.cpp). Output for the portion of the demo program that handles ASCII content is shown in Figs. 4 and 5. Output for the portion that handles multi-byte UTF-8 content, as coded in Utf8UniseriesMultiFuncDemo(), is shown in Figs. 6 and 7.
// Demonstrates this FastUtf8::Uniseries functionality for UTF-8:
//
// UTF-8 support;
// Easy-to-use case folding;
// Case-insensitive whole content comparison;
// Case-insensitive partial content comparison and find (returning an index);
// Wildcard comparison, with / without case sensitivity;
// Content separation over a buffer that remains in place; and
// Trimming of outboard white space;
// Validations:
// that content comprises 7-bit ASCII characters, or
// that content comprises valid UTF-8 code points.
//
// This function demonstrates those aspects of FastUtf8.
//
int Utf8UniseriesMultiFuncDemo(void)
{
// Declarations of multilingual variants of "This is a UTF-8 demo."
Uniseries sAdlam = "𞤚𞤸𞤭𞤧 𞤭𞤧 𞤢 𞤓𞤚𞤊-𞥘 𞤣𞤫𞤥𞤮";
Uniseries sAmharic = "ይህ የ UTF-8 ማሳያ ነው።";
Uniseries sArmenian = "Սա UTF-8 դեմո է։";
Uniseries sBangla = "এটি UTF-8 এর একটি ডেমো।";
Uniseries sCantonese = "呢個系UTF-8嘅演示。";
Uniseries sCherokee = "ᎯᎠ ᎤᏣᏔ-8 ᏗᎦᏙᎤᏍᏗ ᎠᏍᎦᏯ.";
Uniseries sDeseret = "𐐜𐐮𐑅 𐐮𐑆 𐐩 UTF-8 𐐼𐐯𐑋𐐬.";
Uniseries sEnglish = "This is a UTF-8 demo.";
Uniseries sGreek = "Αυτό είναι ένα demo UTF-8.";
Uniseries sHebrew = "זהו הדגמה של UTF-8.";
Uniseries sHindi = "यह एक UTF-8 डेमो है।";
Uniseries sInuktitut = "ᐅᓇ UTF-8 ᑕᑯᒃᓴᐅᑎᑕᐅᔪᖅ.";
Uniseries sJapanese = "これはUTF-8のデモです。";
Uniseries sKlingon = " -8 .";
Uniseries sNepali = "यो UTF-8 को डेमो हो।";
Uniseries sOdia = "ଏହା UTF-8 ର ଏକ ଡେମୋ ।";
Uniseries sRunic = "ᛏᚺᛁᛊ ᛁᛊ ᚨ ᚢᛏᚠ-ᚹ ᛞᛖᛗᛟ·";
Uniseries sRussian = "Это демонстрация UTF-8.";
Uniseries sPashto = "دا د UTF-8 یوه نمونه ده.";
Uniseries sPersian = "این یک دمو از UTF-8 است.";
Uniseries sTamil = "இது UTF-8 இன் டெமோ ஆகும்.";
Uniseries sTigrinya = "እዚ ናይ UTF-8 ዲሞ እዩ።";
Uniseries sTelugu = "นఇది UTF-8 యొక్క డెమో.";
Uniseries sThai = "นี่คือการสาธิตของ UTF-8";
Uniseries sUrdu = "یہ UTF-8 کا ایک ڈیمو ہے۔";
// Case-folding demo.
