Fast UTF-8 handling for modern C++ with support for legacy C ♦ Overview
By Kirk J Krauss
What’s Here
- An introduction to the FastUtf8::Uniseries C++ class;
- A reason to target just UTF-8 for C/C++ internationalization: it slashes case folding bloat associated with unnecessary encodings;
- An introduction to the C-compatible functions that do the heavy lifting for FastUtf8; and
- A discussion of included methods for expressive queries against semistructured internationalized content and their outstanding performance results relative to prior methods.
Background
The footprint of the global datasphere is estimated to be in the hundreds of zettabytes. Most of it is unstructured or semistructured data. There are hundreds of natural languages represented on the Internet, with less than half of websites in English. Mature programming languages, including C/C++, stem from a time frame when the Internet wasn’t this way.
Providing for natural language support, in steps composed entirely via imperative programming, can lead to layers of sophisticated code. For example, to pick out a title from a semistructured list comprising titles of books and corresponding authors, one step might involve case folding for a given author’s name. Another step might involve separating the list into discrete lines based on tokens. Yet another step, where mixed natural languages are involved, might include matching various further tokens used in the various languages. The result: slow, kludgy, narrowly focused code. Such code has worked in the past, and it still can – but isn’t there a better fit for the scope of data we have today?
In the world of structured data, such as what’s associated with relational databases, declarative queries are the norm. Expressive syntax is handled via fast, tested methods that hide the complexities of finding content. As distributed systems consultant Martin Kleppmann puts it, “In a declarative query language, like SQL or relational algebra, you just specify the pattern of the data you want... but not how to achieve that goal.” Can any sort of declarative query be applied, in C/C++, to semistructured data? Even modest steps toward making it happen could result in more reliable and fast internationalized applications.
Declarative queries for semistructured natural language
Aiming for a rich declarative arrangement, like SQL but targeted at semistructured data, may not be helpful. There are a great many natural languages that C/C++ code might parse, and each may have a way of its own for delimiting content. On the other hand, to a certain degree, semistructured data formats tend to be shared across those languages. A declarative query that works for one locale can work for another, so long as there’s enough flexibility in the query, and in the mechanism enabling it, to account for cross-locale distinctions. For that reason, any such mechanism may best follow this rule of thumb: the simpler its interface, the better.
Neither an SQL-style arrangement nor a multi-step method, such as in the book title example of the second paragraph above, is particularly simple. That is, methods for handling semistructured data in C/C++ have centered around carefully-arranged loops that a developer must be able to comprehend and modify, for every little change in the data or its format, yet the very idea of enabling expressive queries for semistructured data has seldom arisen. Over twenty years ago, knowledge base consultant Mike Bergman put the situation this way:
Generally, most academic, open source, or other attention to these problems has been at the superficial level of resolving schema or definitions or units. Totally lacking in the entire thrust for a semi-structured data paradigm has been the creation of adequate processing engines... You know, it is very strange. Tremendous effort goes into data representations like XML, but when it comes to positing or designing engines for manipulating that data the approach is to clone kludgy workarounds on to existing relational DBMSs or text search engines.
Making Validation Make Sense
A random sequence of bytes might be interpretable as valid UTF-8, but the more bytes there are in the sequence, the less likely this becomes. A byte sequence isn’t valid UTF-8 unless it conforms to the standard encoding format. There also are standards that call for error handling. But what to do when there’s an error? And in which situations does well-designed software best validate a UTF-8 sequence?In answer to the second question, an impulsive approach would be to validate every byte every time it’s read. If we’d been considering ASCII content, the possibility would hardly have come to mind. The conditions that could clobber content are roughly alike, for both ASCII and UTF-8, and the idea of detection based on the content itself is worth considering – but is a routine that needs to quickly return results most efficacious for the purpose?
My suggestion is that UTF-8 validation can indeed be useful, and that a validation routine can be regularly invoked within any software that prioritizes reliable content handling. I also suggest performing the validation in two conditions:
- when UTF-8 content is first stored in memory, and
- via a low-priority thread that can find and revalidate the UTF-8 content already stored in memory.
Regarding the question of programmatic error handling, some past answers have included either truncating away any invalid portions or haphazardly synthesizing new ones. Those answers are, in other words, to throw away or corrupt potentially irreplaceable data. Why would anyone want to do that?
Instead, my suggestion is to consider how a routine meant to handle valid UTF-8 has found itself faced with something other than valid UTF-8. In other words, retest and debug. In the event that a general-purpose answer is the best available, like in a live application that’s got to do something with unexpected content without waiting for human intervention, then I suggest treating that content as 8-bit ASCII. After all, if a UTF-8-handling routine has been given some content to handle, and that content doesn’t check out as UTF-8, then ASCII is the most prevalent encoding that might’ve been in its place. Translating data cast as 8-bit ASCII text into valid UTF-8 content is lossless: the translation can be undone in case the need arises.
In other words, as of 2026, C++ is an ASCII-centric programming language that would benefit from a declarative natural language search mechanism with a simple interface. Such a mechanism built today would best be built around functionality for general UTF-8 support. Can this be found based on open-source solutions?
Until now, for the C/C++ developer looking for a no-frills approach to UTF-8 enablement, there’s been no simple answer. Methods for handling UTF-8 in C++ have been overloaded with support for extraneous encodings or with a broad range of extraneous functionality. Others have lacked thorough testing and performance comparisons against standard string functionality. Extraneous encodings may create more overhead than other extraneous functionality, particularly if each encoding provides for case-insensitive content matching. To achieve best performance, each case mapping arrangement for internationalized content is based on in-memory tables that can occupy megabytes.
The cost of code bloat can be viewed as a performance penalty, but there’s a bigger-picture view. Increasingly, elimination of overhead is associated with environmentally “greener” software. Low-bloat high-performance code is nowadays perceived as the responsible – not just responsive – solution.
What’s needed is a provably reliable modern C++ class, or a family of functions compatible with legacy C, that has a focus on UTF-8 enablement and that provides a basis for declarative queries against semistructured internationalized content.
Can we reasonably speak of a declarative query without positing a query language in which to frame it? For C++, we can code a method that takes an expression as input: a pattern for matching against UTF-8 content, or a set of code points to find among the content, or other arrangements yet to be invented. Outside the UTF-8 context, Martin Kleppmann has described pattern matching within functional programming as a “declarative approach” in which...
The logic of the query is expressed with code but it’s repeatedly called by the processing framework.The framework he had in mind when he wrote that statement was a NoSQL datastore, specifically MongoDB. But conceptually, the framework could be as simple as a family of functions for handling UTF-8 content. In any case, as he puts it, “...this declarative approach... makes it possible to introduce performance improvements without requiring any changes to [a] query.”
Imagine a semistructured writeup such as a parts inventory, a list of films organized by their titles and including the directors’ names, or a series of MLA-style references cited in a report. If that writeup is encoded in UTF-8, software can efficiently find most any delimited portion of it, based on just a few lines of code, using one or more of these methods:
- Targeted wildcard search;
- Tokenset search; and/or
- Basic full-text search, of the std::string::find() variety.
Targeted wildcard search
Searching a relatively large chunk of content for a relatively small chunk that matches a search pattern – one that can contain wildcards – isn’t a new concept. Notepad++ offers a regular expression search that can operate across multiple files. But regular expressions lack standards and typically don’t perform nearly as well as dedicated algorithms for matching wildcards. Yet aside from regular expressions, until now, I haven’t seen a fast wildcard-driven search method unbundled and available as a tested C/C++ function.
There’s no reason wildcards can’t be incorporated into a UTF-8 search pattern passed into C/C++ code along with some UTF-8 content to be searched. In the search pattern, the wildcards can include the code points for ‘*’ (which matches any number of code points within the content) and for ‘?’ (which matches any single code point). Unlike Notepad++, which always finds the first match on the first and last code points a given search pattern, a more typical use case for C/C++ might be to construct a slice of the content based on the match on a wildcard itself.
Which slice would that be? As it turns out, existing methods for matching wildcards track state that might be relevant in a range of scenarios. Matching wildcards is a backtracking endeavor to begin with, and the location of a prospective match on a wildcard is something that’s necessarily tracked. Arranging logic around the method to find a match within a larger chunk of content means tracking, additionally, the beginning and ending locations of the match on the overall search pattern, as with Notepad++. Any or all of these locations could be natural candidates for slice contruction following a successful targeted wildcard search.
Example based on a few MLA-style references
Capote, Truman. In Cold Blood. Random House, 1965.
Capote, Truman. Other Voices, Other Rooms. Random House, 1948.
Hellman, Lillian. The Children's Hour. 1934. Famous American Plays of the 1930s, edited by Harold Clurman, Dell, 1959.
Hellman, Lillian. Toys in the Attic: A New Play. Random House, 1960.
McCullers, Carson. The Heart Is a Lonely Hunter. Houghton Mifflin, 1940.
McCullers, Carson. The Member of the Wedding. Houghton Mifflin, 1946.
McCullers, Carson. Clock Without Hands. Houghton Mifflin, 1961.
Williams, Tennessee. The Glass Menagerie. Tennessee Williams: Plays 1937 through 1955, edited by Mel Gussow and Kenneth Holditch, Library of America, 2000, pp. 217-331.
Williams, Tennessee. "The Night of the Iguana." Three by Tennessee, edited by Darvin Kane, Signet, 1976, pp. 1-122.
Suppose we’re searching for the title of a book by an author whose last name matches “mccullers” and we have a set of MLA citations, in English, to search. We can find a title based on the last wildcard of a search pattern expressed this way:
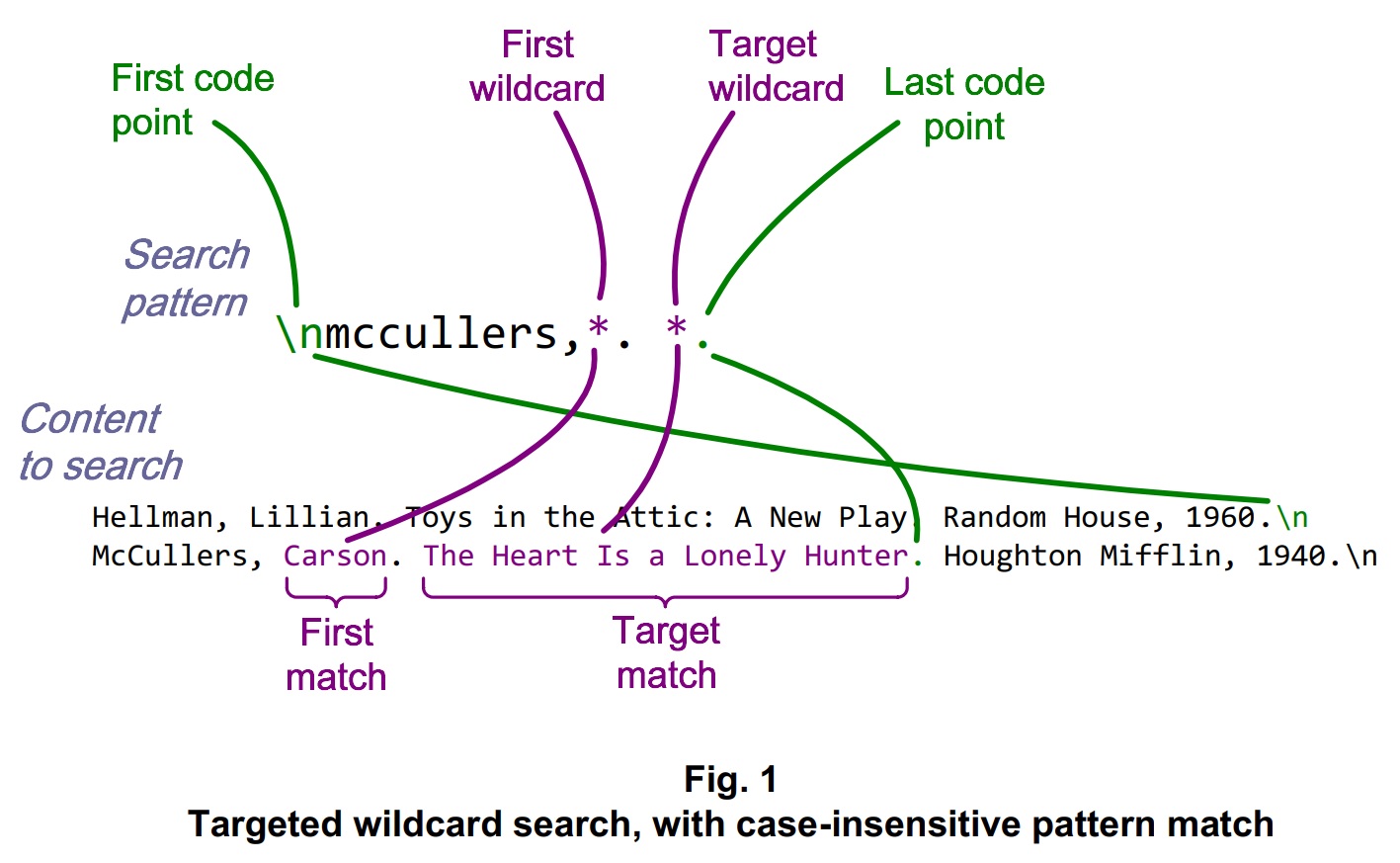
In this example, the author’s last name and first name, along with the book title and the preceding newline code point,
comprise the overall match, whose first and last code point locations are highlighted in green. If the entire MLA listing
is the content sought, instead of just the book title, then the newline code point (which occupies a single byte) can be
elided by incrementing the first code point location prior to constructing a slice.
