Matching Wildcards – UTF-8-Ready – in Go, Swift, and C/C++
By Kirk J Krauss
There’s Lots of Stuff Here
- Optimized, tested, paste-in-and-use functions for matching wildcards, based on a C/C++ implementation that’s been re-implemented in Rust, UTF-8-ready in these programming languages:
- Go: Case-insensitive wildcard matching over rune slices – all the necessary source code appears below;
- Complete source code, including a fast wildcard matching implementation for ASCII text, plus correctness and performance tests, is available at GitHub > kirkjkrauss > MatchingWildcardsInGo.
- Swift: Greedy case-insensitive wildcard matching over Strings – the source code appears below;
- A case-sensitive implementation plus complete source code including tests is available at GitHub > kirkjkrauss > MatchingWildcardsInSwift.
- C/C++: null-terminated-only and length-checked implementations – works standalone for case-sensitive use, or with your choice of Unicode libraries for case-insensitivity – the source code appears below;
- Helper routines for walking and comparing code points, suitable for the matching wildcards algorithm or for other UTF-8 handling, including a routine for getting a count of a string’s code points;
- Complete source code, including an implementation that takes that code point count as a length parameter, plus test code, is available at GitHub > kirkjkrauss > MatchingWildcardsUtf8ReadyInC.
- For all implementations: adaptations of the complete ASCII test set originally shared with – and informed by suggestions from – many contributors among the C/C++ developer community, and
- A UTF-8 test set adapted from the test set coded in Rust, targeting matching wildcards in internationalized / symbolic content.
- Also included here:
- Thoughts on performance considerations, coding style, compile-time and debug-time gotchas, and testing approach.
- Performance comparison against the existing Go implementation, also based on my algorithm, by Gert Drapers.
- Runtime analysis findings for the C/C++ code, including a discussion of the history of runtime analysis tools and their potential for today’s development scene.
- Actual timings, based on 1,000,000 repetitions of 200+ tests: among these programming languages, how much speed have I gotten out of the algorithm?
Why All Here In One Writeup?
This is a story about portability. Nowadays most talk of portability centers on cross-platform portability: the sort that matters to software of the accounting or word processing variety. This story is about cross-language portabiility: the sort that matters to techniques, data structures, and algorithms.
This story also is about what our choice of programming language can mean, not just for coding, debugging, and testing but also for thinking about what matters for each of those steps. How to best arrange testing in Go, debugging in Swift, and coding for UTF-8 enablement in C/C++ are language-dependent factors. Task-specific design need not be limited that way. Moreover, getting an algorithm to perform well in more than one programming language can help us understand how to best work with languages that have differing strengths. We can pick up insights about how our choices, among programming languages and tools, may be influencing our thinking.
That makes this a story about a project and a philosophy. The methods I’ve applied toward internationalization of matching wildcards have arisen from the way I think about implementation. Making the resulting internationalization concept available to a wider audience has been quite an interesting experience. Maybe you’ll find that overall story interesting too.
Finally, this is a story of a bit of innovation looking for a community of developers that might appreciate it. It’s the kind of story that’s become normal for my innovations. I’m told that may way of thinking, or at least my code based on it, lacks style. I’m not told this in quite those terms; to be more accurate, I’ve sometimes stood accused of not knowing the programming language in which I’ve been programming. On what grounds? The question of whether I’ve developed something novel, testable, useful, or speedy has never been at issue. Instead, the grounds for that accusation always turn out to be just a matter of style.
A high school buddy of mine had this saying: “When you’re finger pointing, you have three pointing back at you.” To illustrate, he’d stick out an index finger, as if to point, then pat its unextended companion digits. Among Rust developers, there are arbiters of innovations worthy of sharing among the community. Those folks have been considerate enough to arrange a code review for me. I learned that for my algorithm to be acceptably coded, it would have to be coded in a way that would break it, at compile time, or that would require it to be tagged as unsafe. A newbie may think that something like the algorithm could be implemented, to run in maybe only double the time, by adding – to the most complicated part of the current code – some mechanism that would somehow share state involving copies of the inbound strings. Why would anyone who knows Rust suggest any such thing?
To rephrase that last question more broadly, why should style matter more than functionality? My style makes its way into all the code I develop, no matter the programming language. Indeed, my argument is that it’s because style can transcend language that it can serve as a basis for cross-language portability. Shall stylistic concerns trump internationalization, performance, and ease of transmitting a concept across programming languagues, all at once?
Do you prefer practicality over trendiness? It’s called being a nerd, redneck, or hippy. A few of us can confess that we qualify for all three epithets, and developers often used to take credit for the first of them. If some of us don’t find ourselves fashionable enough nowadays to please other developers, it’s not because we’ve changed. And it’s not because the development of algorithmic solutions needs to change, either.
Despite whatever style I’ve lacked, my first correct algorithm for matching wildcards, published in 2008, opened doors instead of getting itself shut out. Back then there certainly were existing methods for matching wildcards, for ASCII text strings in C/C++, so it’s not as if I was breaking new ground. My only claim to algorithmic improvement, at the time, was the specter of a stack overflow that might’ve happened because the existing methods were recursive. I couldn’t point out any real-world examples where my 2008 code truly fixed a crash or otherwise had some obvious impact. Yet once that code got published in Dr. Dobb’s Journal, for a (very) short while I had an easy time getting more code published. I also was invited to speak at the Software Development Best Practices Conference, year after year, and to demonstrate the runtime analysis tools that I was then developing, until the Global Financial Crisis brought that beneficial conference series – plus more generally, I think, quite a bit of guidance offered by a broad range of experience and perspectives across the software development community – to an end. Until then, I was given leeway to speak on pretty much any topic of my choice at those conferences. For the last couple of talks, I chose to speak about innovation that matters.
Submitted for your consideration: do the code listings below, or any part of the thinking behind them, involve innovation that matters? In the history of this algorithm’s development, nothing before has had the reach of the internationalization of matching wildcards. The experience of bringing the technique across from Rust to three programming languages also has brought to mind ideas, concerns, and observations that I share in the sidebars below. On several prior occasions, my work on matching wildcards has led me into interesting ways to think about software development generally. The array of interesting thoughts, this time, takes the cake.
Elements of Pattern Matching Style
I’m happy to have participated, at least in a small way, in a tradition that favors code that “runs on real hardware with real performance.” To that catchphrase, I would add that real style never forgets the reality of the hardware. Those of us who develop for performance can’t settle for stylistic trends contrary to this principle.
My goal in developing code for matching wildcards has never been to make it look chic or to fit its methodology to someone’s standard. The design is a matter of algorithmic logic coupled with thorough testing. Sensible priorities, all relevant to style, involve correctness, performance, portability, and best testability for both correctness and performance. Here are some highlights about how that plays out for matching wildcards:
- One stand-alone drop-in function does all
This makes the code a snap to paste in and call. In the days when matching wildcards was done recursively, no one even thought to code up more than one function or data structure to do the job. The newer logic-driven functions admittedly are lengthier, yet they still have just two inputs, a single Boolean output, and no internal portions worth calling independently but rather a cohesive purpose that can be intuitively grasped. When such a function also is thoroughly tested and unlikely to ever need modification, what would be the use of breaking it into pieces? To do so would likely incur overhead passing parameters on the stack, gratuitous complexity, and less understandability.
- Array-style or pointer-based string treatment (the way to not break a portable algorithm)
In several programming languages, iterators have become the norm for most string handling. There may sometimes be good reasons for this, given use cases where strings, vectors, lists, and other data structures might be handled alike. I’ve coded that way, myself, mainly when I’ve needed to fit my approach with language-specific methods for cross-platform portability. But the idea that iterators make string handling “generic” strikes me as false advertising. Just how generic is any string handling code, exactly, if it doean’t handle the UTF-8 standard? Some of the world’s most popular string iterators just can’t handle it. Among those that can, they too often get extolled by developers who don’t bother to test their code for UTF-8-readiness anyway. Either way, following coding “standards” is no substitute for adequate testing. But in calling out the insistence (among some developers) on iterators for the false advertising that it is, I’m just scratching the surface of the problem.
I’m surprised to have to even point out the limitations of iterator-based string handling. I feel obliged to delve into it, because I keep getting labeled as incompetent just for my willingness to develop code that handles strings in more traditional ways. There seems to be a pervasive worship of some so-called “generic” “standard” – even in the absence of any real standard from one programming language to another – so, then, it’s a non-generic non-standard whose adherents fail to acknowledge the downsides of their fanatacism.
The downsides of so-called generic code are many, and language-dependent, too. For C/C++ they include a tendency toward reduced performance compared to what’s possible with time-tested approaches, disenfranchisement of those who don’t use the Latin character set, loss of developer experience implementing or debugging their own algorithms – and that’s worse than a mere undermining of code quality. Along with that, I’ve observed a general forgetfulness of (or aversion to) most any useful data structures and techniques that don’t come with prepackaged accessors and solutions. I’m thinking of the lack of even straw-man standards for tries, skip lists, multidimensional data sets, and graphs, along with the range of operating-system-provided thread- and fiber-mananagement calls, fast file system access, methods for virtual memory management, etc.
In other words, while I’d be among the first to admit that iterators serve useful purposes, I don’t see why a developer must be limited, in any way, by the mere fact that they exist. Iterator-based approaches have yet to make a great deal of C++ code UTF-8-ready. And anyone working on matching wildcards, even for ASCII text, would be ill-served relying on iterators.
That’s because pattern matching over strings presents challenges for iterators, no matter the programming language – and those challenges vary wildly from language to language. With Rust, for example, the compiler’s borrow checker imposes a limit of one mutable iterator per string, but most logic-based algorithms for matching wildcards would call for two. The only workarounds require either added complexity involving multiple iterators over multiple copies of the inbound strings, or an unsafe tag besmirching some or all of the routine. Assuming we prefer the route of added complexity, for our matching wildcards function that complexity would get added right into the code that begins with the comment, in the second loop, indicating it’s the not so simple part. I placed that comment in the original C/C++ code as a note, meaningful at least to myself, suggesting precisely to not attempt any change toward increasing its complexity. And so I wouldn’t try tackling that myself.