std::cout ‹‹ "Case-folding examples:" ‹‹ std::endl;
size_t sizeFolded = Uniseries::getSizeFolded(sAdlam);
Uniseries sAdlamFolded1 = Uniseries::getFolded(sAdlam, sizeFolded);
Uniseries sAdlamFolded2 = "𞤼𞤸𞤭𞤧 𞤭𞤧 𞤢 𞤵𞤼𞤬-𞥘 𞤣𞤫𞤥𞤮";
if (sAdlamFolded1 == sAdlamFolded2)
{
std::cout ‹‹ " Mixed case Adlam script: " ‹‹
sAdlam ‹‹ std::endl;
std::cout ‹‹ " Case-folded Adlam script: " ‹‹
sAdlamFolded1 ‹‹ std::endl;
}
sizeFolded = Uniseries::getSizeFolded(sEnglish);
Uniseries sEnglishFolded1 = Uniseries::getFolded(sEnglish, sizeFolded);
Uniseries sEnglishFolded2 = "this is a utf-8 demo.";
if (sEnglishFolded1 == sEnglishFolded2)
{
std::cout ‹‹ " Mixed case English text: " ‹‹
sEnglish ‹‹ std::endl;
std::cout ‹‹ " Case-folded English text: " ‹‹
sEnglishFolded1 ‹‹ std::endl;
}
sizeFolded = Uniseries::getSizeFolded(sGreek);
Uniseries sGreekFolded1 = Uniseries::getFolded(sGreek, sizeFolded);
Uniseries sGreekFolded2 = "αυτό είναι ένα demo utf-8.";
if (sGreekFolded1 == sGreekFolded2)
{
std::cout ‹‹ " Mixed-case Greek stichos: " ‹‹
sGreek ‹‹ std::endl;
std::cout ‹‹ " Case-folded Greek stichos: " ‹‹
sGreekFolded1 ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of case-insensitive whole content comparison.
std::cout ‹‹ "Case-insensitive whole content comparison:" ‹‹ std::endl;
sEnglish.setCaseSensitivity(/* bCaseSensitive = */ false);
sGreek.setCaseInsensitive();
if (sAdlam.caseCompare(sAdlamFolded1))
{
std::cout ‹‹ " " ‹‹ sAdlamFolded1 ‹‹ " matches " ‹‹
sAdlam ‹‹ std::endl;
}
if (sEnglishFolded1 == "this is a utf-8 demo.")
{
std::cout ‹‹ " " ‹‹ sEnglishFolded1 ‹‹ " matches " ‹‹
"This is a UTF-8 demo." ‹‹ std::endl;
}
if (sGreekFolded1 == sGreek)
{
std::cout ‹‹ " " ‹‹ sEnglishFolded1 ‹‹ " matches " ‹‹
sEnglish ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of case-insensitive partial content comparison.
std::cout ‹‹ "Case-insensitive partial content comparison:" ‹‹ std::endl;
Uniseries sMulti1 = sHindi + ", " + sRussian + ", " +
sPashto + ", " + sPersian + ", " + sTamil + ", " + sTigrinya;
sMulti1.setCaseInsensitive();
if (sMulti1.contains("это демонстрация utf-8"))
{
std::cout ‹‹ " This content..." ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ sMulti1 ‹‹ std::endl;
std::cout ‹‹ " ...contains the Russian stroka..." ‹‹ std::endl;
std::cout ‹‹ " это демонстрация utf-8" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of case-sensitive and case-insensitive partial content lookup.
std::cout ‹‹ "Case-insensitive partial content lookup:" ‹‹ std::endl;
Uniseries sMulti2 = sAmharic + ", " + sBangla + ", " +
sCantonese + ", " + sCherokee + ", " + sDeseret + ", " + sHebrew;
Uniseries sMulti3 = sRunic + ", " + sInuktitut + ", " +
sJapanese + ", " + sKlingon + ", " + sNepali + ", " + sOdia;
Uniseries sMulti4 = sTelugu + ", " + sThai + ", " + sUrdu;
Uniseries sMultiCombo = sMulti1 + "\n" + sMulti2 + "\n" + sMulti3 +
"\n" + sMulti4;
std::cout ‹‹ " -- Setting case sensitivity to true -- " ‹‹ std::endl;
sMultiCombo.setCaseSensitivity(true);
int iOdiaLain = sMultiCombo.find(sOdia);
int iBindrune = sMultiCombo.find("ᛁᛊ");
if (iOdiaLain > 0)
{
std::cout ‹‹ " " ‹‹ sOdia ‹‹ " has index " ‹‹
iOdiaLain ‹‹ std::endl;
}
if (iBindrune > 0)
{
std::cout ‹‹ " " ‹‹ "ᛁᛊ" ‹‹ " has index " ‹‹
iBindrune ‹‹ std::endl;
}
int iRussianStroka = sMultiCombo.find("это демонстрация utf-8");
if (iRussianStroka > 0)
{
std::cout ‹‹ " " ‹‹ "это демонстрация utf-8" ‹‹ " has index " ‹‹
iRussianStroka ‹‹ std::endl;
}
else
{
std::cout ‹‹
" Cannot find Russian stroka / Не могу найти русскую строку" ‹‹
std::endl;
}
std::cout ‹‹ " -- Setting case sensitivity to false -- " ‹‹ std::endl;
sMultiCombo.setCaseSensitivity(false);
iRussianStroka = sMultiCombo.find("это демонстрация utf-8");
if (iRussianStroka > 0)
{
std::cout ‹‹ " " ‹‹ "это демонстрация utf-8" ‹‹ " has index " ‹‹
iRussianStroka ‹‹ std::endl;
}
else
{
std::cout ‹‹
" Cannot find Russian stroka / Не могу найти русскую строку" ‹‹
std::endl;
}
std::cout ‹‹ std::endl;
// Matching wildcards demo.