Because the content matching the last wildcard of the search pattern makes such a convenient target, it might as well be called one. In some contexts, the match on the first wildcard is just as interesting. Or if you need the entire line containing the MLA reference for The Heart Is a Lonely Hunter, then you can tack on another ‘*’ wildcard and a ‘\n’ (newline) code point, at the end of the search pattern, so as to construct a slice based on the first and last code points of the overall match.
\nmccullers,*. *. *\n
To arrange these matches using looping logic around std::string::find() would be quite complicated, by comparison with the expressiveness of targeted wildcard search. Also, the performance of any such arrangement would likely be several times slower – you can check that out on your own machine via the semistructured search demo. To arrange a similar case-insensitive match against similar content in Greek would be impossible using just std::string methods, but targeted wildcard search works the same as with content in English.
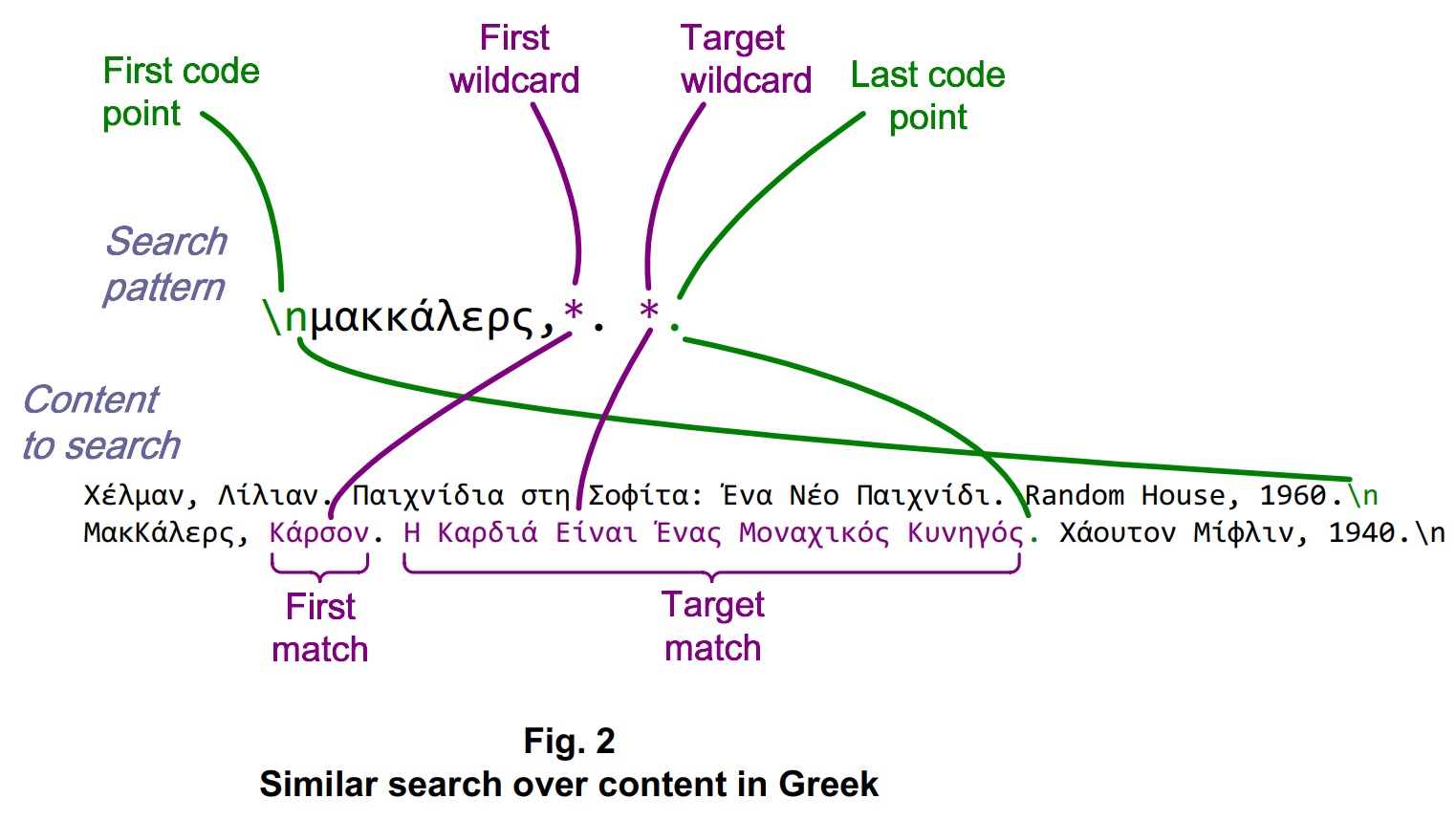
Wildcard syntax is familiar among computer users and is internationally agnostic: the ‘*’ and ‘?’ wildcards are, themselves, code points that can be used to designate matches against any other code points. A wildcard-driven search may not have all the capabilities of a RegEx-driven search, but with a modern implementation, it’s fast enough to be placed in a loop where it can tyically work far more efficiently than prior full-text search logic. A loop that finds all instances of a wildcard match can easily fit formats ranging from XML to custom log layouts.
What, then, are the limitations of the technique? Targeted wildcard search has quite a range of use cases, but not all of them perform well. The more wildcards there are in the search pattern, the more backtracking overhead can slow the search. If you find yourself considering a search pattern that includes one or more series of ‘?’ wildcards, it’s time consider a different approach.

Tokenset search and basic full-text search
For mixed-language content, mixed-language delimiters may be appropriate. The approach to consider, when content separation or slicing can be driven by more than just one delimiter, is tokenset search. It’s a method of choice for mixed-language content delimited by mixed-language tokens.
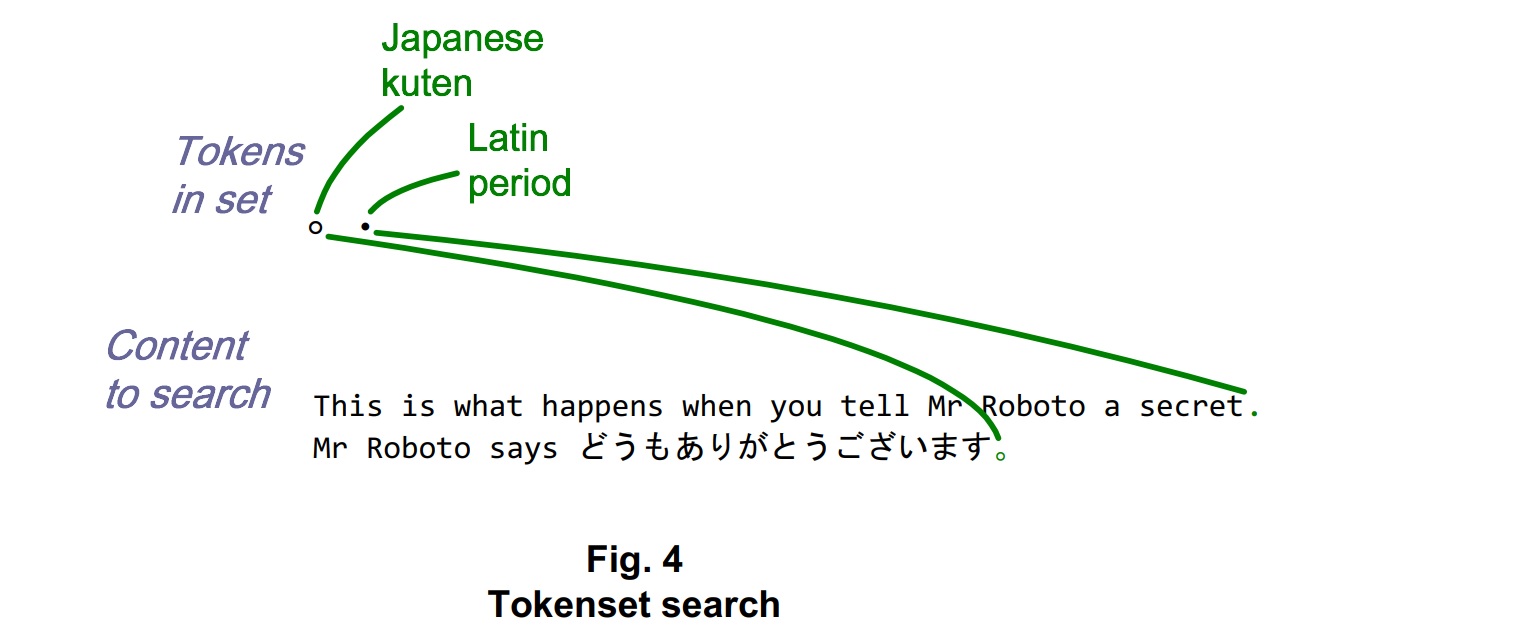
Suppose you’ve got a document written in a mix of languages including English and Japanese. English sentences are delimited by the Latin period (‘.’), and Japanese sentences are delimited by the kuten (‘。’). The tokenset search concept is utterly simple: search the document for any of the tokens in the set. Then separate the content, or construct a slice, accordingly. The difference between this concept and conventional string tokenization is that more than one token may serve as a delimiter – yet only one pass through the document is needed to find a match on one of the tokens in the set.
As for basic full-text search, standard string functionality for C/C++ already includes it, but the standards fall short of covering case-insensitive matching on the bicameral content to be found across the datasphere. As with the targeted wildcard search and tokenset search, correctness and performance are optimal for UTF-8 when the search method is UTF-8-specific and when case folding happens on an as-needed basis.