There are plenty of examples of iterator challenges, particularly for complex pattern matching, beyond the Rust world. In Go, backtracking via iterators isn’t straightforward, but for matching wildcards, we need to backtrack whenever a partial match turns out to be only partial. Any function that can best be coded based on random access to an array might as well be coded just that way – and that’s reason enough for today’s programming languages to still allow such a thing.
I think the only reason why arrays and pointers have fallen out of favor is because smart pointers, iterators, and the not-really-generic code that accompanies them are free to use, while the most capable static code checkers and runtime analysis tools have always been pricey. Dogmatism won’t lend you competence, but mastering appropriate tools gives you an edge, or better yet, a chainsaw and an excavator. I use PurifyPlus, which can combine error checking with code coverage analysis for a single run, to check my C/C++ executables for both array-bounds and pointer-related runtime errors. That tool arrangement, given a routine that comes with a complete test set like we have for matching wildcards, can demonstrate an implementation to be quite safe. Unfortunately, in tandem with the denouncement of arrays and pointers, tools like PurifyPlus have fallen out of favor to the point that getting hold of them, at all, has become quite a challenge.
- String length checks
The UTF-8 code points comprising a string can have varying lengths. By far the most common technique for representing a string, across most programming languages that can represent it as a set of UTF-8 code points at all, is to treat it as such, even if it holds ASCII text. This commonly means storing the content in memory in conjunction with a length and a capacity but without a null terminator. A terminating element at the end a UTF-8-encoded string would make little sense, in most circumstances. “Walking” the string means knowing the size of each element. Knowing the element sizes and the overall string length, the code that walks the string knows when it reaches the end, so there’s no need to check for a terminator. In the absence of a terminator, best performance can be realized via length checks. Our matching wildcards algorithm is “greedy” in the sense that it walks no more than necessary, so that comparing, for example...
“*sip*” vs “mississippi”
...the computation skips last portion of the “tame” string – that is, the “pi” in “mississippi” – altogether. That optimization can be either insignificant or quite significant, depending on the situation. Consider...
“pi*” vs “pi”
“pi*” vs “pie”
“pi*” vs “pizza”
“pi*” vs “pizzicato”An obvious alternative to the string length check would be to first tack null terminators onto both strings. That would entail walking the “pizzicato” string up front, to tack on the terminating null, prior to any wildcard check. Such an approach would miss the entire point of reaching for an optimized algorithm. Tacking on a null terminator may indeed call for reallocating the string’s memory and making a complete copy of its content.
The repetitive length checks I’ve coded, on the other hand, only look as though they’re expressing repetitive calculation. Because they’re concise, they make for readable code, plus the absence of a variable assignment may serve as a hint to the compiler to perform optimizations involving them. At the very least, a length check, once performed during a loop iteration, should end up with a cached result.
- For UTF-8, up-front conversion to indexed content
Since greedy algorthmic processing matters so much to me, why do my UTF-8-ready implementations in Rust and Go require up-front conversion of both input strings into slices of fixed-size elements? This is, in fact, a consideration that’s given me reason to do some thinking. The short answer is that I don’t know of a straightforward way to implement my algorithm, in those languages, so that it’ll handle UTF-8 content faster than it does.
- Portable testcases instead of standardized ones
Some developers have expressed concern over my use of file- or package-scope variables to store test case selections and to accumulate performance data, any my thereby neglecting this or that standard testing protocol. Most of my testcases for matching wildcards came into existence along with the original C/C++ code for the algorithm itself. My approach, all along, has been intended to ensure a low-latency method to accumulate timings, for algorithm implementations whose timings are being compared, using the very same tests that serve for correctness validation. The approach incorporates timings for every wildcard scenario and has proven itself to be portable with little effort on my part. The testing arrangement is now useful for five different programming languages and for both ASCII and UTF-8. No one else has shared any UTF-8-readiness testcases for matching wildcards, as far as I know.
In case you’re interested in setting up testing for matching wildcards yourself, you can invoke any test setup you like, incorporating my test strings – and it shouldn’t be much trouble to arrange. Since the output for all my correctness tests gets rolled into three displayable results, those lines of code that output those results would make fine spots for invoking most any testing agent of your choice. Why expect a test set styled for cross-language portability to do more than that for your language-specific arrangement?
If you were to be challenged figuring out which of the string comparisons is failing, you’d likely be far more challenged figuring out why it’s failing. Debugging pattern matching code is best done, I think, using a tool that can display at least two memory windows (one for each inbound string), the call stack, a shortish set of variables with their values, and a longish set of conditional breakpoints, all somewhere alongside the code. Some of the browser-provided debuggers for JavaScript stand out in meeting most of these needs. Unless a kernel-mode driver or an unusual platform calls for matching wildcards, I can think of no sensible reason to favor a less capable native code debugger.
Adapting UTF-8-Ready Pattern Matching Code from Rust to Other Programming Langauges
Computing systems are used throughout the world – but well over half of the world’s population doesn’t use English to communicate. There are billions of people who don’t ordinarily read and write using the Latin character set. For that reason, our 21st century world communicates using UTF-8. It’s the standard encoding for web pages, email, and non-legacy databases, operating systems, and programming languages.
Matching wildcards is a staple among computing methodologies. Does a system administrator, software developer, or power user exist, anywhere on Earth, who’s unfamiliar with the common wildcard syntax? Commonly, the wildcards include the ‘*’ symbol, which can match any number (0+) of text elements (characters or code points), and the ‘?’ symbol, which can match exactly 1 element. Wildcard matching scenarios arise across a broad range of use cases, such as text processing and manipulation in IDEs and other editors, database and search engine queries, big data / analytics, log analysis, static code analysis, runtime analysis, firewall and other cybersecurity rules, file system operations and commands, scripting language processing, infrastructure management, as well as test, deployment, project management, and application-specific automation.
When I needed code for matching wildcards in the Rust™ programming language, I realized that the language provided a straightforward way to apply my own optimized ASCII-specific algorithm to UTF-8 content. I’d already developed a portable C/C++ implementation. It accepts a “wild” and “tame” string, checks for a wildcard match between them in just one function call, and returns a Boolean result. Converting that C/C++ code to Rust was easy, given the language’s support for logic based around array-style indexing. Rust differs little from old-fashioned C in all the ways that matter to pattern matching performance.
From there, the thought process leading to UTF-8 enablement went like this: Since the ordinary Rust String is UTF-8-encoded, why not find a way of indexing into that content? For UTF-8, the indexed elements could have different sizes – but must they? What would it take to transfer a Rust String’s content into an array-style set of 32-bit elements? The answer, in Rust, is provided via an arrangement known as a Boxed Slice.
With that coded, it was on to testing. I’ve collected a test set for matching wildcards in C/C++ over several years, with the input of many developers. The test strings are suitable for both the ASCII and UTF-8 Rust implementations. For complete UTF-8 testing, code points comprising multiple bytes require testing against the ‘?’ and ‘*’ wildcards’ single-byte code points. Those “wild” bytes are 0x3A and 0x3F, respectively. A string may contain a multiple-byte code point, where the low-order seven bits, of one of the bytes in the code point, also happen to be interpretable as a 0x3A or a 0x3F. (The code point would have to be interpreted as a “half-ASCII” character – that is, masked with 0x7F – for the confusion to arise.) If the routine for matching wildcards were to consider one of those bytes a wildcard, just because it turned up within a multiple-byte code point, the result might be a false positive or a false negative. A false positive result is possible with incorrect wildcard matching against a code point that includes more than just those seven bits. A false negative result is possible when the rest of the code point doesn’t match the bits that remain if those 7 bits were to be mistaken for a separate wildcard code point.
Testing for the UTF-8-ready Rust implementation went virtually without a hitch. The Boxed Slice indexing worked just as expected. I made the Rust code and complete test set available on GitHub – perhaps the first freely available UTF-8-ready code for a matching wildcards routine. It’s a win for internationalized text comparison.
Access to indexed elements of fixed size, created from a UTF-8-encoded string, is hardly a feature of Rust alone. Similar arragements are just as readily made in Go, C++. and even legacy C code. That’s an even bigger win. Swift, moreover, provides a flexible method of indexing into UTF-8 content. In Swift, no up-front step of converting the content into fixed-size elements is necessary for implementing the matching wildcards algorithm. Certainly we’d like to match that capability of Swift in our UTF-8-ready C/C++ impementation, too. That’s what I’ve done.
Those are the only significant implementation differences across the three programming languages. The only usability difference involves whether an up-front conversion, of strings to arrays of fixed-size elements, is needed. Other than that, the algorithm, the techniques on which it’s based, the set of tests for it, and the overall testing arrangement are all virtually identical across languages.
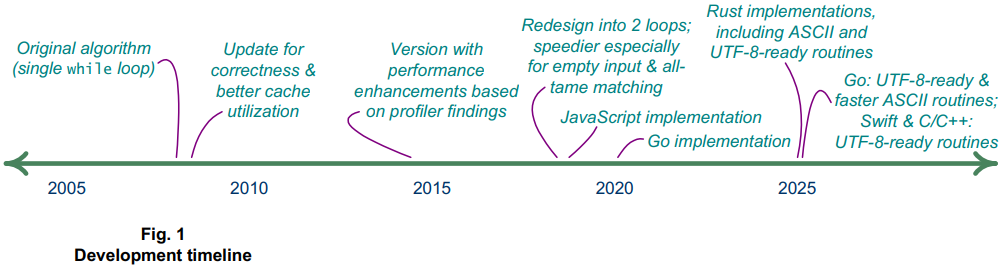
When I shared the Rust code for matching wildcards, I included a history of the algorithm and its implementations. The history can now be summarized via the timeline shown toward the top of this page. My first routine for matching wildcards, described in Dr. Dobb’s Journal in 2008, is still built into a runtime analysis toolkit that I use. That is, it’s part of the PurifyPlus™ filter manager.