std::cout ‹‹ "Matching wildcards:" ‹‹ std::endl;
if (sMulti1.caseCompareWild("*ДЕМОНСТРА?ИЯ utf-8*"))
{
std::cout ‹‹ " This content..." ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ sMulti1 ‹‹ std::endl;
std::cout ‹‹ " ...matches the wildcarded and inverse-cased Cyrillic / Latin sequence..." ‹‹ std::endl;
std::cout ‹‹ " *ДЕМОНСТРА?ИЯ utf-8*" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of content separation and trimming.
std::cout ‹‹ "Content separation and trimming:" ‹‹ std::endl;
Uniseries sMultiComboDup = sMultiCombo;
std::unique_ptr‹FastUtf8::Uniseries> psMultiComboPart1 =
sMultiComboDup.pSeparate("\n");
std::unique_ptr‹FastUtf8::Uniseries> psMultiComboPart2 =
sMultiComboDup.pSeparate(" \n", /* bTrim = */ true);
if (sAmharic == *psMultiComboPart2)
{
std::cout ‹‹ " Extracted this content..." ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ *psMultiComboPart2 ‹‹ std::endl;
std::cout ‹‹ " ... from this content..." ‹‹
std::endl ‹‹ sMultiCombo ‹‹ std::endl;
std::cout ‹‹ " ... via two Uniseries::pSeparate() calls" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
// Demo of 7-bit character validation and of converting 8-bit ASCII to
// valid UTF-8.
std::cout ‹‹ "Validations:" ‹‹ std::endl;
char sz8BitAscii[6] = "\x80\x81\x82\xA5\xEA";
Uniseries sFormer8Bit = sz8BitAscii;
if (sEnglish.is7Bit())
{
std::cout ‹‹ " This content... " ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ sEnglish ‹‹ std::endl;
std::cout ‹‹ " ...is 7-bit ASCII text" ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
if (sFormer8Bit.validate())
{
std::cout ‹‹ " This 8-bit ASCII content... " ‹‹ std::endl;
#if defined(_WIN32)
SetConsoleOutputCP(437);
#endif
std::cout ‹‹ " " ‹‹ sz8BitAscii ‹‹ std::endl;
#if defined(_WIN32)
SetConsoleOutputCP(CP_UTF8);
#endif
std::cout ‹‹ " ...has been converted to this UTF-8 content..." ‹‹ std::endl;
std::cout ‹‹ " " ‹‹ sFormer8Bit ‹‹ std::endl;
}
std::cout ‹‹ std::endl;
return 0;
}

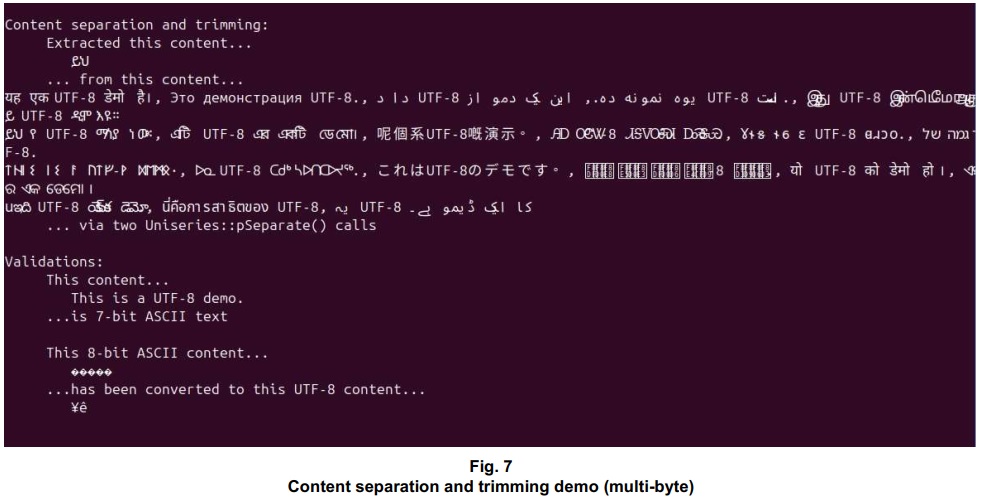
Uniseries() methods for targeted wildcard search
The targeted wildcard search concept is described with introductory comments and graphical examples as part of the FastUtf8 overview. There’s also a discussion of the design of the ::pFindWild() and ::casepFindWild() methods for targeted wildcard search, together with an outline of a use case for handling user input. Usage of those methods is explained here. They operate by calling one or another of the Wild*FindUtf8() functions for targeted wildcard search.
::pFindWild() methods