What name to give a new C++ class designed for internationalized semistructured content? The concept is about as different from standard ASCII strings as those strings are from the archaic methodology after which they’re named. Even the methods for handling a chunk of UTF-8 data and an ASCII string must be different. While the char type serves most every ASCII purpose, a given UTF-8 code point might have its starting location at any uint8_t boundary, yet that code point might occupy an entire uint32_t space. Also, UTF-8 provides more than internatialization support; it includes standardized graphemes such as emoji, logic symbols, and much more.
One commonality between ASCII and UTF-8 – one that stands out to me, anyway – is that both are uniserial data formats. Also, both ASCII and UTF-8 are standards with such widespread usage that any namespace that aims to support them calls for utmost performance. It’s with those aspects in mind that I’ve selected monikers for the namespace and class presented here.
The FastUtf8::Uniseries class
The FastUtf8 namespace has three classes:
- The Initializer class, for setting up case mappings;
- The Uniseries class, for UTF-8 content and associated metadata; and
- An iterator class nested within the Uniseries class.
The Initializer class is instantiated, just once per run, by the Uniseries constructor when it’s first invoked. Upon instantiation, it invokes the C-style function CaseMappingSetupUtf8() to initialize the mappings used for case folding. The mappings reside in the Data segment of the module built from the FastUtf8 code and occupy over four megabytes.
Listing One
namespace FastUtf8
{
// ... the namespace includes flags that define the default behavior of
// Uniseries objects; code involving those flags resides here ...
class Initializer
{
// Disallow duplicates of this object.
public:
Initializer(const Initializer&) = delete;
Initializer operator=(const Initializer&) = delete;
// The static object is wrapped in a function as a local static variable,
// so the constructor gets invoked just once.
static FastUtf8::Initializer& setupCaseMappingOnce()
{
static FastUtf8::Initializer theInstance;
return theInstance;
}
// Disallow direct instantiation.
private:
Initializer()
{
CaseMappingSetupUtf8(); // Set up mappings for case folding.
}
};
// ... the Uniseries class is declared here ...
Null Terminators Significantly Outperform Length Limits
There have been documented cases where an input buffer overflow has brought down multiple computers or entire networks. To prevent such problems, a recommended approach is that “you should always check buffer sizes:” that is, every call to every function that operates on a buffer gets a buffer length limit as an input parameter. The function then checks every memory location it reads or writes against that length limit, throughout operation. That recommended approach may indeed be safe, but it’s slow for ASCII and terrible for UTF-8.
Once a buffer has been validated as sufficient for its content, such as when the content is introduced, there’s no way harm can arise by either...
- copying it to another buffer of the same (or greater) size,
- updating a portion of it, in place, or
- accessing it for read-only usage.
Case mappings are set up according to data in arrays declared in casemappings.h and defined in casemappings.cpp. The data in the arrays was derived from https://www.unicode.org/Public/12.1.0/ucd/CaseFolding.txt and transformed to fit the UTF-8 encoding standard. The Microsoft® Excel® macro included in the CaseFolding-12.1.0.xls file, associated with the source code on GitHub, was used to transform CaseFolding.txt for use with UTF-8.
The Uniseries class has just two private data items:
- A pointer to a content buffer; and
- Metadata comprising a set of flags relevant to the content and its length in code points.
The flags indicate whether the content is to be treated as 7-bit ASCII, as case-insensitive, and/or as length-limited. There are length-limited varieties of every relevant C-style function that gets invoked by the Uniseries methods; there also are equivalent – but faster – functions that operate over content until reaching any terminating null. Which to choose? See the sidebar at right.
An additional flag tells the Uniseries destructor to avoid deallocating content that is part of a larger buffer. This becomes useful if a relatively large buffer is separated into smaller null-terminated portions via the Uniseries::pSeparate() method, which works approximately like the C standard library’s strtok() function, except that it provides for tokenset search, plus it’s thread-safe.
Listing Two
class Uniseries
{
private:
static constexpr uint64_t IS_7BIT_CHAR_STRING = 1ULL << 0x3F;
static constexpr uint64_t IS_CASE_INSENSITIVE = 1ULL << 0x3E;
static constexpr uint64_t IS_LENGTH_LIMITED = 1ULL << 0x3D;
static constexpr uint64_t IS_DEALLOCATED_EXTERNALLY = 1ULL << 0x3C;
static constexpr uint64_t FLAGS_MASK = IS_7BIT_CHAR_STRING |
IS_CASE_INSENSITIVE |
IS_LENGTH_LIMITED |
IS_DEALLOCATED_EXTERNALLY;
static constexpr uint64_t LENGTH_MASK = ~(uint64_t) FLAGS_MASK;
uint8_t *m_pContent; // Comprises UTF-8 code points.
uint64_t m_metadata; // Comprises flags and length.
public:
// ... the Uniseries constructor, destructor, nested iterator class, and
// other Uniseries methods are declared here ...
}; // class Uniseries
// ...
}; // namespace FastUtf8
Most of the Uniseries methods invoke C-style functions, but they’re more than just wrappers around those functions. When a Uniseries object holds nothing but 7-bit ASCII text, its methods know to invoke ASCII-specific functions, making Uniseries performance almost comparable to that of any other C++ class that handles ASCII.
I say “almost” because the Uniseries constructors perform a UTF-8 validation step for each new object. That step takes time, but once it’s done, revalidation can happen any time, ideally when the system isn’t particularly busy, via a call to FastUtf8::Uniseries::validate(). Along with validation, what other methods do you get? Taking things in the order they appear in fastutf8.h, you’ll find methods that do these operations:
Pointers Significantly Outperform Indices
A purist of memory safety may raise an eyebrow over the arrangement of pointers that get passed among the Uniseries methods. Among the methods, certain ones are designed that way, for these reasons:
- The underlying C functions return and/or accept these pointers, and the C++ layer retains them for consistency;
- UTF-8 code points are of variable size: seeking through content to reach a given offset (given as a code point count), or for a given index, is very slow; and
- There’s nothing inherently unsafe about pointers managed by methods sufficiently designed, tested, and runtime-analyzed.
If your code does nothing with the pointers returned by Uniseries methods but pass them to other Uniseries methods, is that really safe? Here’s the result of a Purify run using a version of the test set for the C-style functions that return and accept the pointers.
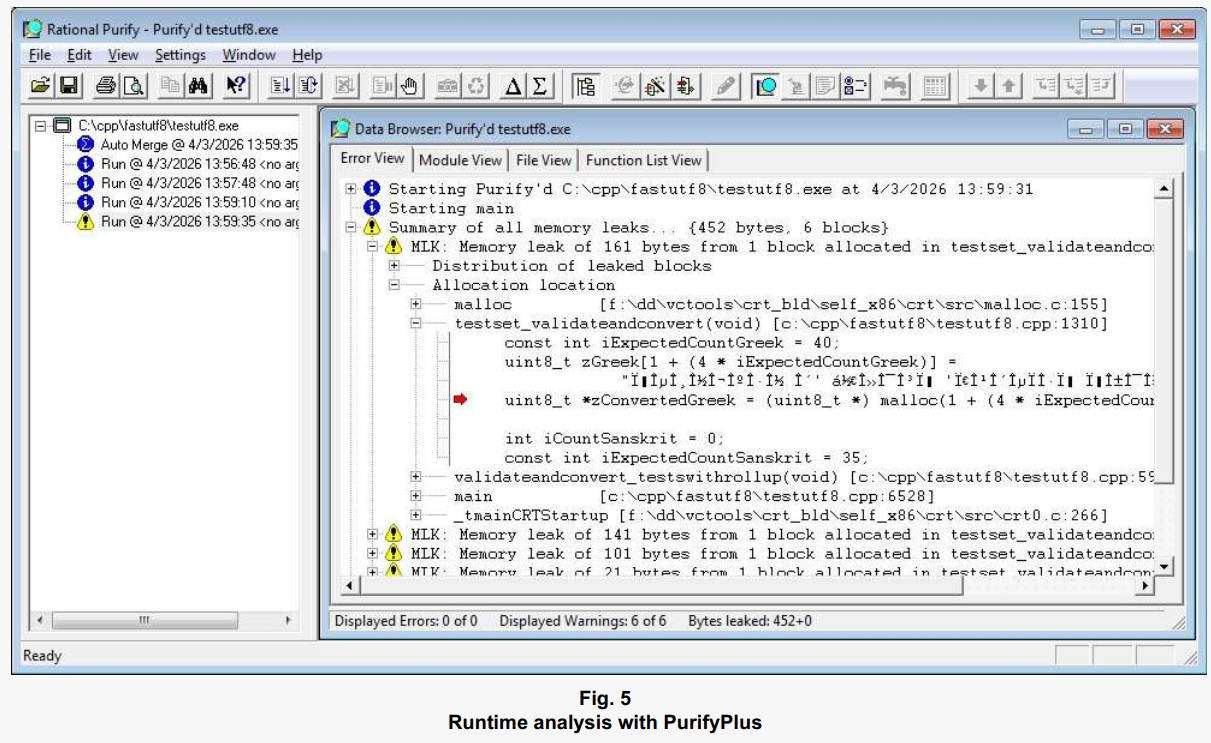
The memory leaks occurred because when I first coded these tests, I unthinkingly set them up to allocate a few content buffers that ended up getting allocated – again – by Convert8BitAsciiToUtf8(), the function underlying the Uniseries::validate() method mentioned toward the end of the list at left. The original pointers, which had been returned when testset_validateandconvert() called malloc(), got clobbered. The leaks are fixed in the released code for the tests.
Does Purify catch every single thing that can go wrong with pointers? Maybe not, but then there are ways to get in trouble even without pointers. Long story short: if the pointers make you uncomfortable, bear in mind that most of the Uniseries methods that incorporate them come with index-driven counterparts.
- A pair of parameterized constructors, for uint8_t * or char * buffers, each of which makes a deep copy of the buffers’ existing content for use as a Uniseries object;
- A standard constructor;
- A copy constructor that creates a Uniseries object from the content buffer and metadata of an existing one;
- A pair of range-based slice constructors, for uint8_t * or char * buffers, each of which creates a Uniseries object from a buffer designated by pFirst and pLast pointers;
- A destructor;
- Assignment operators for uint8_t * and for char *;
Slice & concatenate
- A slice() constructor that creates a new Uniseries object from an existing one, making a deep copy of a portion of its content specified by iFirst and iLast code point indices;
- A fromSlice() constructor, similar to slice() but pointer-based;
- Concatenation operators for uint8_t *, for char *, and for Uniseries objects.
Separate
- A set of pointer-based pSeparate() content separation methods, each of which constructs a Uniseries object from a portion of the existing object’s content based on a search for one or more tokens in a set;
- A set of pointer-based pFindToken() methods that also perform tokenset search;
Access
- An Iterator class for working with individual code points;
- A set of getContent() methods;
- A getMetadata() method for direct access to a Uniseries object’s flags and length;
Length check & case fold
- Methods for checking or modifiying the Uniseries object’s case sensitivity and length-limited behavior;
- A set of getLength() and getSize() methods that return a code point count or a size in bytes, respectively;
- A set of getSizeFolded() methods that precompute the size of a buffer needed to hold content after case folding;
- A set of getFolded() methods that perform case folding;
Evaluate & compare whole content
- An is7Bit() method that indicates whether content is entirely ASCII text;
- Equality operators and caseCompare() methods;
- A set of contains() partial content comparison methods that return Boolean results;
Basic full-text search
- A set of find() partial content comparison methods, each of which can return the index of a chunk of content within a Uniseries buffer;
- A similar set of pFind() methods, each of which returns a pointer instead of an index;
- A set of caseContains() methods, similar to contains() but case-insensitive;
- A set of caseFind() and casepFind() case-insensitive methods;
Wildcard techniques
- A set of wildCompare() and compareWild() methods for matching wildcards;
- A set of wildCaseCompare() and caseCompareWild() methods for case-insensitive matching;
- A family of pFindWild() and casepFindWild() methods for targeted wildcard search;
Other features
- Subscript operators with terrible performance;
- A trim() method that removes outboard white space;
- A pair of validate() methods;
- A pair of methods for converting 8-bit ASCII text to UTF-8; and
- An output stream operator.