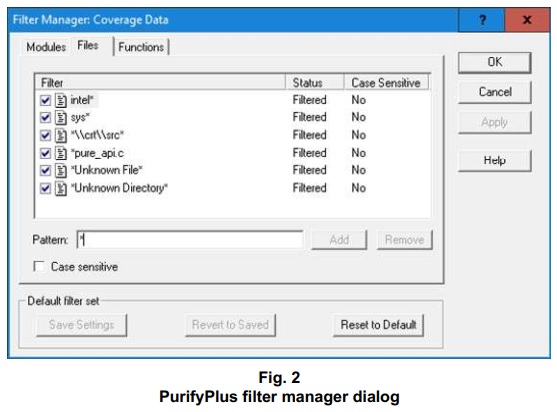
I’ve included some more PurifyPlus screenshots in the discussion of my new C/C++ code for matching wildcards, below. My reliance on truly helpful tools is one of several best practices that have led to my concept of the elements of pattern matching style listed at right.
What could anyone consider very wrong about those elements of pattern matching style? Well, just the idea of developing for performance rather than conformity can install fear. Jorge Luis Borges, in his short story of 1947 titled “Los teólogos,” has articulated what I consider the most adequate explanation: “Las herejías que debemos temer son las que pueden confundirse con la ortodoxia.” In English, it can be expressed this way: “The heresies we have to fear are those that may be confused with orthodoxy.” This can apply to any group dynamic that revolves around convention so comfortingly that unconventional perspectives, particularly those that show signs of quality, get deprecated.
Borges’ story, set in the context of the Medieval Inquisition, is about a harmless notion that gets forcibly banned, only to be replaced by an opposing one that turns deadly – and an acclaimed apologist for dogmatic authority must take the blame. Whenever I get tired of waiting, hand poised on mouse, for a wildcard search across a meager million or so records – something the computer could do perfectly well in a matter of eyeblinks, if not for some oversealous sense of compliance popular among some developers – that’s deadly too. What’s being killed is my time.
Technological innovation always has been driven by throwing aside convention, to some degree. The emergence of new programming languages, along with the paradigms surrounding them, has done nothing to change the human factors underlying innovations and enhancements. The improved performance and internationalization of matching wildcards, coming from a developer whose work has so thoroughly broken with so many fashions as outlined at right, can help all of us better appreciate the value there can be in diverse points of view.
Matching Wildcards in Go – ASCII Version
In Go, a string is the most common data type used for representing a character sequence. It’s UTF-8-encoded and ordinarily stored on the stack. Passing a string by value involves creating a copy of its header, which comprises the string’s length and a pointer to its content, but the underlying bytes are ordinarily not copied. There’s no null terminator. A terminating element at the end of a UTF-8-encoded string would make little sense, for reasons explained under “String length checks” in the sidebar at right.
What’s worked well for Rust, for matching wildcards, is a set of length checks to replace the terminator checks that appear in the original C/C++ code. The C/C++ code takes advantage of some optimizations based on the fact that the null character is distinct from any other characters in a string. We’re bound to see a slowdown, in any logic-driven Go routine for matching wildcards, involving the need for the length checks plus the loss of those optimization opportunities. My performance tests revealed that slowdown, for both Go and Rust, was minimal compared to the slowdown needed for a UTF-8-ready version.

Go’s strings comprise UTF-8 code points called runes. Lacking rune awareness, a routine still can walk a string, but it must be a string of 7-bit ASCII characters, or the routine will run roughshod over the runes. For matching wildcards, that means incorrect results for internationalized content. Still, there are times when a routine optimized for ASCII text can be useful, so I’m including one on GitHub.
The UTF-8 ready version is based on an up-front conversion step that creates a slice of fixed-sized runes. There’s a utf8.DecodeRuneInString() function that might be more suitable for a greedy approach, but I haven’t figured out a way to fit it very nicely with my algorithm. It doesn’t mesh well with either pointers or index variables. The needed direct rune access, throughout the inbound strings’ content, may entail reliance on Go’s “unsafe” package.
There’s something demotivating about working on code that’s as safe as any yet must advertise itself as unsafe. Possibly Go code for matching wildcards using utf8.DecodeRuneInString(), in a greedy approach, might outperfom the UTF-8-ready code I’ve shared here. Yet Go’s up-front conversion to slices of fixed-size runes is pretty fast, by comparison to what’s possible, say, with Rust. Besides, there’s no need to make any call to decode a one-byte code point, since it’s immediately comparable with the ‘*’ and ‘?’ wildcards. The only reason I’ve had in mind for calling utf8.DecodeRuneInString() has been to get the sizes of the other code points along the way – though that call would’ve added the overhead of actual decoding. Unless or until there’s some lower-overhead way to determine a rune’s size, I wouldn’t expect a huge performance improvement by taking a greedier approach in Go.
The most direct conversion of the C/C++ code into Go or Rust code would’ve called for placing a length check wherever the original code had a null check, at every turn. This would result in added logic that would become positively ugly in the second loop, where we’d have to pile multiple length checks (for both the “wild” and “tame” strings) into an already-complex if statement. I’ve found a way in which logic can be saved by logic: the only substantive change I made to the algorithm, in the Go and Rust implementations, was to cut down on the number of length checks by relying on them once they’ve been done, for each loop iteration. The logic of the second loop was only slightly rearranged to achieve that optimization, but the result is a function that looks considerably more elegant than it would in a “line-for-line translation” from the original C/C++ code. The Rust implementation that resulted, for ASCII text, was almost directly translatable into Go.
The main differences between the Rust code and the Go code for ASCII text are the looping and formatting styles. Go isn’t happy with my usual format. I like spacing the code around snippets that I expect to compile to basic blocks, which make for helpful breakpoints, rather than cram lines tightly, K&R style, as if for publication in book form where saving pages could reduce costs. When setting a breakpoint in rather indented code, it’s all too easy to select the line above or below the one intended, but the debugger disallows a breakpoint on a line that contains only a curly brace. That’s why a spaced-out style can make a difference for those of us who do lots of debugging. (You may notice less of a difference if you have really keen eyesight, or if you’re accustomed to having your concentration interrupted because you use some debugger that has enough machismo to make you type commands just to get state info.)
Slightly more significantly, the for keyword stands in the place where a while keyword appears in C/C++ or Rust. Also, the code is semicolon-free. And each time an index is incremented, a line of code is dedicated to that enterprise. Other than those inconsequential differences, the loop logic in Go is just the same as in Rust. The source code for the fast wildcard matching implementation for ASCII text is available at GitHub > kirkjkrauss > MatchingWildcardsInGo.
Matching Wildcards in Go – UTF-8 Version
As I’ve described above, in place of Rust’s Boxed Slice, which can contain UTF-8 code points as fixed-sized elements, Go provides for a similar data structure known as a rune slice. What’s needed to adapt the ASCII-only Go code to use it? Not many changes at all.
Starting with that ASCII version and converting it for use with slice content, we need only code a simple slice-building step, prior to calling the routine, to convert the inbound strings accordingly, and refer to them instead of the original strings throughout the matching wildcards routine. Voilá, just as with Rust, UTF-8-ready code! The downside is performance: conversion to slices requires an up-front walkthrough, for both the “wild” and “tame” strings. But the up-front performance drag with Go isn’t as severe as with Rust.
For most scenarios, the performance of the matching wildcards routine, itself, isn’t very different from that of its ASCII counterpart. But because that up-front conversion is a bit slow, the ASCII version is probably the way to go, for ASCII text. Listing One provides the code for the UTF-8 version, and Listing Two adds that up-front rune slice setup that consumes a smallish majority of the overall execution time:
// Go implementation of fast_wild_compare_utf8(), for UTF-8-encoded rune
// slices.
//
// Copyright 2025 Kirk J Krauss. This is a Derivative Work based on
// material that is copyright 2025 Kirk J Krauss and available at
//
// https://developforperformance.com/MatchingWildcardsInRust.html
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// https://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// Compares two rune slices. Accepts '?' as a single-rune wildcard. For
// each '*' wildcard, seeks out a matching sequence of any runes beyond it.
// Otherwise compares the slices a rune at a time.
//
func FastWildCompareRuneSlices(rslcWild, rslcTame []rune) bool {
var iWild int = 0 // Index for both input strings in upper loop
var iTame int // Index for tame content, used in lower loop
var iWildSequence int // Index for prospective match after '*'
var iTameSequence int // Index for match in tame content
// Find a first wildcard, if one exists, and the beginning of any
// prospectively matching sequence after it.
for {
// Check for the end from the start. Get out fast, if possible.
if len(rslcTame) <= iWild {
if len(rslcWild) > iWild {
for rslcWild[iWild] == '*' {
iWild++
if len(rslcWild) <= iWild {
return true // "ab" matches "ab*".
}
}
return false // "abcd" doesn't match "abc".
} else {
return true // "abc" matches "abc".
}
} else if len(rslcWild) <= iWild {
return false // "abc" doesn't match "abcd".
} else if rslcWild[iWild] == '*' {
// Got wild: set up for the second loop and skip on down there.
iTame = iWild
for {
iWild++
if len(rslcWild) <= iWild {
return true // "abc*" matches "abcd".
}
if rslcWild[iWild] == '*' {
continue
}
break
}
// Search for the next prospective match.
if rslcWild[iWild] != '?' {
for rslcWild[iWild] != rslcTame[iTame] {
iTame++
if len(rslcTame) <= iTame {
return false // "a*bc" doesn't match "ab".
}
}
}
// Keep fallback positions for retry in case of incomplete match.
iWildSequence = iWild
iTameSequence = iTame
break
} else if rslcWild[iWild] != rslcTame[iWild] && rslcWild[iWild] != '?' {
return false // "abc" doesn't match "abd".
}
iWild++ // Everything's a match, so far.
}
// Find any further wildcards and any further matching sequences.
for {
if len(rslcWild) > iWild && rslcWild[iWild] == '*' {
// Got wild again.
for {
iWild++
if len(rslcWild) <= iWild {
return true // "ab*c*" matches "abcd".
}
if rslcWild[iWild] != '*' {
break
}
}
if len(rslcTame) <= iTame {
return false // "*bcd*" doesn't match "abc".
}
// Search for the next prospective match.
if rslcWild[iWild] != '?' {
for len(rslcTame) > iTame &&
rslcWild[iWild] != rslcTame[iTame] {
iTame++
if len(rslcTame) <= iTame {
return false // "a*b*c" doesn't match "ab".