Each of the ::pFindWild() partial content comparison methods scans the this content for a first match on the inbound search pattern, which is expected to contain wildcards, and returns a pointer to the location within the the content corresponding to any first matching ‘*’ wildcard. If no match is found, or if no first ‘*’ wildcard is found, these methods set *ppFirst, *ppLast, and *ppTarget to nullptr and return nullptr.
Signature
uint8_t * pFindWild(const uint8_t *pWild,
uint8_t **ppFirst = nullptr,
uint8_t **ppLast = nullptr,
uint8_t **ppTarget = nullptr) const;
uint8_t * pFindWild(const char *pWild,
uint8_t **ppFirst = nullptr,
uint8_t **ppLast = nullptr,
uint8_t **ppTarget = nullptr) const;
uint8_t * pFindWild(const Uniseries& sWild,
uint8_t **ppFirst = nullptr,
uint8_t **ppLast = nullptr,
uint8_t **ppTarget = nullptr) const;
Parameters
[in] pWild
Search pattern (with wildcards). The third method whose syntax is listed above accepts its search pattern from a Uniseries object (sWild) instead of from a raw buffer comprising UTF-8 content.
[in / out, optional] ppFirst
Updated beginning location.
[out, optional] ppLast
Returned location where match ends.
[out, optional] ppTarget
Returned location after last ‘*’ wildcard.
Discussion
The optional parameters are returned targeted wildcard matching results. For example, given this content and input...
ppFirst: "here is some content to be matched."
pWild: "some*to*match" (location provided by caller)
...that is, if the caller points ppFirst to "here is some content to be matched" and provides addresses for ppLast and ppTarget, the method will provide pointers to matching locations within the content, this way:
*ppFirst: "some content to be matched." (location of first code point in overall match, updated by the method)
*ppLast: "hed." (location of last code point in overall match, set by the method)
*ppTarget: "matched." (location of last wildcard match, set by the method)
This is useful for seeking through a relatively large swath of content that includes a specified target portion within it. The method provides a speedy way for software to find a line, paragraph, stanza, or other programmatically distinguishable piece of writing that has a particular word or phrase in it, via one call. For scenarios where the target sought might be one of several known possibilities, a match might be verified by applying the ::slice() method to construct a Uniseries object with *ppTarget and *ppLast as the ::slice() parameters, then applying any of the Uniseries comparison methods.