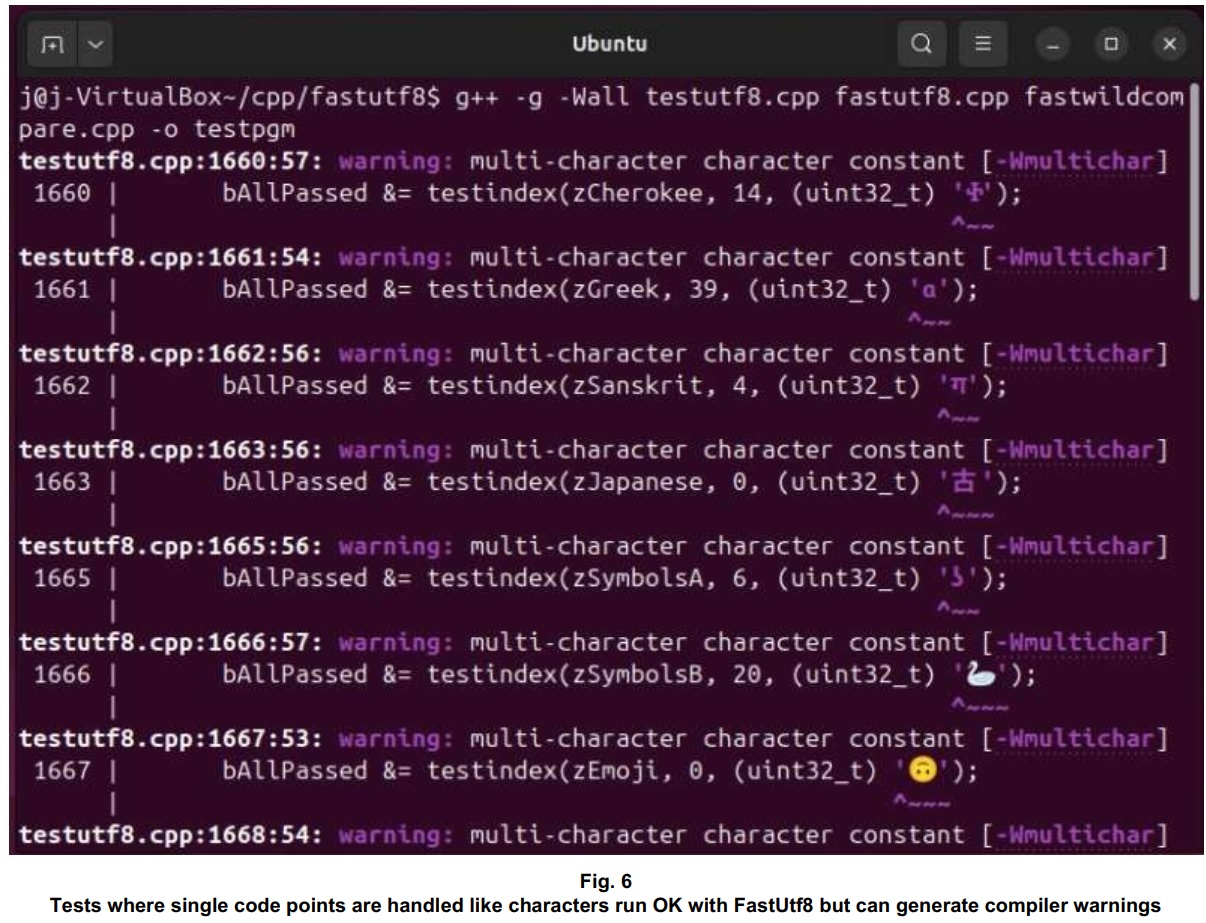
Both the FastUtf8 functionality and the legacy C code on which it’s based are platform-neutral. On some platforms, mixing UTF-8 and legacy C can result in compiler warnings. The warnings may be familiar to anyone who works regularly with that mix. Treating a single code point as a hard-coded character works, at least on the systems where I’ve tried it, and I have trouble imagining what actual problem (such as involving endianness) might arise for the single-system demos and tests described here, so I’ve ignored the warnings.
In Action: Uniseries Demos
Demo program source code for the FastUtf8::Uniseries methods is available at GitHub > kirkjkrauss > FastUtf8 > Demos. To build them for the runs on Windows shown here, I’ve appended the path containing the fastutf8.h and casemappings.h header files onto the INCLUDE path and incorporated the two corresonding .cpp files into each build.

The first function in FundamentalsDemo.cpp is a machine-generated function that I got by entering this into Google:
std::string demo with concatenate, separate, substring, whole string comparison, and substring find operationsWith the resulting machine-generated function in hand, I coded similar functionality in three different variations using the FastUtf8::Uniseries methods. I also coded a modified version of the std::string demo from Google – a “muted” one that runs without console output – for performance comparison against the Uniseries-based variations, similarly muted. The resulting FundamentalsDemo program can run with or without the performance comparison. To run it with the performance comparison, you specify a given number of repetitions for each muted variation by providing the command line argument with, followed by that number of reps. A reasonable number might be in the hundreds of thousands, or in the millions.
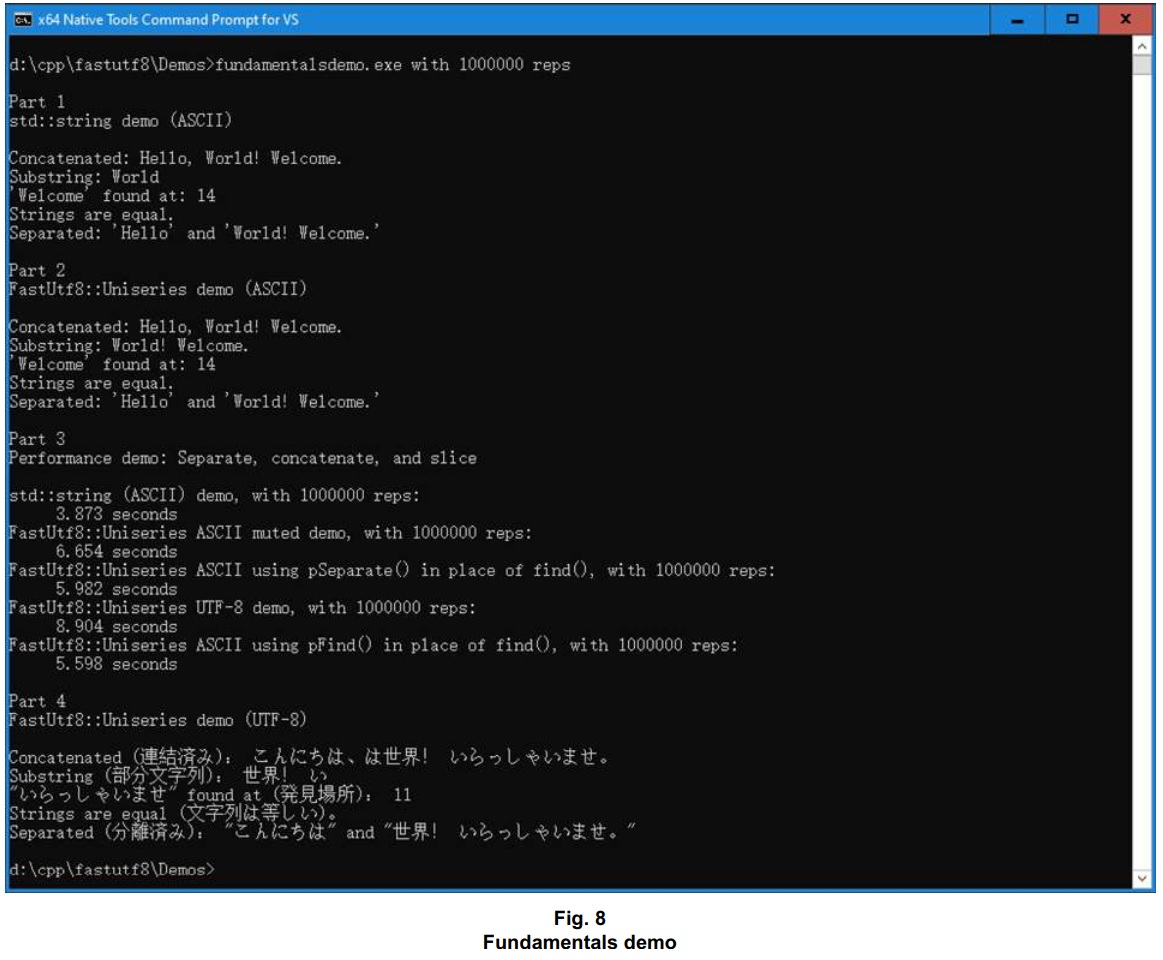
The FundamentalsDemo.cpp code centers on short “Hello, world” content. For the FastUtf8 portion of the demo, the content first gets searched and separated via the Uniseries::find() and ::slice() index-based methods. Because of up-front validations, we see that a million repetitions take almost twice as long as a million repetitions using the std::string methods – but the pointer-driven Uniseries() variations make for a closer match.
Short content fragments are bound to take extra time for setup as Uniseries objects, because of the up-front validation step incorporated into the Uniseries constructor. That’s why we see such a slowdown for the Uniseries::find() method in FundamentalsDemo. For the pointer-driven Uniseries variations, we first switch to the Uniseries::pSeparate() method, in place of Uniseries::find(), followed by a variation where the content is a Japanese translation of the original “Hello, world” content. Finally, we see that a switch to the pointer-driven Uniseries::pFind() method shaves over a second from the index-based ::find() method for our million iterations.
If your program deals mainly in short content, you may not notice a performance difference of two-three seconds that accumulate over millions of operations. Fortunately for the Uniseries methods, the bigger the content, the less relative impact we’ll see from our up-front UTF-8 validations. And heavy-duty searching is where a performance difference may matter.