}
}
}
// Keep the new fallback positions.
iWildSequence = iWild
iTameSequence = iTame
} else {
// The equivalent portion of the upper loop is really simple.
if len(rslcTame) <= iTame {
if len(rslcWild) <= iWild {
return true // "*b*c" matches "abc".
}
return false // "*bcd" doesn't match "abc".
}
if len(rslcWild) <= iWild ||
rslcWild[iWild] != rslcTame[iTame] &&
rslcWild[iWild] != '?' {
// A fine time for questions.
for len(rslcWild) > iWildSequence &&
rslcWild[iWildSequence] == '?' {
iWildSequence++
iTameSequence++
}
iWild = iWildSequence
// Fall back, but never so far again.
for {
iTameSequence++
if len(rslcTame) <= iTameSequence {
if len(rslcWild) <= iWild {
return true // "*a*b" matches "ab".
} else {
return false // "*a*b" doesn't match "ac".
}
}
if len(rslcWild) > iWild &&
rslcWild[iWild] == rslcTame[iTameSequence] {
break
}
}
iTame = iTameSequence
}
}
// Another check for the end, at the end.
if len(rslcTame) <= iTame {
if len(rslcWild) <= iWild {
return true // "*bc" matches "abc".
}
return false // "*bc" doesn't match "abcd".
}
iWild++ // Everything's still a match.
iTame++
}
}
Code for calling the above function, so that it performs both case-sensitive and case-insensitive wildcard matching on the “tame” and “wild” Slices, is included among the correctness and performance testcases on GitHub. The UTF-8 testcases, which also are provided in Listing Four, make use of these lines of code that arrange for case-insensitive wildcard matching:
Listing Two
func test(tame_string, wild_string string, bExpectedResult bool) bool {
//
// ... This is an excerpt of a function called for every testcase ...
//
if bExpectedResult != FastWildCompareRuneSlices(
[]rune(strings.ToLower(wild_string)),
[]rune(strings.ToLower(tame_string))) {
bPassed = false
}
// ... Further test-specific code ...
return bPassed
}
Unusual though a heap allocation failure may be, the above code may have to handle a resulting panic, in case the system can’t arrange to allocate the needed memory blocks, or in case the heap has become corrupted. Panic preparedness may matter especially for production code that may see exposure to malicious input. Otherwise this code can be used, as-is, with or without the ToLower() call that makes the wildcard match case-insensitive.
The test set for matching wildcards in C/C++ was accumulated over several years with the input of many developers. The test strings are suitable for both the ASCII and UTF-8 Go implementations. For testing either of those implementations, a set of identical strings gets passed to the test() function – see Listing Two (above). Listing Three provides an excerpt of some of the tests.
Listing Three
func testWild() {
// ... This is an excerpt of a function that passes strings to the
// above code in test() ...
//
bAllPassed := true
// ...
// Cases with repeating character sequences.
bAllPassed = bAllPassed && test("abcccd", "*ccd", true)
bAllPassed = bAllPassed && test("mississipissippi", "*issip*ss*", true)
bAllPassed = bAllPassed && test("xxxx*zzzzzzzzy*f", "xxxx*zzy*fffff", false)
bAllPassed = bAllPassed && test("xxxx*zzzzzzzzy*f", "xxx*zzy*f", true)
bAllPassed = bAllPassed && test("xxxxzzzzzzzzyf", "xxxx*zzy*fffff", false)
bAllPassed = bAllPassed && test("xxxxzzzzzzzzyf", "xxxx*zzy*f", true)
bAllPassed = bAllPassed && test("xyxyxyzyxyz", "xy*z*xyz", true)
bAllPassed = bAllPassed && test("mississippi", "*sip*", true)
bAllPassed = bAllPassed && test("xyxyxyxyz", "xy*xyz", true)
bAllPassed = bAllPassed && test("mississippi", "mi*sip*", true)
bAllPassed = bAllPassed && test("ababac", "*abac*", true)
bAllPassed = bAllPassed && test("ababac", "*abac*", true)
bAllPassed = bAllPassed && test("aaazz", "a*zz*", true)
bAllPassed = bAllPassed && test("a12b12", "*12*23", false)
bAllPassed = bAllPassed && test("a12b12", "a12b", false)
bAllPassed = bAllPassed && test("a12b12", "*12*12*", true)
// ... The tests continue ...
if bAllPassed {
fmt.Println("Passed wildcard tests")
} else {
fmt.Println("Failed wildcard tests")
}
}
For complete UTF-8 testing, code points comprising multiple bytes require testing against the ‘?’ and ‘*’ wildcards’ single-byte code points. Those “wild” bytes are 0x3A and 0x3F, respectively. A string may contain a multiple-byte code point, where one of the bytes in the code point also could be confused with a 0x3A or a 0x3F if their lower-order 7 bits comprise the portion being compared. The code point would have to be interpreted as a 7-bit ASCII character – that is, masked with 0x7F – for the confusion to arise. Test cases that check for these multiple-byte scenarios, including a few test strings whose code points include the 0x3A and 0x3F bytes, are provided in this testUtf8() routine.
// Correctness tests for a case-sensitive arrangement for invoking a
// UTF-8-enabled routine for matching wildcards. See relevant code /
// comments in test().
//
func testUtf8() {
bAllPassed := true
bTestingUtf8 = true
// Simple correctness tests involving various UTF-8 symbols and
// international content.
bAllPassed = bAllPassed && test("🐂🚀♥🍀貔貅🦁★□√🚦€¥☯🐴😊🍓🐕🎺🧊☀☂🐉",
"*☂🐉", true)
if bCompareCaseInsensitive {
bAllPassed = bAllPassed && test("AbCD", "abc?", true)
bAllPassed = bAllPassed && test("AbC★", "abc?", true)
bAllPassed = bAllPassed && test("⚛⚖☁o", "⚛⚖☁O", true)
}
bAllPassed = bAllPassed && test("▲●🐎✗🤣🐶♫🌻ॐ", "▲●☂*", false)
bAllPassed = bAllPassed && test("𓋍𓋔𓎍", "𓋍𓋔?", true)
bAllPassed = bAllPassed && test("𓋍𓋔𓎍", "𓋍?𓋔𓎍", false)
bAllPassed = bAllPassed && test("♅☌♇", "♅☌♇", true)
bAllPassed = bAllPassed && test("⚛⚖☁", "⚛🍄☁", false)
bAllPassed = bAllPassed && test("⚛⚖☁O", "⚛⚖☁0", false)
bAllPassed = bAllPassed && test("गते गते पारगते पारसंगते बोधि स्वाहा",
"गते गते पारगते प????गते बोधि स्वाहा", true)
bAllPassed = bAllPassed && test(
"Мне нужно выучить русский язык, чтобы лучше оценить Пушкина.",
"Мне нужно выучить * язык, чтобы лучше оценить *.", true)
bAllPassed = bAllPassed && test(
"אני צריך ללמוד אנגלית כדי להעריך את גינסברג",
" אני צריך ללמוד אנגלית כדי להעריך את ???????", false)
bAllPassed = bAllPassed && test(
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.",
"* શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે * શીખવું પડશે.", true)
bAllPassed = bAllPassed && test(
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.",
"??????????? શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે * શીખવું પડશે.", true)
bAllPassed = bAllPassed && test(
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.",
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે હિબ્રુ ભાષા શીખવી પડશે.", false)
// These tests involve multiple=byte code points that contain bytes
// identical to the single-byte code points for '*' and '?'.
bAllPassed = bAllPassed && test("ḪؿꜪἪꜿ", "ḪؿꜪἪꜿ", true)
bAllPassed = bAllPassed && test("ḪؿUἪꜿ", "ḪؿꜪἪꜿ", false)
bAllPassed = bAllPassed && test("ḪؿꜪἪꜿ", "ḪؿꜪἪꜿЖ", false)
bAllPassed = bAllPassed && test("ḪؿꜪἪꜿ", "ЬḪؿꜪἪꜿ", false)
bAllPassed = bAllPassed && test("ḪؿꜪἪꜿ", "?ؿꜪ*ꜿ", true)
if bAllPassed {
fmt.Println("Passed UTF-8 tests")
} else {
fmt.Println("Failed UTF-8 tests")
}
}
A Reason to Compare Performance Based on Non-Optimized Code
When I began testing this new Go code, I added in a performance comparison against the existing routine from https://github.com/gertd/wild and got an unreasonably speedy set of results.
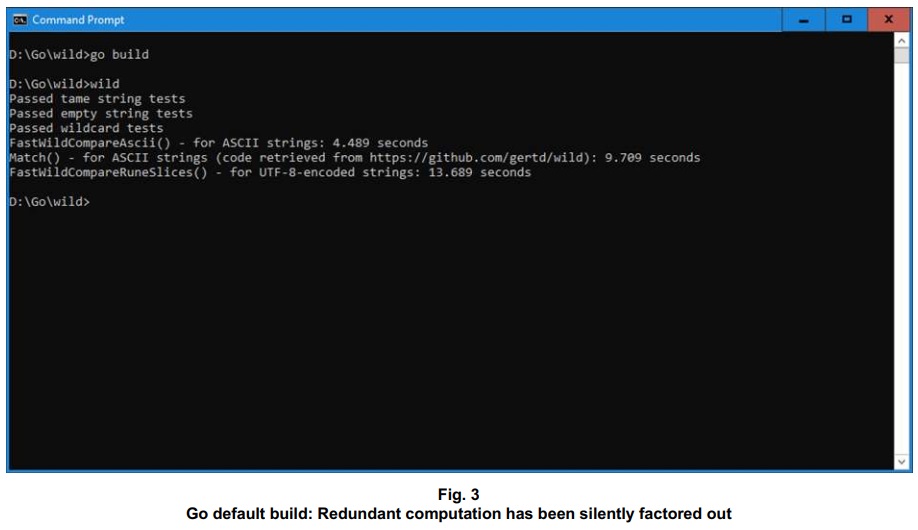
I couldn’t believe that my humble AMD FX-8300™ 3.3 GHz computer had just performed so many tens of millions of matching wildcards operations per second. I’ve spent more than enough hours studying the disassembly and performance profiling call graphs for my routines for matching wildcards to imagine that they might really perform this blazingly fast on this hardware. Trimming off some fat at compile time is well and good, but surely some of the meat is getting trimmed, too, for the timing results shown above. I knew that Go had to be leaving out some processing, but how? I found myself scratching my head, but only for a little while.