::casepFindWild() methods
Case-insensitive implementation of the ::pFindWild() partial content comparison method.Signature
uint8_t * casepFindWild(const uint8_t *pWild,
uint8_t **ppFirst = nullptr,
uint8_t **ppLast = nullptr,
uint8_t **ppTarget = nullptr); const;
uint8_t * casepFindWild(const char *pWild,
uint8_t **ppFirst = nullptr,
uint8_t **ppLast = nullptr,
uint8_t **ppTarget = nullptr) const;
uint8_t * casepFindWild(const Uniseries& sWild,
uint8_t **ppFirst = nullptr,
uint8_t **ppLast = nullptr,
uint8_t **ppTarget = nullptr) const;
Discussion
Refer to the Discussion for the ::pFindWild() methods, above. The ::casepFindWild() methods act like the ::pFindWild() methods, except that they disregard the IS_CASE_INSENSITIVE flag.
Example: Targeted wildcard search demo
The FetchAuthorByTitleUsingFastUtf8Uniseries() function in the FastUtf8 overview has example code that invokes ::casepFindWild(). The function is part of the semistructured search demo (SemistructuredSearchDemo.cpp). Part of the demo program’s output is shown in Fig. 8.
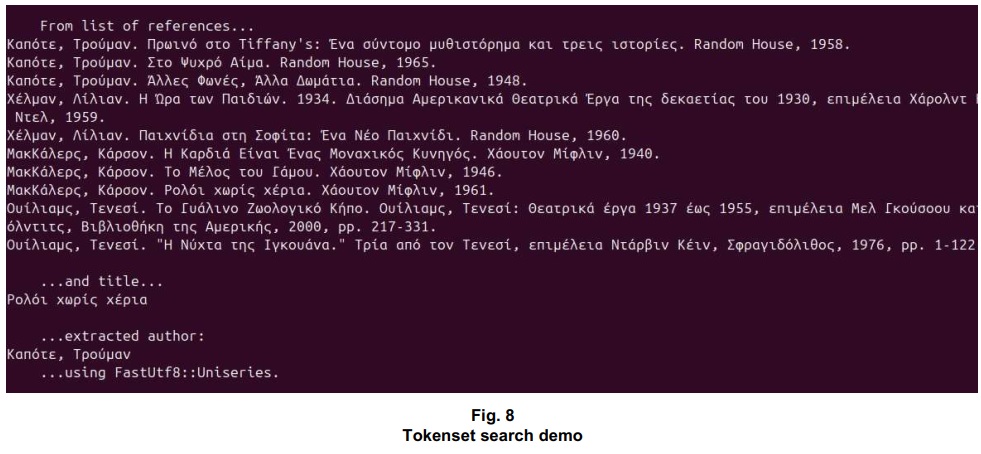
Uniseries subscript operators
The non-const and const subscript (index) operators call IndexUtf8(), unless the entire content is 7-bit ASCII text.
Signature
uint32_t operator[](int iIndex);
const uint32_t operator[](int iIndex) const;
Parameter
[in] iIndex
A count of code points, as an offset from the begining of the this object’s content, and within its length.
Discussion
This method returns the UTF-8 code point at the given index within the content. The performance is terrible, relative to ASCII string indexing.
If the index is not within the this object’s content, this method returns 0.
::trim() method
The ::trim() method removes outboard white space from the this object’s content by replacing the code points with nulls.
Signature
void trim(void);
Discussion
This method removes leading and trailing spaces from the this object’s content, modifying the content in place. It calls one or another of the Trim*() functions.
Uniseries validation and conversion methods
::validate() methods
Either of the ::validate() methods returns true if all of the this object’s content is valid UTF-8.
Signature
bool validate(int *iCount) const;
bool validate(void) const;
Parameter
[out, optional] iCount
A count of the validated code points.
Discussion
This method calls one or another of the *ValidateUtf8() functions. If the IS_LENGTH_LIMITED flag is set, this method validates as many code points as have been specified via the ::setLengthLimit() method. Otherwise, it validates code points until it encounters a terminating null and gets their count, which it returns via the optional iCount parameter. The ::caseCompare() and ::pSeparate() demo with UTF-8 content has example code that invokes ::validate().