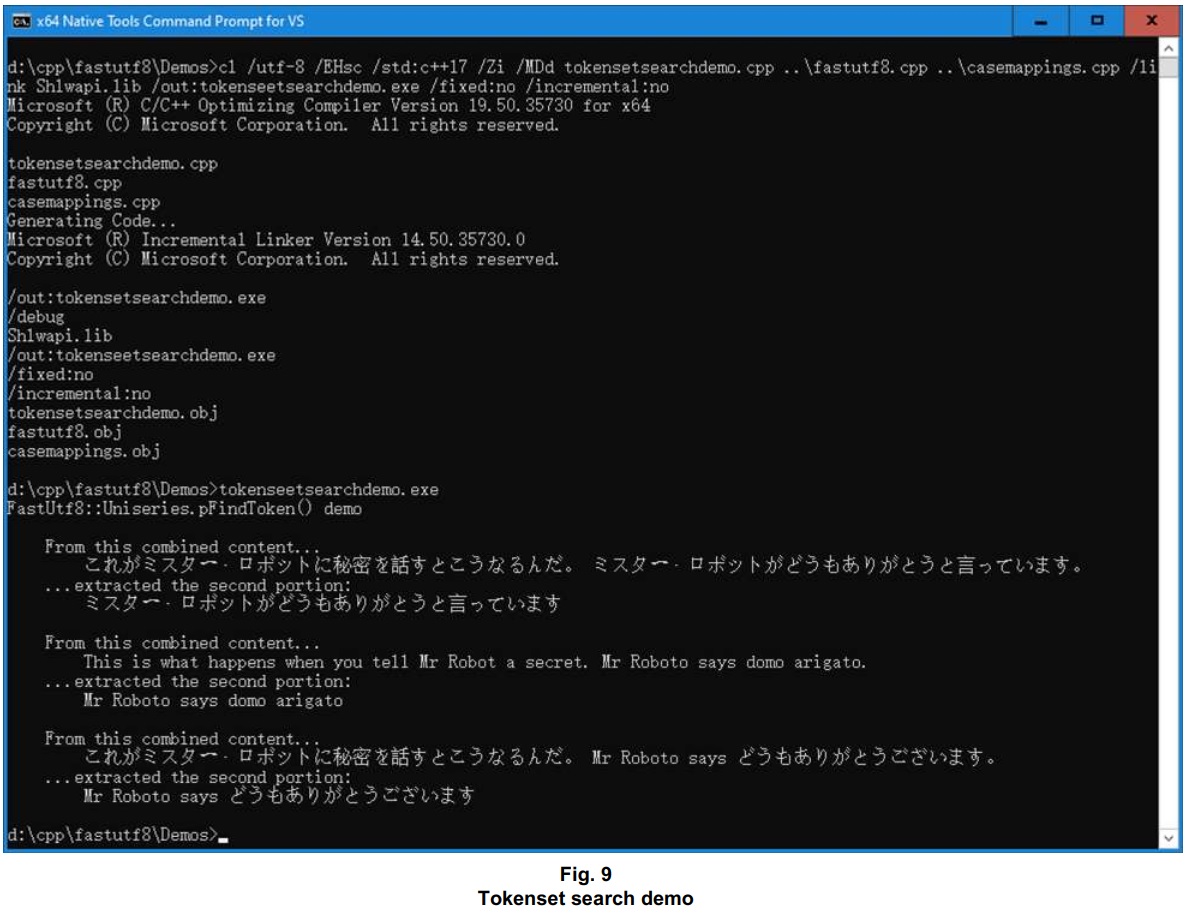
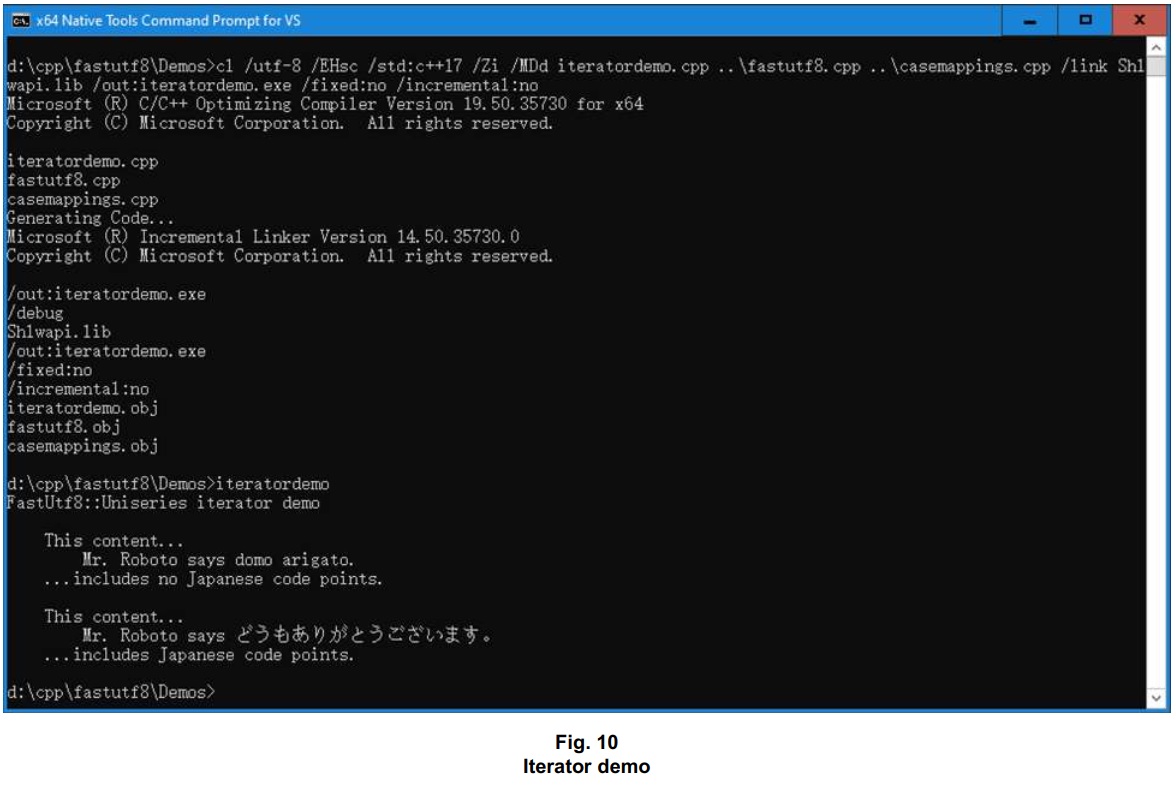
Much of the source code under GitHub > kirkjkrauss > FastUtf8 > Demos showcases functionality not to be found using std::string, including a tokenset search demo that searches mixed-language content for mixed-language tokens.
There’s also an iterator demo. Though iteration through code points is much slower than iteration through ASCII characters, the FastUtf8::Uniseries iterator has use cases that can come in handy. In the demo, it’s used to seek code points that reside in one or another of the ranges for representing Japanese content, as part of a function that indicates whether or not given content is in Japanese.
Static Uniseries methods include size and length determination and case folding, as demonstrated via the StaticMethodsDemo code.
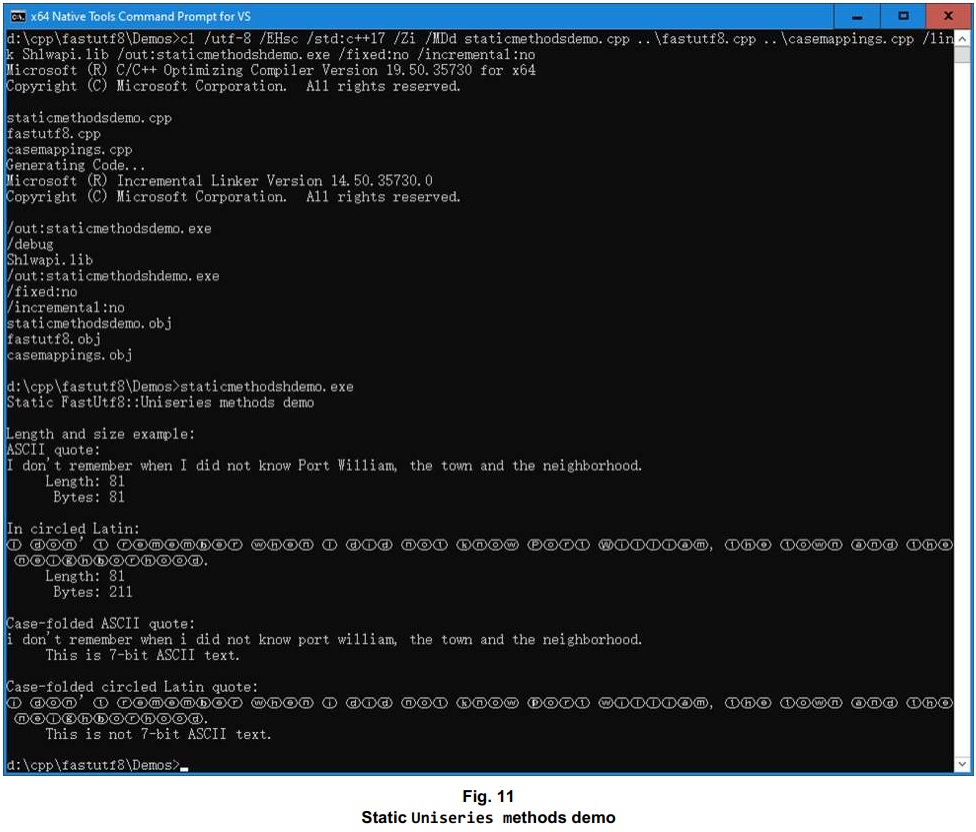
Other Uniseries features include case-sensitive and case-insensitive methods for whole-content comparison, partial-content comparison, and matching wildcards. The HandyFunctionalityDemo code includes examples of what can be done using those methods. The demo also provides another example use case for the Uniseries::pSeparate() method.
The whole-content comparison methods include an operator== that’s part of the Uniseries class, along with a Uniseries::caseCompare() method. The case-sensitivity of operator== depends on the Uniseries metadata, but ::caseCompare() is always case-insensitive.
One form of partial-content comparison, available via the Uniseries::contains() method, is essentially a full-text search that returns a Boolean result: the UTF-8 equivalent of the classic ASCII “if (strstr())” logic that was based around the C standard library. The difference with FastUtf8 is this: where the if statement adds a little complexity over and above the full-text strstr() search, the ::contains() method eliminates the overhead of determining an index to be returned. If you need an index or pointer, you can look it up using the ::find() or ::pFind() method, respectively. There never has been a C language standard for a case-insensitive length-limited variant of strstr(). The Uniseries::contains(), ::find(), and ::pFind() methods can be case-sensitive, length-limited, both, or neither – it’s up to the flag settings you choose for your Uniseries object’s metadata.
The matching wildcards methods are based on my UTF-8-ready routines for matching wildcards published last year. What’s new in matching wildcards, this year, is built-in case-insensitive functionality. As with the other content comparison methods, you get length-limitation or case-sensitivity options based on the Uniseries flags.
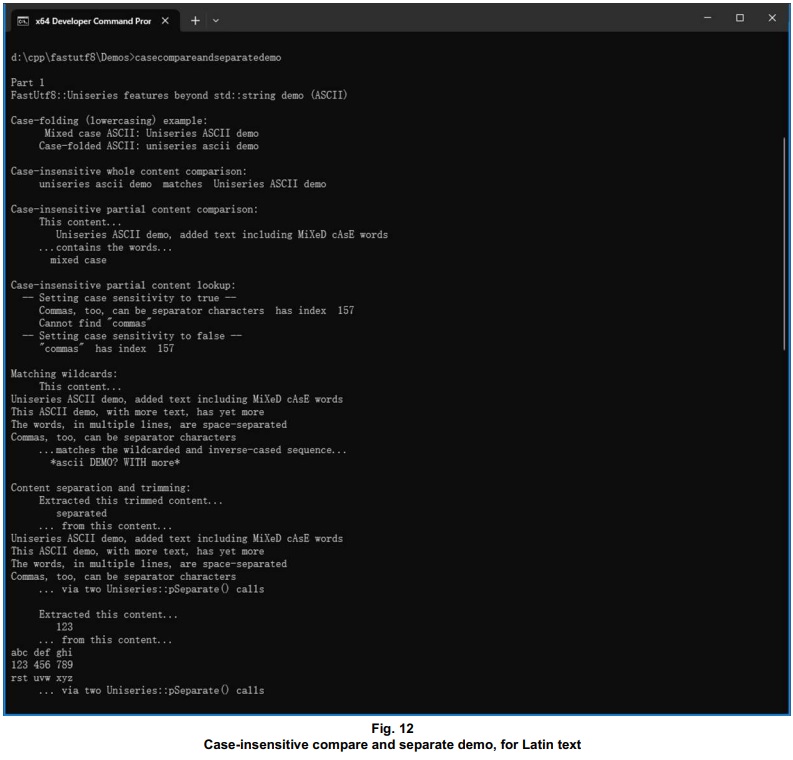
The above screenshot represents Part 1 of the handy Uniseries features demo. Part 1 has a focus on content that could just as well have been handled by ASCII-only methods. In its Part 2, the demo does similar operations as in Part 1, but with multi-byte code points. The demo continues with an example of recognizing 7-bit ASCII text as such, and then converting 8-bit ASCII to UTF-8.