Before Go existed, I invented a tool for identifying code that wastes time performing redundant computation. Part of my idea was to detect redundant function calls and point them out. I envisoned this as a runtime analysis tool, for several reasons:
- Some code, such as stress testing, load testing, and consistency checks, has a genuine need for redundancy;
- Runtime analysis can catch more real redundancies than static checks, I think, such as those that may involve computed data;
- The developer should get to decide whether any source code is necessary or not; and
- Reporting for necessary redundancies can be switched off via a filter, which might provide control of the sort depicted in Figure Two.
My Go performance tests are necessarily redundant, because the differences in timings show up best when they’ve been accumulated over the course of a many, many string comparisons. When I saw that those tests were running too quickly to be for real, my old invention came to mind, so I sought it out in the relevant documentation. I found that, indeed, the Go compiler includes my invention’s static analysis equivalent. Only the developers of the Go compiler don’t call it “silently factoring out redundant computation.” More euphemistically, they call it “common subexpression elimination,” a moniker that used to apply to instruction-level code such as a series of hard-coded additions or subtractions just within a basic block. As if applying data flow analysis to eliminate entire function calls is a minor stretch beyond that!
Whatever this compile-time functionality may be named, as of this writing (late 2025) I haven’t seen a way to switch it off without disabling optimizations altogether. I also haven’t seen a way to get the compiler to admit that it’s factoring out function calls that I consider necessary. When I disable optimizations, I do get results that look as though all my code has run as intended.
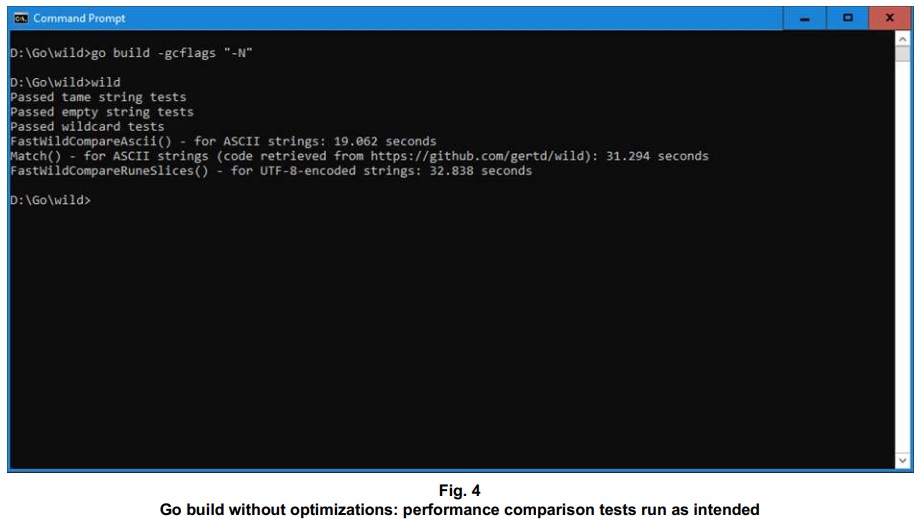
Compiler behavior that eliminates redundant function calls isn’t limited to Go. Function call elimination seems to be getting built into compilers for C/C++ and into Java’s JIT compilation. But what of a compiler that eliminates function calls by default, without even pointing out that’s what it’s doing?
In some situations, silently eliminating redundancy could be catastrophic. For example, among both operating systems test teams and PC manufacturing engineers, I’ve seen a common system stressor known by some folks as a march test. The test typically involves multiple concurrent xcopy (Windows®) or cp -R (Unix® / Linux®) commands, set up so that a fileset is duplicated in a repetitive march across the system’s storage media. Suppose the entire march test, including the xcopy implementation itself, was coded as a package and compiled using the default options. Apparently the result would have most every outward appearance of a march test – except for real evidence of heavy storage media activity – but for those who don’t pick up on that, the result could turn out to be something like an April fool’s joke. If the test team were to miss the compiler’s quiet arrangement to fake the march test’s operation, the joke could play out at the expense of the system’s customers.Whoever can fully trust a build system that regards some source code, no matter how thoughtfully developed, as wasteful? Silently factoring it out would seem to reflect a mindset, behind the system, such as...
- Developers using our tools are so frequently incompetent that our static checker and compiler had better do everything possible to correct coding errors; and
- On top of that, those developers are so averse to criticism that we’d best not only cover up the corrections, but also reword such rude terminology as “redundant computation” anywhere they might run across it.
Some Go aficionados might suggest that if I’m a competent developer, I shouldn’t need to code redundancy into my testing strategy. I’d respond with a suggestion of my own: anyone who’s got the bandwidth to act as apologist for the Go compiler might consider reapplying it to come up with a couple hundred million unique and meaningful test strings for matching wildcards. That’ll guarantee that the compiler won’t eliminate any redundancy that it might otherwise deem wasteful.
For an apples-to-apples comparison of matching wildcards implementations, Go has provided the most compelling set of reasons I’ve yet seen for disabling optimizations for the executable code being compared. You can modify the main.go file, and add code around the lines with the Can add ... comments, to collect performance timings for the calls needed to invoke a matching wildcards routine of your choice and to show its timing results.
Regarding Gert Drapers’ implementation, it passes my default ASCII tests perfectly. I didn’t quickly get it to pass every test I’ve now shared, though possibly I’ve failed to notice something such as a setup step that may be needed. I haven’t debugged it to find out. It seems almost to be a drop-in-and-use routine, like my own, though I had to find and paste in code from multiple files to get as far as I got with it.
One thing the Go compiler gets right is the setup of rune slices. This is way faster than the equivalent operation with Rust. The overall timing is competitive that of my UTF-8-ready C/C++ routine, even though that routine uses a greedy approach for walking through UTF-8 content. The C/C++ code must cope with the possibility of embedded nulls, in my opinion, for safety reasons. On the other hand, a rune slice created from a hard-coded string can be prechecked at compile time. That’s the sort of result I’m happy to get from static code analysis – syntax and semantic checks, and built-in linting – as applied via the go build command.
Matching Wildcards in Swift – ASCII (-Only) Need Not Apply
There’s a lot to be said for a programming language that provides not only for flexible indexing into UTF-8 content, but also for robust case folding options for internationalized string comparisons. Swift also provides for a controllable level of data race safety checking plus additional compile-time and runtime checking for memory-safe code. The compiler displays (quite) verbose output, so there’s little chance of it surprising the watchful developer.
Swift has long been – and still is – an evolving language. I developed some Swift code about a decade ago that relied on a sort of self-awareness built into the Strings' index variables, so that my code could find predecessor and successor characters directly from them. An upgrade to Swift itself broke that code. Nowadays, when you’d like a simple description of how to find the index of a character using Swift, you might find code for doing it in four different versions of the language, all in one writeup.
Debugging Swift Code on Windows?
Earlier this year (2025) when I set out to work on code for matching wildcards in Rust, I’d just finished a clean install of Visual Studio Code®. The available extensions for Rust and Go both installed and worked in VS Code, without a hitch. Go code, even built with default (over)-optimized settings, is debuggable without the typical anomalies that often challenge those of us who debug optimized code in, say, C++.
With Swift, the story is radically different. The first thing I noticed: there’s currently more than one Swift extension available for VS Code. Either of those extensions relies on a further extension related to LLVM. With either configuration, I can point VS Code at my debug build, and it’ll find my source files and allow me to set breakpoints. But that’s about the whole story. When I try starting a run, it insists on a rebuild step, makes itself busy for a little while – then nothing more seems to happen. It doesn’t even complain about anything.
I tried wrestling with settings and Internet-supplied suggestions for about an hour, then took a shot at it using the other Visual Studio (Community Edition). After all, with a Swift build, you can set an option that’s supposed to produce CodeView-style debug data, which I imagine would do the trick for VS Community or Professional. It didn’t work. I went searching directories for anything resembling debug data, such as a pdb file. For my two moderately small source files, a debug Swift build produces not less than 1.25 gigabytes of files in various subdirectories under \.build, but none seems to include debug data I can use with Visual Studio Community, no matter what I try.
Considering the option of setting up a Linux virtual machine with an installation of Swift (with its huge builds) and a debugger for it (among which I’d imagine I’d again have to choose), I began instead to debug via logfiles and just kept on with it. You can find evidence of that debugging experience – a little code that might be handy in case such a debugging method becomes useful again – among my Swift source files for matching wildcards on GitHub. The method works as effectively as any, but it sure is clunky.

With all that flux happening in the Swift programming language, I’m unsurprised to find that it now comes across (at least to me) like a tinkerer’s trove. I mean no disrepect, and I don’t intend to suggest that there’s any problematic lack of coherence in Swift. A tinkerer simply has a tinkerer’s way of getting things done. The programming language feels reminicent of a cluttered tool chest, like one retrieved from a sawdusty garage, where with enough rummaging you can find a complete assortment of socket wrench components, sundry screwdrivers, pliers, channel locks, wire cutters and crimpers for various gauges, several drills, trowels, cable stretchers, at least one soldering iron plus a solitary esophagus, sky hook, Ohm meter, etc. Consider just the mechanisms for indexing a String in just one version of Swift (the latest). As you’d anticipate, you can index it like so:
String[myindex]
But then, you also can fill in the square brackets with up to three different index variables – each with its own meaning and special nametag defined within the language. I’m half-expecting to one day find a way to code all[the loop control] in there.
So when I implemented my matching wildcards algorithm in Swift, I knew what to do when it didn’t pass a few of my tests. I just hadn’t gotten specific enough about how I wanted to compare characters. A string like this one...
गते गते पारगते प????गते बोधि स्वाहा
...may look to you as though it contains a snippet from the Prajñaparamita Sutras with a few ‘?’ wildcards mixed in. It looks that way to me, anyway, in both Notepad++ and FireFox. It can be interpreted that way, too, in Swift – but not if your code walks the string using the default indexing arrangement. The wildcards could be there to enable matching, for instance, against multiple sources or renderings of the verse. How to make our Swift implementation recognize them?