::convert8BitAscii() methods
In case content validation fails, the ::convert8BitAscii() method may serve as a reasonable fallback. It calls one or another of the *Convert8BitAsciiToUtf8() functions. It returns valid UTF-8 content and sets the optional iCount parameter reflecting the content’s length, as a count of its code points.
Signature
uint8_t * convert8BitAscii(int *iCount);
uint8_t * convert8BitAscii(void);
Parameter
[out, optional] iCount
A count of the converted 8-bit ASCII characters.
Uniseries output stream operator
The output stream operator<< can be used to send the content of a Uniseries object to the console.
Signature
friend std::ostream& operator<<(std::ostream& theStream,
const FastUtf8::Uniseries& theOutput);
Discussion
The console must be set up with one or more fonts compatible with the natural language(s) to be displayed; otherwise the content won’t display correctly.
A counterpart operator>> would be relatively complicated. It would have to manage a resizeable input buffer to handle input of arbitrary size, and it would have to ensure the needed memory management for the Uniseries content buffer receiving the input.
Extending FastUtf8
In case you’ve got particular ASCII functionality in mind that you’d like to see UTF-8-enabled, and no Uniseries methods described here are quite like it, what might you do? The aspects of ASCII character processing reimplemented to underlie the UTF-8 functionality described throughout this guide have included nothing more than char * pointer-based increment, compare, increment-and-compare, and decrement operations. Where these operations occur in ASCII-specific code, a UTF-8-enabled version invokes these functions:
- CodePointAdvanceUtf8()
- CodePointCompareUtf8()
- CodePointAdvanceAndCompareUtf8()
- CodePointBacktrackUtf8()
These functions are defined near the top of fastutf8.cpp. They’re slower than their char * counterparts, and on top of that – unlike the situation with ASCII – backtracking through UTF-8 content is considerably slower than advancing. If you’d like your code to keep calling your ASCII-specific routine for 7-bit ASCII text and to call a UTF-8-ready routine just for multi-byte UTF-8 content, then your code can construct a Uniseries object, or an object of a Uniseries-based class, and can make use of that object’s IS_7BIT_CHAR_STRING flag. The flag can guide the choice of which routine – UTF-8-enabled or ASCII-specific – to programmatically invoke.
The Uniseries iterator invokes the pointer-driven functions listed above and serves as their plainest interface at present. If a need arises to derive a Uniseries-based class that builds directly on that pointer-driven functionality, an easy change to the class might involve wrapping those functions in Uniseries methods declared as protected. A method in a derived class could, for now, use the Uniseries iterator to access individual code points within multi-byte content and could use char * pointers or the std::string iterator to access characters within 7-bit ASCII content.
Most code that makes the switch from ASCII to UTF-8 will encounter a slowdown, but with a Uniseries object – thanks to the flag-based mechanism I’ve just described – you can limit the slowdown almost entirely to the object’s construction phase. That step of Uniseries construction involves UTF-8 validation. But once that’s done, any remaining ASCII processing can happen with virtually no slowdown, even if your project includes code that’ll do revalidation for safety. The slowdown of up-front UTF-8 validation is most prominent for short content snippets that get processed only once. For larger content that comes to reside in reusable Uniseries objects, your UTF-8-ready code can run with about the same 7-bit ASCII performance as it did prior to UTF-8-enablement.
The complete FastUtf8 source code is available at GitHub > kirkjkrauss > FastUtf8. The above source code listings are extracted from the included code in Demos. The listings are formatted using the SyntaxHighlighter library, copyright (c) 2004-2013, Alex Gorbatchev.
All other materials copyright © 2026 developforperformance.com.
C++ and its logo are trademarks of the Standard C++ Foundation. Windows® and Visual Studio® are trademarks or registered trademarks of Microsoft Corp. Unix® is a registered trademark of The Open Group. Linux® is a registered trademark of Linus Torvalds. Ubuntu® is a registered trademark of Canonical Ltd.