Because this demo involves natural language scripts not readily presentable at the Windows command prompt, these screenshots capture the Windows Terminal instead. It can be set up with a comma-separated list of fonts to display most any UTF-8 content. If the “question-mark-in-diamond” symbol appears, that means another font might need to be added to the list, but there aren’t very many of those symbols shown here.

Tokenset Search and Targeted Wildcard Search Demos
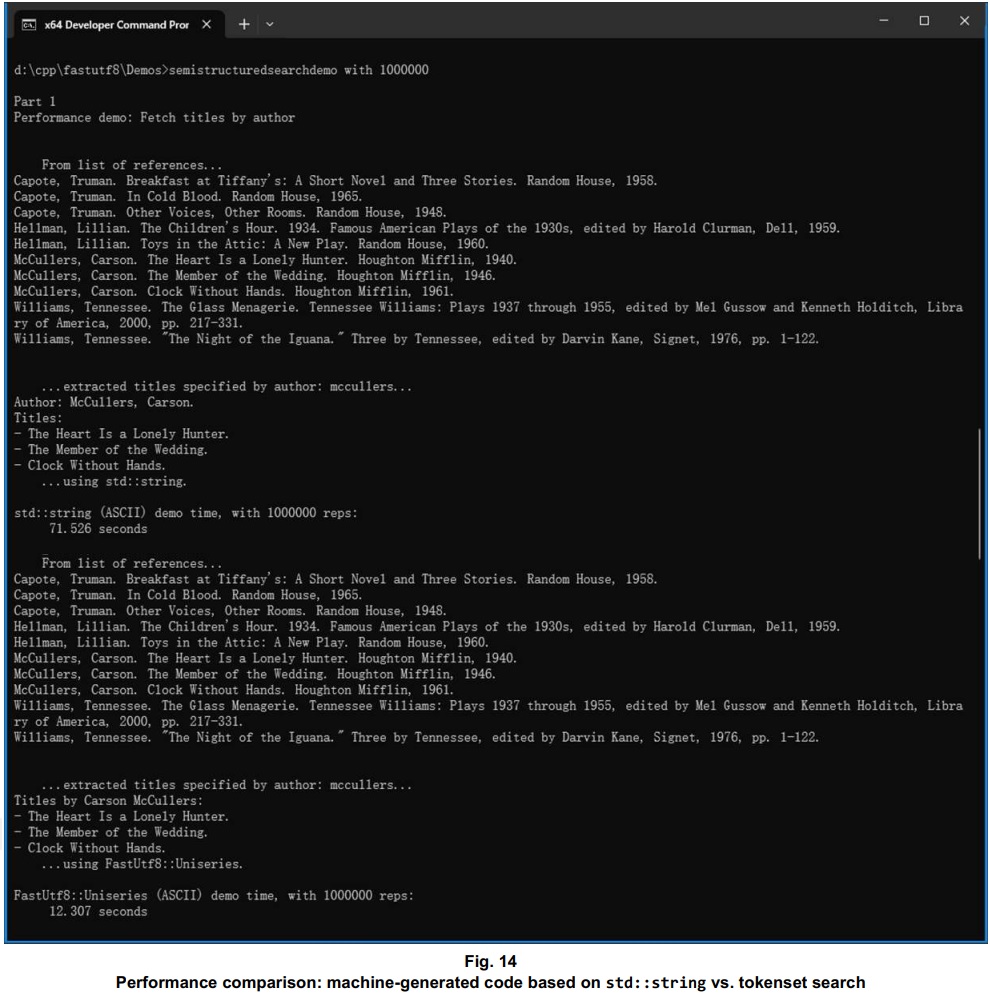
Like the case compare and separate demo of the last couple of screenshots, there are two parts to the semistructured search demo, too. For a search through semistructured data, this demo arranges a performance comparison against prior methods. For the demo’s Part 1, I got code based on those prior methods by entering this into Google:
code a c++ function that accepts two buffers declared as char *, where one buffer comprises an author's last name, and the other buffer comprises a list of MLA references for individual authors, and where the function finds any first matching author among the references, so that for all list entries matching that author, the function creates a std::string comprising the author's first name, last name, and a list of titles among the MLA references, where the initial last name matching is case-insensitiveThe resulting machine-generated code included two functions: a toLower() function, and a more complex function that I renamed to become FetchTitlesByAuthorUsingStdString(). To set up a performance comparison with that machine-generated code, I coded similar functionality using the FastUtf8::Uniseries methods, in a single, relatively simple function that I named FetchTitlesByAuthorUsingFastUtf8Uniseries(). I also put together a series of MLA references, as a data set to be passed into the functions being compared along with a user-specified number of repetitions so as to accumulate timings for performance comparison.
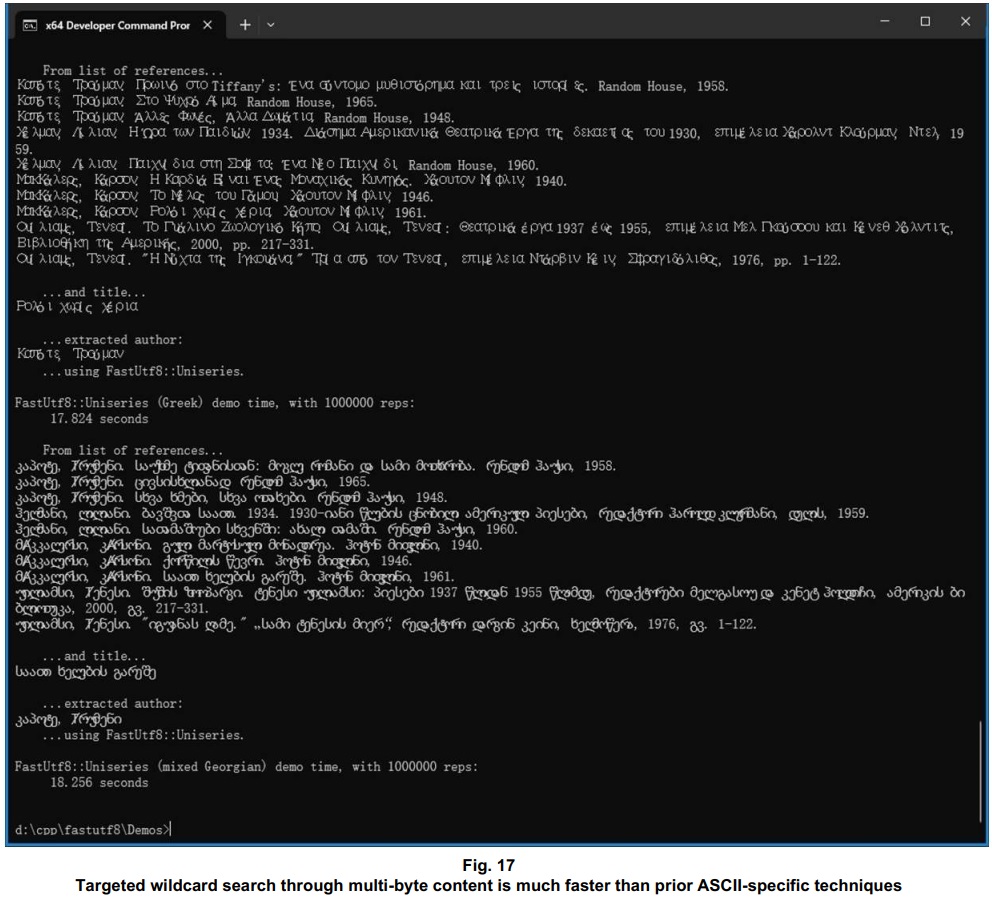
One functional difference came about just because I was using tokenset search for Part 1, via the Uniseries::pSeparate() method. That is, because there was no extra performance penalty of rearranging an MLA entry’s content to place the author’s first name ahead of the last name, that’s what I got the FetchTitlesByAuthorUsingFastUtf8Uniseries() function to do. This FastUtf8 functionality outperforms the machine-generated std:::string-based functionality by ~5x. The Uniseries-based code can come across better yet, given a larger set of MLA entries.
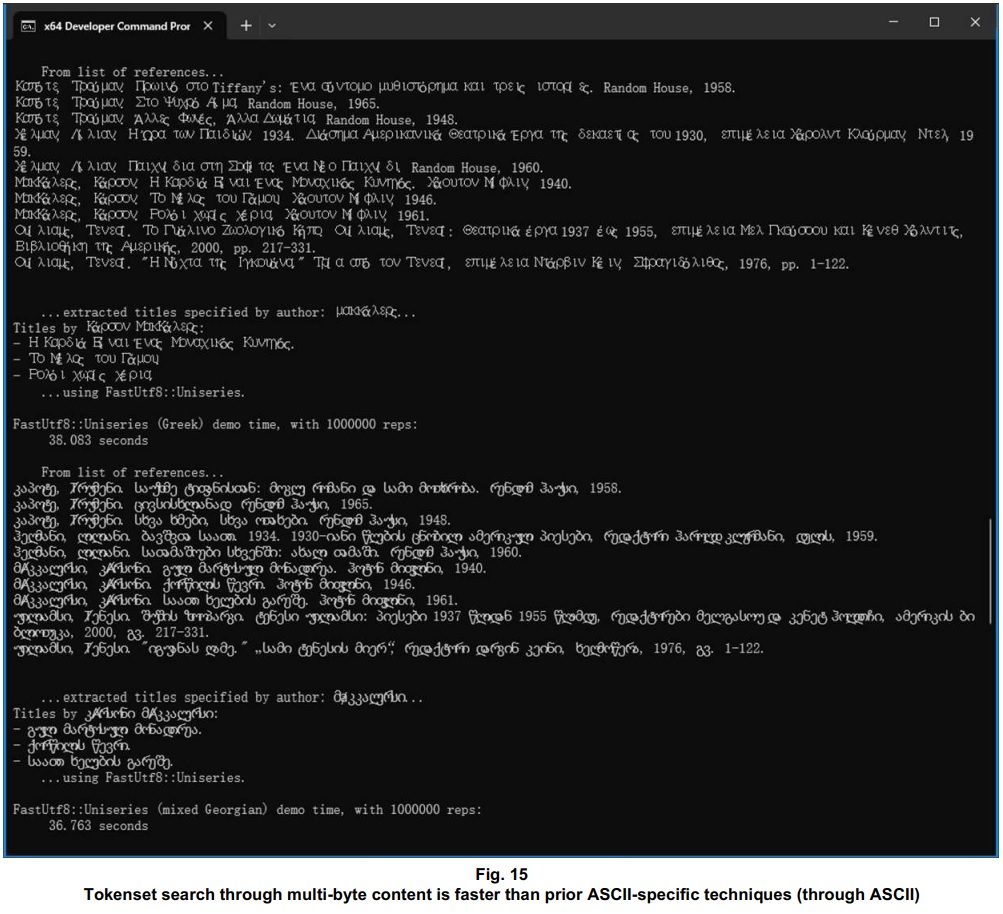
With the demo content translated into Greek, and into (mostly) Georgian, the Uniseries-based code still significantly outperforms the std:::string-based code handling the equivalent ASCII content. The improvement over the prior ASCII-specific techniques, across the range of international content provided in this demo, is consistently ~2x – from one language to another.