By default, Swift will glom content together into bunches known as extended grapheme clusters, and right now, it’s doing that a bit too aggressively to pass my UTF-8 tests for matching wildcards. But never fear: when Swift doesn’t behave as you’d expect, that’s because you’re just seeing the top layer of stuff in the tool chest. When the smaller-gauge crimpers you’re hunting are buried, along with the Ohm meter, it’s time to dig.
What odd Swift tools have I dug up? How ’bout the kitchen variety! I’ve found that you can make Swift code do what most code in other UTF-8-ready languages most always does, by peppering it with unicodescalars and Character keywords. A Character is the thing to tell Swift it’s seeing, when what it’s seeing is a code point it got via its own unicodescalars keyword and you’d like to match case.
If you don’t need a case-insensitive wildcard match, then just the unicodescalars brand of seasoning does the trick. Here’s the code for the case-insensitive implementation; this and the code for the case-sensitive implementation is available at GitHub > kirkjkrauss > MatchingWildcardsInSwift.
// UTF-8-ready Swift routines for matching wildcards.
//
// Copyright 2025 Kirk J Krauss. This is a Derivative Work based on
// material that is copyright 2014 IBM Corporation and available at
//
// https://developforperformance.com/MatchingWildcards_AnImprovedAlgorithmForBigData.html
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// https://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// Case-insensitive Swift implementation of FastWildCompare().
//
// Compares two Strings. Accepts "?" as a single-code-point wildcard. For
// each "*" wildcard, seeks out a matching sequence of any code points beyond
// it. Otherwise compares the Strings a code point at a time.
//
func FastWildCaseCompare(strWild: String /* may have wildcards */,
strTame: String /* no wildcards */
) -> Bool
{
var iWild = strWild.unicodeScalars.startIndex // Index for wild content
var iTame = strTame.unicodeScalars.startIndex // Index for tame content
var iWildSequence: String.Index // Index for prospective match after '*'
var iTameSequence: String.Index // Index for match in tame content
// Find a first wildcard, if one exists, and the beginning of any
// prospectively matching sequence after it.
repeat
{
// Check for the end from the start. Get out fast, if possible.
if strTame.unicodeScalars.endIndex == iTame
{
if strWild.unicodeScalars.endIndex != iWild
{
while strWild.unicodeScalars[iWild] == "*"
{
iWild = strWild.unicodeScalars.index(after: iWild)
if strWild.unicodeScalars.endIndex == iWild
{
return true // "ab" matches "ab*".
}
}
return false // "abcd" doesn't match "abc".
} else {
return true // "abc" matches "abc".
}
}
else if strWild.unicodeScalars.endIndex == iWild
{
return false // "abc" doesn't match "abcd".
}
else if strWild.unicodeScalars[iWild] == "*"
{
// Got wild: set up for the second loop and skip on down there.
repeat
{
iWild = strWild.unicodeScalars.index(after: iWild)
if strWild.unicodeScalars.endIndex == iWild
{
return true // "abc*" matches "abcd".
}
if strWild.unicodeScalars[iWild] != "*"
{
break
}
} while true
// Search for the next prospective match.
if strWild.unicodeScalars[iWild] != "?"
{
while Character(strWild.unicodeScalars[iWild]).lowercased() !=
Character(strTame.unicodeScalars[iTame]).lowercased()
{
iTame = strTame.unicodeScalars.index(after: iTame)
if strTame.unicodeScalars.endIndex == iTame
{
return false // "a*bc" doesn't match "ab".
}
}
}
// Keep fallback positions for retry in case of incomplete match.
iWildSequence = iWild
iTameSequence = iTame
break
}
else if Character(strWild.unicodeScalars[iWild]).lowercased() !=
Character(strTame.unicodeScalars[iTame]).lowercased() &&
strWild.unicodeScalars[iWild] != "?"
{
return false // "abc" doesn't match "abd".
}
// Everything's a match, so far.
iWild = strWild.unicodeScalars.index(after: iWild)
iTame = strTame.unicodeScalars.index(after: iTame)
} while true
// Find any further wildcards and any further matching sequences.
repeat
{
if strWild.unicodeScalars.endIndex != iWild &&
strWild.unicodeScalars[iWild] == "*"
{
// Got wild again.
repeat
{
iWild = strWild.unicodeScalars.index(after: iWild)
if strWild.unicodeScalars.endIndex == iWild
{
return true // "abc*" matches "abcd".
}
if strWild.unicodeScalars[iWild] != "*"
{
break
}
} while true
if strTame.unicodeScalars.endIndex == iTame
{
return false // "*bcd*" doesn't match "abc".
}
// Search for the next prospective match.
if strWild[iWild] != "?"
{
while Character(strWild.unicodeScalars[iWild]).lowercased() !=
Character(strTame.unicodeScalars[iTame]).lowercased()
{
iTame = strTame.unicodeScalars.index(after: iTame)
if strTame.unicodeScalars.endIndex == iTame
{
return false // "a*b*c" doesn't match "ab".
}
}
}
// Keep the new fallback positions.
iWildSequence = iWild
iTameSequence = iTame
}
else
{
// The equivalent portion of the upper loop is really simple.
if strTame.unicodeScalars.endIndex == iTame
{
if strWild.unicodeScalars.endIndex == iWild
{
return true // "*b*c" matches "abc".
}
return false // "*bcd" doesn't match "abc".
}
if strWild.unicodeScalars.endIndex == iWild ||
(Character(strWild.unicodeScalars[iWild]).lowercased() !=
Character(strTame.unicodeScalars[iTame]).lowercased() &&
strWild.unicodeScalars[iWild] != "?")
{
// A fine time for questions.
while strWild.unicodeScalars.endIndex != iWildSequence &&
strWild[iWildSequence] == "?"
{
iWildSequence =
strWild.unicodeScalars.index(after: iWildSequence)
iTameSequence =
strTame.unicodeScalars.index(after: iTameSequence)
}
iWild = iWildSequence
// Fall back, but never so far again.
repeat
{
iTameSequence =
strTame.unicodeScalars.index(after: iTameSequence)
if strTame.unicodeScalars.endIndex == iTameSequence
{
if strWild.endIndex == iWild
{
return true // "*a*b" matches "ab".
}
else
{
return false // "*a*b" doesn't match "ac".
}
}
if strWild.unicodeScalars.endIndex != iWild &&
Character(strWild.unicodeScalars[iWild]).lowercased() ==
Character(strTame.unicodeScalars[iTameSequence]).lowercased()
{
break
}
} while true
iTame = iTameSequence
}
}
// Another check for the end, at the end.
if strTame.unicodeScalars.endIndex == iTame
{
if strWild.unicodeScalars.endIndex == iWild
{
return true // "*bc" matches "abc".
}
return false // "*bc" doesn't match "abcd".
}
iWild = strWild.unicodeScalars.index(after: iWild) // Everything's still a match.
iTame = strTame.unicodeScalars.index(after: iTame)
} while true
}
Calls to the above Swift routines require no up-front steps. That is, Swift allows the algorithm to take a greedy approach, as designed, and you can call either of the Swift functions for matching wildcards using String variables as parameters.
Listing Six
// This function compares a tame/wild string pair via each included routine.
func test(strTame: String, strWild: String, bExpectedResult: Bool) -> Bool
{
var bPassed = true
//
// ... This is an excerpt of a function called for every testcase ...
//
if bExpectedResult != FastWildCompare(
strWild: strWild, strTame: strTame)
{
print("FastWildCompare(\(strWild), \(strTame) failed")
bPassed = false
}
if bTestCaseInsensitive
{
if bExpectedResult != FastWildCaseCompare(
strWild: strWild, strTame: strTame)
{
print("FastWildCaseCompare(\(strWild), \(strTame) failed")
bPassed = false
}
}
// ... Further test-specific code ...
return bPassed
}
What’s been the outcome of wheeling that cluttered tool chest known as Swift into my kitchen, liberally applying all that pepper to my little creation, and getting prepared to devour code points (of my tests for matching wildcards) with greed? I suppose the polite thing do to, with an outcome like we see below, is to refocus on the chance that a release build might give us improved performance.
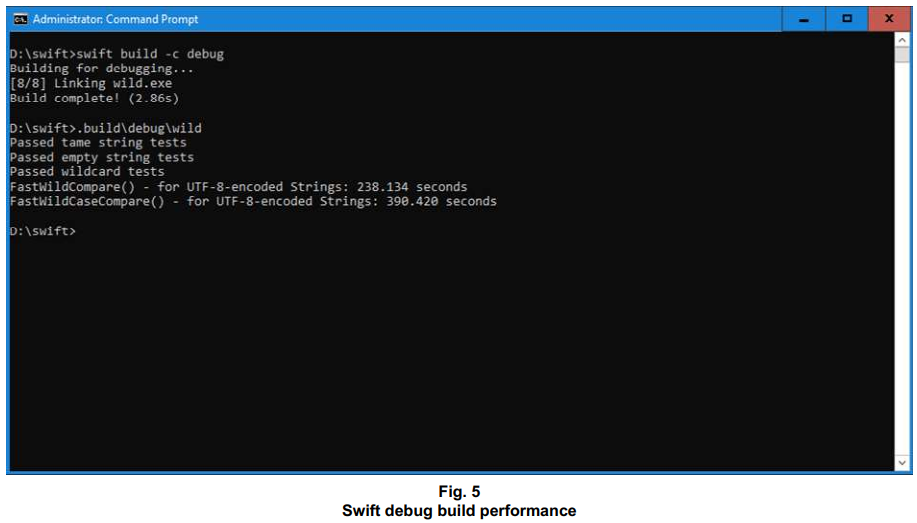
Can we indeed get improvements from a release build? I’d say so.

It’s not a bad thing that Swift is an evolving language. You never know whether something might turn up in a tool chest, sometime, that could make quite a difference for a project. For matching wildcards, C++-like performance could eventually come along – and who knows? – maybe even without calling for changes to our code.