Part 2 of the semistructured search demo incorporates case-insensitive targeted wildcard search. Using the same set of MLA references as in the demo’s Part 1, the targeted wildcard search is given a search pattern that looks like...
\n*, *. ‹title›...where a passed-in book title is appended at the pattern’s end. To get some code to do the same thing based on prior techniques, I entered this into Google:
code a c++ function that accepts two buffers declared as char *, where one buffer comprises a title, and the other buffer comprises a list of MLA references for individual authors, and where the function finds any first matching title among the references, so that for a first list entry matching that title, the function creates a std::string comprising the author's name, where the initial title matching is case-insensitive
The resulting machine-generated code included a function that I renamed to become FetchAuthorByTitleUsingStdString(). I named my equivalent FastUtf8-based function FetchAuthorByTitleUsingFastUtf8Uniseries(). My function is so simple that its code includes no loops at all, just a couple of small if statements.
Listing Three
// Given a title and a list of MLA-style references, performs a case-
// insensitive search and extracts the name of the author corresponding to
// any first match.
//
FastUtf8::Uniseries FetchAuthorByTitleUsingFastUtf8Uniseries(
uint8_t *puzTitle, uint8_t *puzReferences)
{
FastUtf8::Uniseries sReferences(puzReferences);
FastUtf8::Uniseries sTitle(puzTitle);
FastUtf8::Uniseries sAuthor;
uint8_t *puzAuthorFirst;
uint8_t *puzAuthorLast = nullptr;
// Prepare a wildcarded search string to match a line, within a list of
// MLA-style references, where the title matches "clock without hands",
// with wildcards in place of the author's last name and first name.
FastUtf8::Uniseries sSearchPattern("\n*, *. ");
sSearchPattern += puzTitle;
// Prepare a set of tokens for slicing the author's name from the rest
// of the line. There is only one token in this set.
FastUtf8::Uniseries sTokenSet(".");
// Get pointers to the first and last code points within the first title
// that matches the search pattern.
puzAuthorFirst = sReferences.casepFindWild(sSearchPattern);
if (puzAuthorFirst)
{
puzAuthorLast = sReferences.pFindToken(puzAuthorFirst, sTokenSet);
}
// Construct a Uniseries from the content between the pointers.
if (puzAuthorLast && puzAuthorLast > puzAuthorFirst)
{
sAuthor.fromSlice(puzAuthorFirst, puzAuthorLast);
}
else
{
sAuthor = "No match found for ";
sAuthor += puzTitle;
}
return sAuthor;
}
This example combines tokenset search with targeted wildcard search. In it, a search pattern is set up, for the targeted
wildcard search, by appending the first inbound parameter (puzTitle) onto a query designed to fit that title’s position in
the inbound puzReferences content. Next, the code constructs a tokenset comprising a single "." token. With that setup
accomplished, we reach the call to ::casepFindWild(), which performs a case-insensitive targeted wildcard search and
returns a pointer to the match on the first ‘*’ wildcard – that’s the location of the author’s last name. Given that pointer
as a starting location, the tokenset search finds the subsequent ".", to get a pointer to the end of the author’s first name.
Finally, this little function returns a Uniseries object constructed from the slice of content between the pointers, or it
returns a "No match found" message in case the title isn’t among the inbound content.
The Design of FastUtf8’s Targeted Wildcard Search
The Uniseries::pFindWild() and ::casepFindWild() method for targeted wildcard search are built on the legacy-C-style Wild[Len][Case]FindUtf8() functions. Those functions are designed based on the UTF-8-ready C/C++ function for matching wildcards that I published last year.
The difference between matching wildcards and targeted wildcard search is like the difference between operator== and full-text search. A function for matching wildcards compares “wild” input (which may have wildcards) against “tame” input (no wildcards) and returns true or false, depending on whether the inputs match. A function for targeted wildcard search scans content for a match against a search pattern that has wildcards in it – but the function doesn’t start checking for a match until it finds content that fits the beginning of the search pattern.
The code for matching wildcards is separated into two loops. One loop walks through a prospective match prior to encountering any ‘*’ wildcard. Its performance is similar to the performance of other like-for-like code point comparisons, except that the wildcard check happens with each iteration. When that loop finds a ‘*’ wildcard, it passes control to the other loop, which continues the code point comparisons with the added overhead of handling incomplete matches. In those cases, that loop backtracks to check on further prospective matches on the remainder of the “wild” content.
To implement targeted wildcard search, my approach was to build it around the matching wildcards algorithm while keeping that code as intact as possible. The original two loops remain much as they were, but there are two more loops positioned ahead of them. The loop immediately ahead scans the content for the first prospective match on the search pattern as a whole. When it finds a matching code point, it passes control to the first loop for matching wildcards. If that portion of the content turns out to not match the search pattern, control goes back to that content-scanning loop.
Ahead of all of that logic comes a first loop that handles any wildcards at the beginning of the search pattern. Why would a search pattern begin with a wildcard? Suppose you want to code a simple function to search content based on a pattern provided via user input. The user may or may not hand your code a search pattern that contains a wildcard – but to get output from a targeted wildcard search, you need a wildcard that’ll prospectively match a target. To make sure you’ve got one, a reasonable thing to do is to tack a ‘*’ onto the beginning of the input: that is, to concatenate the input onto a sufficiently large buffer that starts out with just the ‘*’ in it (or use operator+). You can pass in that buffer, as the search pattern for the targeted wildcard search, resting assured that the search will provide a sensible result since it has at least one wildcard to attempt to match.
I won’t say that this four-loop arrangement is simple – but I think it’s about as simple as it can be, just the way it’s coded. Every line of the code deals in a common bunch of state info that must be set up correctly, both on the way into and on the way out of each loop. Refactoring the loops into separate functions would do nothing to reduce complexity or to improve understandability; rather, the refactoring would forward all that state among situations whose context would surely become relatively unclear. As the function now operates, an initial ‘*’ wildcard sets up its first loop to pass control directly to its last loop: the one that’s supposed to get reached after a ‘*’ wildcard. This, like the other paths that may be taken during processing, seems reasonably clear (at least to me) from the arrangement of the function’s overall logic and from comments in the code.
So how did my short function with the long name – FetchAuthorByTitleUsingFastUtf8Uniseries() – perform, relative to the std::string-based function I got using Google? On my machine, for a million repetitions, the Google-generated code took 50+ seconds to handle the task. The simple FastUtf8::Uniseries-based code of Listing Three handled the same task, with the same million repetitions, in well under 10 seconds.
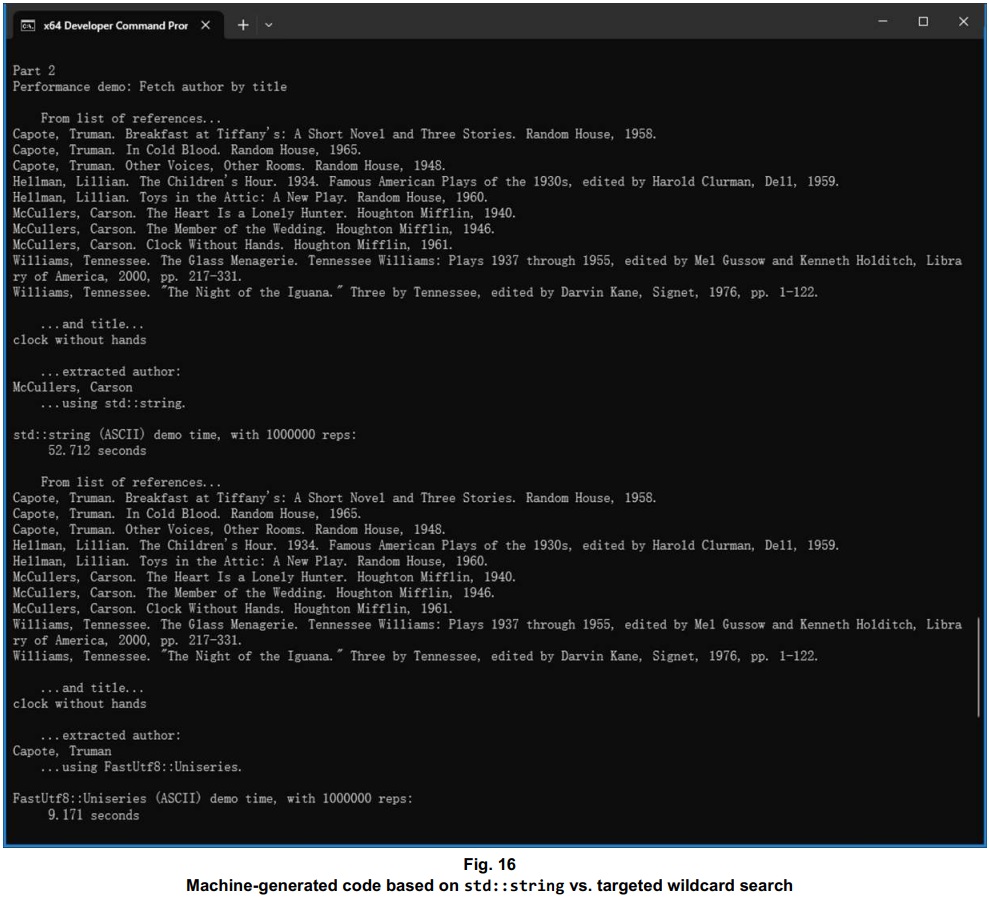
Even given a multi-byte translation of the same MLA references, and of the book title to look up, my little function handled those million repetitions almost 3x faster than Google’s std::string-based function handled the untranslated ASCII content.
Two questions remain: since FastUtf8 is new, how reliable can anyone expect it to be? And what about apples-to-apples method-by-method performance comparisons, without the “special handling for ASCII” trick that’s built into the Uniseries methods? With those questions in mind, let’s turn our attention to the testing approach I’ve taken.
Tests and Timings
Because legacy-C-style functions do nearly all of the content handling for FastUtf8, the test program for FastUtf8 targets just those functions. There are tests for every data-intensive UTF-8 technique described above. To build the test program, you can enter a command similar to the one used in Fig. 6 (for Linux) or Fig. 7 (for the demo programs on Windows) – but you enter it from the FastUtf8 directory and compile the testutf8.cpp file instead of a demo. To enable performance comparison against the FastWildCompare() function for ASCII text, the build (by default) looks for that function. For the builds shown here and in Fig. 6, I’ve provided its source code in fastwildcompare.cpp. Simply firing up the test program, however, simply runs the test set – you get no accumulation or reports of timings for performance comparison.

There’s only a subset of the testcases for which performance comparisons get arranged for any run: specifically, those that involve ASCII content and that have a C standard library equivalent for comparison. You can set up the relevant tests for a given number of repetitions, using the command line argument with, followed by that number of reps.
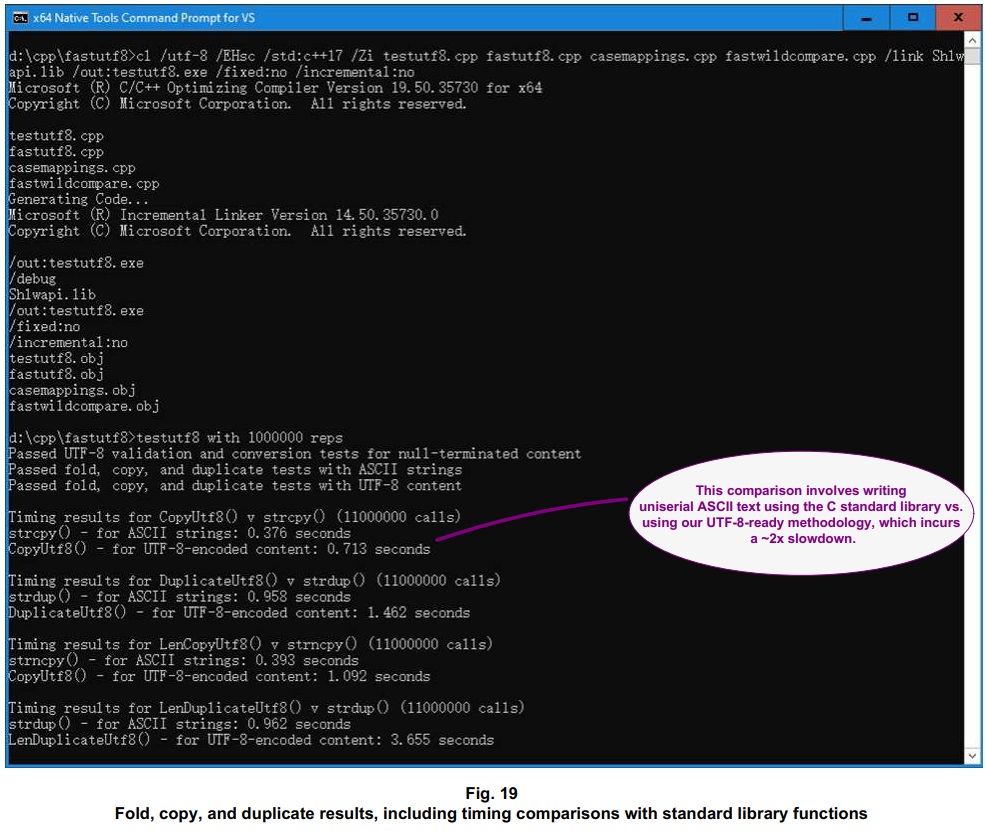
For tests that involve copying and comparing content, the test program accumulates timings for our UTF-8-ready functions and for the C standard library routines most similar to them. Timings are accumulated just for ASCII-compatible content, to arrive at apples-to-apples results. However, the tests also include UTF-8 content for our UTF-8-ready functions, without accumulating timings related to that content.
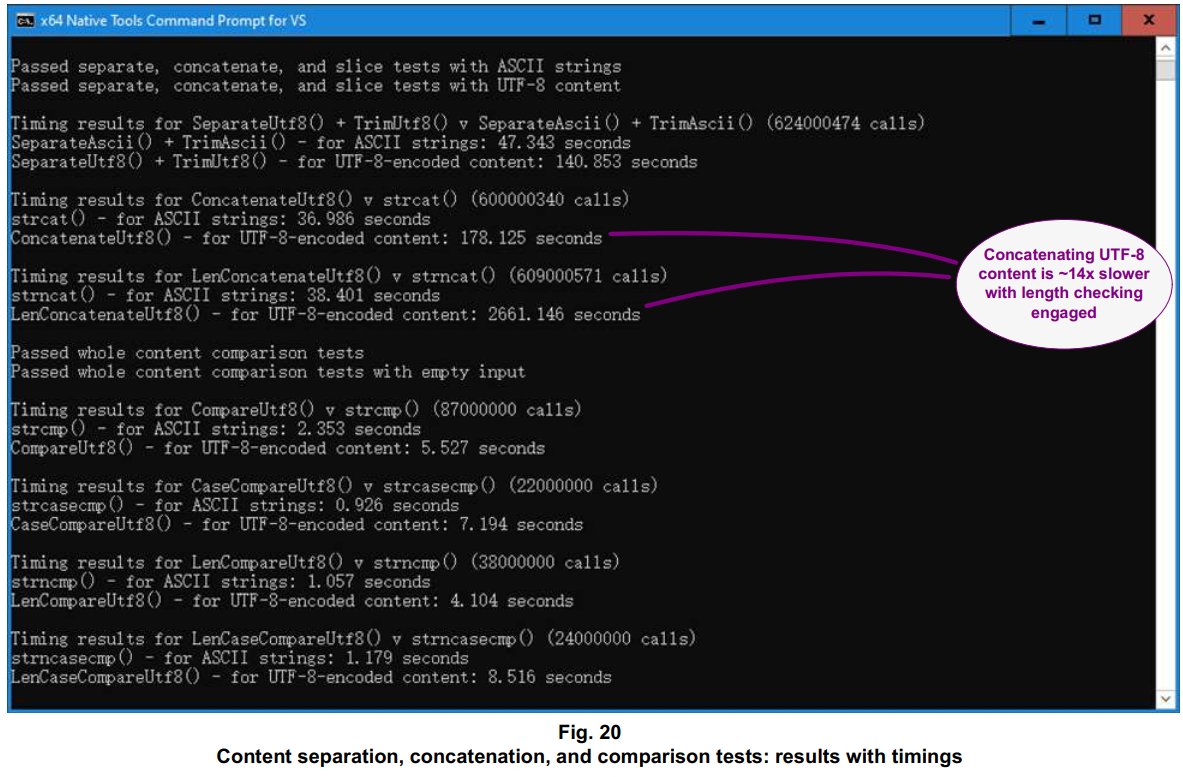
For some of the tests that involve case-insensitive and length-limited full-text search, there’s not an equivalent C standard library routine. The test program accumulates timings for other similar ASCII routines instead. As with the copying and comparing tests, timings are accumulated just for ASCII-compatible content.
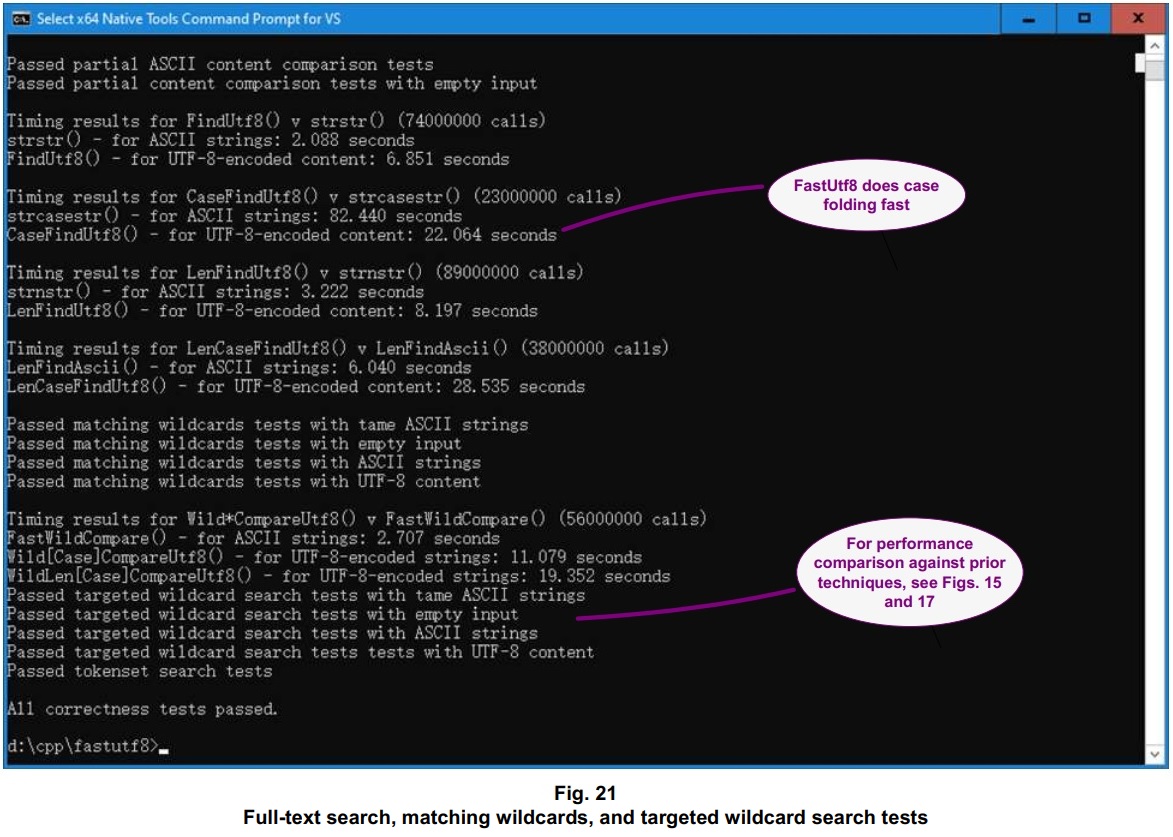
Key takeaways from the timing comparisons:
- In a situation where content is copied, i.e. for contiguous memory writes, the included routines that walk through UTF-8 content typically add a ~2x slowdown over ASCII-specific code;
- Greedy case folding, as done by these UTF-8-ready routines, outperforms the up-front lowercasing typically done with prior methods for ASCII – typically by ~4x;
- Functions that work with null terminators significantly outperform those that check length limits – typically by >10x; and
- Since prior techniques for targeted wildcard search and tokenset search are hard to find, timing comparisons for handling of semistructured data may have to be set up case by case. Those timing outcomes may vary, of course.
Regarding how well the FastUtf8 code has been tested, the nitty-gritty aspects of testutf8.cpp are explained throughout the comments in that source file. Overall, the literal number of tests run depends on complexity of the function under test. For example, there are nearly 300 tests for targeted wildcard search, compared to 36 tests for tokenset search. The tests are designed to cover corner cases and to involve a wide range of UTF-8 content. The targeted wildcard search tests are derived from the tests for matching wildcards, which have been accumulated based on input from many people among the software development community over quite a few years. Those original matching wildcards tests also are included, for the ordinary matching wildcards functionality testing done in testutf8.cpp. There’s also a test set for exercising content separation, concatenation, and slicing in various arrangements, a test set that does case-folding along with content copying via the various included functions, a whole-content comparison test set with nearly 300 testcases, a test set that creates and compares content slices with over 300 testcases, a test set for validation testing, a test set for 8-bit ASCII conversion, and a bunch of other tests.
Does that mean FastUtf8 is tested well enough for use in production code? There’s nothing like arranging your own tests, whether you’re using FastUtf8, std::string, or any other package for working with natural language content. Every package will have caveats – certainly the standard ones do. If a package acts in a way you might not have expected, you might nevertheless find ways to work with it. Maybe the right answer to the question of whether any package is tested well enough comes down to this: is it tested well enough to choose it over other options? It’s with that degree of reliability as a goal that I’ve composed the bundle of tests in testutf8.cpp.
The use of declarative queries as part of semistructured data handling in C/C++ is a sort of open field. Many possibilities can come to mind besides tokenset search and targeted wildcard search. The code simplicity and performance benefits of those search techniques, combined with their ease of applicability across natural languages, may well lead to further developments in the realm of declarative functionality.
The FastUtf8 source code is available at GitHub > kirkjkrauss > FastUtf8. The above source code listings are extracted from that code, including code from the FastUtf8.cpp file and from files in the Demos path. The listings are formatted using the SyntaxHighlighter library, copyright (c) 2004-2013, Alex Gorbatchev.
All other materials copyright © 2026 developforperformance.com.
C++ and its logo are trademarks of the Standard C++ Foundation. Windows® and Visual Studio® are trademarks or registered trademarks of Microsoft Corp. Unix® is a registered trademark of The Open Group. Linux® is a registered trademark of Linus Torvalds. Ubuntu® is a registered trademark of Canonical Ltd.