Matching Wildcards in C/C++ – New UTF-8-Ready Routines
Getting internationalization right in C/C++ can be a challenge. Quite a bit of the complexity involved centers around case matching. When case matching doesn’t matter, or when it can be handled by a Unicode library, then the remaining factors can be handled more simply. Case matching, too, wouldn’t seem to be all that complicated, though the primary online resource for that task doesn’t come in a UTF-8 version for some reason.
If you don’t have a particular Unicode library in mind, I can’t advise you very well as to selecting one. Of the smaller ones, one of the most widely recognized has performance drawbacks. Grabbing a large Unicode library to do a small wildcard matching job may entail considerable compile-time and load-time overhead. [Thus the motivation for FastUtf8 – KJK, July 2026]
There’s also the compleity of UTF-8 validation. To be sure, a complete Unicode library would provide checks for invalid code points. For matching a pair of strings, though, it’s typically enough to say that if the bytes that comprise them don’t match, there’s nothing more to check – except for nulls. Since C/C++ string handling is null-terminator-based, the validation we need amounts to thorough null checking, even within what may or may not be code points comprising more than one byte each. With that null checking in place, we can implement a C/C++ function for matching wildcards that’ll work for both UTF-8 and ASCII strings.

Setting aside the concern about case matching, what we need for our matching wildcards algorithm is a small function for locating a next element of UTF-8 content – that is, a next code point – wherever our algorithm has been incrementing a pointer or index, plus another small function for comparing any two code points. That first of those small functions, which I’ve named CodePointAdvance(), can readily incorporate the needed null checking. Also, in the algorithm’s backtracking logic, there’s a preincrement-and-compare step that could benefit, performance-wise, from combining elements of both of those small functions. So we have this set of helper functions for matching wildcards:
// UTF-8-ready C++ routines for matching wildcards.
//
// Copyright 2025 Kirk J Krauss. This is a Derivative Work based on
// material that is copyright 2014 IBM Corporation and available at
//
// https://developforperformance.com/MatchingWildcards_AnImprovedAlgorithmForBigData.html
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// https://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// The following values are set according to the UTF-8 encoding standard
// described at
//
// https://en.wikipedia.org/wiki/UTF-8#Description
//
// Effectively, the number of bytes after a sequence of leading 1's, at
// the start of a code point, is limited to the maximum value of that
// first byte, given that the leading 1's are followed by a 0, followed
// by further 1's to complete the byte.
//
/* NOT VALIDATED HERE 0x7F */ // 0nnnnnnn (an entire 1-byte code point)
#define SINGLETON_LIMIT 0xBF // 10nnnnnn (an intra-code-point byte)
#define TWOFER_LIMIT 0xDF // 110nnnnn (first of a 2-byte code point)
#define THREESOME_LIMIT 0xEF // 1110nnnn (first of a 3-byte code point)
// Given a pointer to a UTF-8 code point, advances it to any next UTF-8 code
// point. Returns true if there is a further code point, or false if the
// next content is a terminating null. PERFORMS NO UTF-8 VALIDATION OTHER
// THAN NULL CHECKING.
//
inline bool CodePointAdvance(char **ppContent)
{
*ppContent += (*(unsigned char *) *ppContent > 0) +
((*(unsigned char *) *ppContent > SINGLETON_LIMIT) &&
*(1 + *ppContent)) +
((*(unsigned char *) *ppContent > TWOFER_LIMIT) &&
*(2 + *ppContent)) +
((*(unsigned char *) *ppContent > THREESOME_LIMIT) &&
*(3 + *ppContent));
return (bool) **ppContent;
}
// Compares two UTF-8 code points. Returns true if the code points are
// identical. Returns false otherwise. PERFORMS NO UTF-8 VALIDATION.
//
inline bool CodePointCompare(char *pContentA, char *pContentB)
{
if (*pContentA != *pContentB)
{
return false;
}
else if (*(unsigned char *) pContentA > SINGLETON_LIMIT &&
*(1 + pContentA) != *(1 + pContentB))
{
return false;
}
else if (*(unsigned char *) pContentA > TWOFER_LIMIT &&
*(2 + pContentA) != *(2 + pContentB))
{
return false;
}
else if (*(unsigned char *) pContentA > THREESOME_LIMIT &&
*(3 + pContentA) != *(3 + pContentB))
{
return false;
}
return true;
}
// Compares two UTF-8 code points. Advances the second pointer to any next
// UTF-8 code point. Returns true if the code points are identical. Returns
// false otherwise. PERFORMS NO UTF-8 VALIDATION.
//
inline bool CodePointAdvanceAndCompare(char *pContentA, char **ppContentB)
{
*ppContentB += (*(unsigned char *) *ppContentB > 0) +
((*(unsigned char *) *ppContentB > SINGLETON_LIMIT) &&
*(1 + *ppContentB)) +
((*(unsigned char *) *ppContentB > TWOFER_LIMIT) &&
*(2 + *ppContentB)) +
((*(unsigned char *) *ppContentB > THREESOME_LIMIT) &&
*(3 + *ppContentB));
if (*pContentA != **ppContentB)
{
return false;
}
else if (*(unsigned char *) pContentA > SINGLETON_LIMIT &&
*(1 + pContentA) != *(1 + *ppContentB))
{
return false;
}
else if (*(unsigned char *) pContentA > TWOFER_LIMIT &&
*(2 + pContentA) != *(2 + *ppContentB))
{
return false;
}
else if (*(unsigned char *) pContentA > THREESOME_LIMIT &&
*(3 + pContentA) != *(3 + *ppContentB))
{
return false;
}
return true;
}
// Given a null-terminated UTF-8 string, returns the number of code points
// in it. PERFORMS NO UTF-8 VALIDATION OTHER THAN NULL CHECKING.
//
size_t CodePointCount(char* pContent)
{
char *pCodePointInContent = pContent;
size_t iCount = *(unsigned char *) pCodePointInContent > 0;
while (CodePointAdvance(&pCodePointInContent))
{
iCount++;
}
return iCount;
}
That last function, CodePointCount(), is for testing an implementation that accepts a count of the code points in a UTF-8 string as a length parameter. That length can be useful for interoperating with JavaScript or in other arrangements where content isn’t null-terminated. The above functions incorporate checking for nulls at every byte anyway. That’s not ideal for performance, but in some contexts there’s a chance that our C/C++ implementation might be handed text in 8-bit ASCII format, which could throw off a purely UTF-8-focused check for string termination. With those comprehensive null checks, the following code for matching wildcards is ready for general use with any type of ASCII as well as with null-terminated UTF-8 strings.
// C++ implementation of FastWildCompare(), for null-terminated strings
// comprising valid UTF-8 code points. PERFORMS NO UTF-8 VALIDATION.
//
// Compares two strings. Accepts '?' as a single-code-point wildcard. For
// each '*' wildcard, seeks out a matching sequence of any code points beyond
// it. Otherwise compares the strings a code point at a time.
//
bool FastWildCompareUtf8(char *pWild, char *pTame)
{
char *pWildSequence; // Points to prospective wild string match after '*'
char *pTameSequence; // Points to prospective tame string match
// Find a first wildcard, if one exists, and the beginning of any
// prospectively matching sequence after it.
do
{
// Check for the end from the start. Get out fast, if possible.
if (!*pTame)
{
if (*pWild)
{
while (*pWild == '*')
{
if (!(*(++pWild)))
{
return true; // "ab" matches "ab*".
}
}
return false; // "abcd" doesn't match "abc".
}
else
{
return true; // "abc" matches "abc".
}
}
else if (*pWild == '*')
{
// Got wild: set up for the second loop and skip on down there.
while (CodePointAdvance(&pWild) && *pWild == '*')
{
continue;
}
if (!*pWild)
{
return true; // "abc*" matches "abcd".
}
// Search for the next prospective match.
if (*pWild !='?')
{
while (!CodePointCompare(pWild, pTame))
{
if (!CodePointAdvance(&pTame))
{
return false; // "a*bc" doesn't match "ab".
}
}
}
// Keep fallback positions for retry in case of incomplete match.
pWildSequence = pWild;
pTameSequence = pTame;
break;
}
else if (!CodePointCompare(pWild, pTame) && *pWild != '?')
{
return false; // "abc" doesn't match "abd".
}
// Everything's a match, so far.
CodePointAdvance(&pWild);
CodePointAdvance(&pTame);
} while (true);
// Find any further wildcards and any further matching sequences.
do
{
if (*pWild == '*')
{
// Got wild again.
while (*(++pWild) == '*')
{
continue;
}
if (!*pWild)
{
return true; // "ab*c*" matches "abcd".
}
if (!*pTame)
{
return false; // "*bcd*" doesn't match "abc".
}
// Search for the next prospective match.
if (*pWild != '?')
{
while (!CodePointCompare(pWild, pTame))
{
if (!CodePointAdvance(&pTame))
{
return false; // "a*b*c" doesn't match "ab".
}
}
}
// Keep the new fallback positions.
pWildSequence = pWild;
pTameSequence = pTame;
}
else if (!CodePointCompare(pWild, pTame) && *pWild != '?')
{
// The equivalent portion of the upper loop is really simple.
if (!*pTame)
{
return false; // "*bcd" doesn't match "abc".
}
// A fine time for questions.
while (*pWildSequence == '?')
{
++pWildSequence;
++pTameSequence;
}
// Fall back, but never so far again.
pWild = pWildSequence;
while (!CodePointAdvanceAndCompare(pWild, &pTameSequence))
{
if (!*pTameSequence)
{
return false; // "*a*b" doesn't match "ac".
}
}
pTame = pTameSequence;
}
// Another check for the end, at the end.
if (!*pTame)
{
if (!*pWild)
{
return true; // "*bc" matches "abc".
}
else
{
return false; // "*bc" doesn't match "abcd".
}
}
CodePointAdvance(&pWild); // Everything's still a match.
CodePointAdvance(&pTame);
} while (true);
}
A second implementation that adds a length check so it can be used with content that lacks a null terminator, as we might need (for example) as part of a Node.js addon, is available together with the above function at GitHub > kirkjkrauss > MatchingWildcardsUTF8ReadyInC.
The two new functions – meaning the ones with and without string length checks – run with very similar performance on my machine. For performance comparison with the original C/C++ implementation – the one for ASCII strings – for the run shown here, I’ve set the flags defined at the top of the testcase file (wild.cpp) to pass just the strings for ASCII-only testing to all three functions.
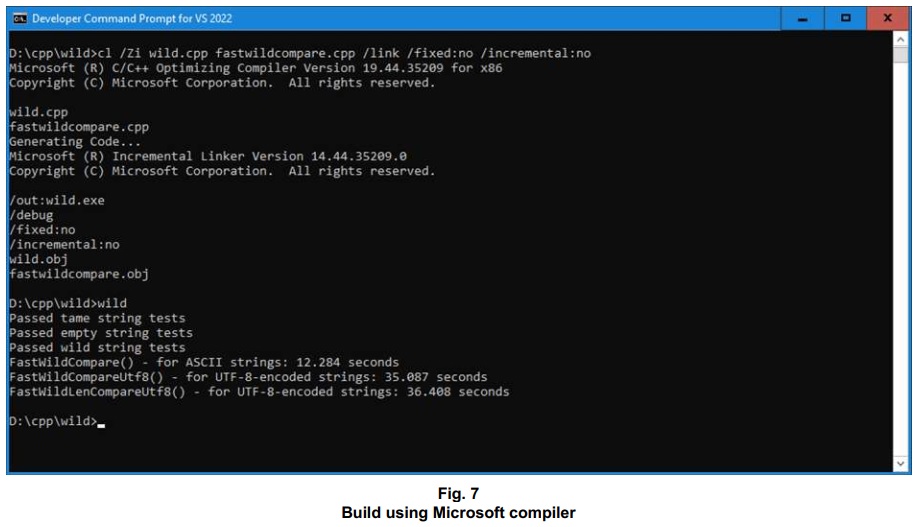
If you don’t think your wildcard needs will involve UTF-8, the ASCII-only function runs nearly 3x faster, at least on my machine, than either of the UTF-8-ready functions. It won’t make a big difference unless you’ve got a fairly intensive use case for matching wildcards. Otherwise, since the UTF-8-ready functions can handle any ASCII text (including 8-bit ASCII), either of these new functions could prove useful for the situation where you may want to make a switch from ASCII-only to UTF-8.
The output of a good runtime analysis tool speaks for itself. What you’ll see next is that I’ve run my set of correctness tests including UTF-8 tests (these have the same test strings as shown in Listing Four) for my two new functions. For this run, the tool I’ve used, Purify, has collected error and leak data as well as code coverage data at once.
What’s displayed at the run’s end are four tabs, with error and leak data shown in the left tab. In the screenshot, the next tab over is pulled up to show the program’s functions. For each of them, the tool shows how many lines of code were hit or missed during the run. Since this run has involved UTF-8 correctness testing, the original C/C++ implementation of my algorithm – the function named FastWildCompare() – hasn’t been called during the run.
Runtime analysis tools once enjoyed significant market success. A typical life arc for a sucessful tool would go something like this:
- A RAT is born to a development team → a small business is merrily launched;
- Informative marketing targets the best fitting audience: namely, individual developers and other smallish development teams;
- The RAT gets some fame and glory → bigger businesses take notice;
- One or more more mergers / acquisitions happen → the RAT gets marketed as a smallish part of a largish developer tools suite;
- Misinformative marketing targets the least fitting audience: namely, other big businesses;
- Amid vociferous dissatisfaction over the RAT, the suite’s revenues noticeably fail to be attibutable to it; and
- Those who stick around get to witness the decline and fall of the development team → the RAT is dead... but not extinct!
How could marketing for a runtime analysis tool shift from a fitting to misfitting audience, even as its pitch shifts toward misinformation? At the core of that problem is the limited scope of marketing staff to understand all the products in a suite of varied developer tools, combined with the human-nature drive to focus on large deals. A profound disconnect arises between the tool’s testing and marketing strategies.
Runtime analysis tools can’t reasonably be tested, in-house by their own development teams, against the vast variety of use cases that might get thrown at them by all the folks who might like to apply them to all their various software. I’ve seen people try to use these tools to instrument software packages that’ll load 100+ modules while firing off dozens of threads. Any timing dysregulation caused by introducing the tool’s own modules into the situation, along with the tool’s own tracking overhead, can affect thread safety. The resulting problem – typically a crash or hang – may be attributable more to the tool, or more to the program under test, but why bother attributing it at all? The real problem is a misunderstanding.
Even if the tool and that huge program under test were to get along and run right, what chance is there that a single developer could make much headway resolving the reams of runtime analysis output likely to show up? Probably that developer is well versed in only a handful of the modules, and in code for only a few of the threads. If just a portion of the program under test were to be instrumented and run using the tool – like in a unit test for some small package, though that package may be extracted from a far bigger picture – the conditions would be similar to those of the tool’s own in-house testing.
Smallish programs and smallish tests are where runtime analysis shines. Unfortunately, the folks who’ve marketed runtime analysis tools as smallish parts of suites, at least in my experience, haven’t been quick to point out this reality. Even the tools themselves tend to be shipped configured, by default, to instrument “the world.” That’s because big deals are seldom made with small use cases in mind. Yet some best development practices hinge around targeted tests, and that’s where runtime analysis tools best fit.
I suspect that runtime analysis tools have garnered something of a questionable reputation, having been enthusiastically misaimed in the name of deal-making by too many of their own advocates. That practice has in fact backfired, for all developers, not just for those of us who used to work on these tools. Looking at the level of detail shown at left, and considering the synergy of combining runtime error and code coverage analysis in a single run, what comes to mind is that I haven’t seen a tool like that on the market in a long time. Maybe I’m missing something. In any case, for whichever programming language you’re using, there’s every reason to advantageously fit the best runtime analysis tools currently available into your package- or module-scale development or test arrangements, no matter which kind of software you develop. That’s true even for the pieces & parts of the very same heavyweight software that’s caused the very same RATs to fail miserably when the whole package was instrumented at once.
Not all the RATs are completely gone; it’s the ones that were most marketed that have become hardest to get. Once-major players like BoundsChecker may no longer be available. Yet the concept keeps getting reinvented. You can sniff out which runtime analysis tools you can find for your programming language and operating system. Or you can scuttle around and arrange some runtime analysis tooling right in your own code.
Incidentally, in case you recall that IBM bought Rational Software over 20 years ago, you may be wondering about the age of the Purify build I use. It’s not quite as old as it may appear. I was a developer working on Purify, from way before the acquisition through 2010, and this build is one of my own. Nobody bugged my colleagues or me about whether IBM’s name appeared on the title bar or anywhere else on the tool’s main window, and none of us got around to changing it. After all, who put the RAT in Rational?

In the Purify view shown in Figure Eight, clicking on a function brings up an annotated source view as in Figures Nine and Ten. The helper functions for walking through and comparing UTF-8 strings have been nearly fully covered during the run, so they show up in blue. All of the null checks mentioned toward the beginning of this section have been hit.

Some lines not covered quite so well are among code nearly duplicative of the two functions shown above. It’s code invoked only during backtracking situations, where what starts out looking like a potential wildcard match turns out to be not completely matching. While there’s always room for more throrough testing, the UTF-8 tests provided here are getting us either into all the relevant code, or into code virtually identical to it, in one of the helper functions or another.
Meanwhile, all this code is running without errors or leaks, which would’ve been flagged with red highlights in the Error View below if there’d been any. I’ve opened a list of memory blocks in use, where the tool is showing us some blocks allocated by the C runtime on behalf of my test program.
Error-free execution isn’t always easy to achieve. When it’s accompanied by a thorough set of testcases that can be shown, via runtime analysis, to cover the relevant code, then our software is assuredly safe from runtime errors related to memory management. Once this level of safety can be assured in-house, there’s no need to build in equivalent checking that’ll slow down the user experience in the field. That means no need to worry about any slowdown involving smart pointers, or any misbehavior involving array-bounds violations, etc. Besides, runtime analysis shows the result of a real run. The results aren’t limited to what might be discoverable, or interesting, via data flow analysis done without benefit of real-world execution.
Tools of one kind or another are essential to best practices. So are tests and testing techniques. When our tools and techniques are effective enough to influence our style, why not see where it can lead? Wouldn’t a style that can help an algorithm span programming languages seem as good an indication of code quality as any? There may be a lot said favoring the comfort of personally sticking with convention. There also is something to be said for the creative potential of any less conventional perspective that shows a sign of quality.

The complete Go source code associated with this article is available at GitHub > kirkjkrauss > MatchingWildcardsInGo. The complete Swift source code is available at GitHub > kirkjkrauss > MatchingWildcardsInSwift. The complete C/C++ source code is available at GitHub > kirkjkrauss > MatchingWildcardsUTF8ReadyInC
“You have three pointing back at you” is an old saying, author unknown. The solitary esophagus is borrowed from Mark Twain’s “A Double Barrelled Detective Story” (1902). If Mark Twain could place an esophagus in the sky and make it seem lovely, I figured I could place one in a cluttered tool chest and make it seem fitting. Regarding the cable stretchers, I’m sure I’ve got a set of them somewhere in my own cluttered tool chest, but I’m not sure whether they’re meant for short cables, short circuits, or dead ones; anyway, such a tool may indeed exist. “Who put the RAT in Rational?” is a saying I coined. Most who heard it, back when Rational Software was its own corporation, didn’t realize it was attributable to me. It got some slight notoriety when a few of my colleagues repeated it, as part of a skit at a company gathering, then ran around chanting “Runtime! Runtime!”
Source code listings are formatted using the SyntaxHighlighter library, copyright (c) 2004-2013, Alex Gorbatchev.
All other materials copyright © 2025 developforperformance.com.
Rust™ is a trademark of the Rust Foundation. PurifyPlus™ is a trademark of Unicom Global. Go™ and its logo are trademarks of Google Inc. Swift™ and its logo are trademarks of Apple Inc. C++ and its logo are trademarks of the Standard C++ Foundation. AMD FX™ is a trademark or registered trademark of Advanced Micro Devices, Inc. Windows®, Visual Studio®, and Visual Studio Code® are trademarks or registered trademarks of Microsoft Corp. Unix® is a registered trademark of The Open Group. Linux® is a registered trademark of Linus Torvalds. JavaScript™ is a trademark of Oracle Corporation.