Fast UTF-8 Handling for Legacy C ♦ Developer’s Guide and Reference
By Kirk J Krauss
What’s Here
- A guide to the C-compatible functions included with the FastUtf8::Uniseries C++ class outlined in the FastUtf8 overview and defined in the fastutf8.cpp file at GitHub > kirkjkrauss > FastUtf8 and in the fastutf8.c file at GitHub > kirkjkrauss > FastUtf8 > LegacyC;
- A description of each of the included *Utf8() functions; and
- Example code.
Working With the *Utf8() Family of Functions
The C functions that underlie the functionality in the FastUtf8 namespace are described here. They’re declared in an "extern C" linkage specification block in fastutf8.h, ahead of the code in the FastUtf8 namespace. They’re defined in fastutf8.cpp, similarly ahead of the classes within the FastUtf8 namespace. To keep them compatible with legacy C projects, they’re not part of the namespace itself.
The code that appears in this guide refers to the C functions that underlie the FastUtf8 namespace.
To provide for a clean internationalization package for C projects, the source code on GitHub has a LegacyC path that includes a fastutf8.h file and a fastutf8.c file. The code in these LegacyC files is nearly identical to the code in the fastutf8.h file and fastutf8.cpp files in the base FastUtf8 path, but the FastUtf8 namespace is left out, and so is everything within it. Some compilers may prefer things that way. Equivalents for certain keywords used by the FastUtf8::Uniseries C++ methods, including BOOL, TRUE, and FALSE, are #define’d. The NULLPTR value is #define’d to be 0. The fastutf8.cpp functions that return bool values are modified, in fastutf8.c, to return int values; the function signatures are similarly modified in the fastutf8.h file in the LegacyC path.
Both the base source code path and the LegacyC path include case mapping files that get built as part of any project that makes use of these C functions. When the project is built, the mappings reside in the resulting executable’s Data section and occupy a few megabytes once the executable has been loaded.
Important: The first of the functions to call is CaseMappingSetupUtf8(), which initializes the mappings for case folding. The function needs to be called once, and only once, per run. Other functions described here, particularly those that involve case-insensitive behavior, won’t work right unless that initialization step has happened. Setting up the call itself is quite simple. The entire function description calls for only a few lines:
CaseMappingSetupUtf8()
Initializes sets of mappings for case folding. The mappings are used by the other functions here for case-insensitive content matching.
Signature
void);
The remaining functions are described here in the order that they appear in the fastutf8.h file. Their signatures are as they appear in the version of that file in the base source code path. The signatures are modified, as described above, in the fastutf8.h file in the LegacyC path.
UTF-8 Validation and Conversion Functions
ValidateUtf8()
Counts the number of contiguous valid code points in the given null-terminated content, starting from the beginning of the content. Returns true if every code point prior to the terminating null is valid. Returns false otherwise.
Signature
const uint8_t *pContent,
int *piCount);
Parameters
LenValidateUtf8()
Validates the given content, up to the specified number of code points, starting from the beginning of the content. Returns true if as many code points are valid. Returns false otherwise.
Signature
const uint8_t *pContent,
int lenContent);
Parameters
ValidateWithIs7BitUtf8()
Validates the given content, up to a terminating null, starting from the beginning of the content. Counts the number of contiguous valid code points. Sets the bIs7BitCharString flag if every code point represents a 7-bit ASCII character. Returns the number of bytes in the content, if the code points are valid. Returns zero otherwise. This function and the one that follows it are useful for constructing an object of a class that can handle ASCII character strings optimally and that also can handle UTF-8 content.
Signature
const uint8_t *pContent,
int *piCount,
bool *pbIs7BitCharString);
Parameters
LenValidateWithIs7BitUtf8()
Validates the given content, up to the specified number of code points, starting from the beginning of the content. Returns the number of bytes in the content, if the code points are valid. Returns zero otherwise. Sets the bIs7BitCharString flag if every code point represents a 7-bit ASCII character.
Signature
const uint8_t *pContent,
int lenContent,
bool *pbIs7BitCharString);
Parameters
Convert8BitAsciiToUtf8()
Given 8-bit ASCII content, allocates a buffer for UTF-8 content and places the equivalent UTF-8 content in it. If the FREE_INVALID_CONTENT flag (a #define option) is set, deallocates the block containing the 8-bit ASCII content.
Signature
const char *pContent,
int *lenContent);
Parameters
Discussion
LenConvert8BitAsciiToUtf8()
Given an 8-bit ASCII string and its size in bytes, allocates a buffer sufficient for the equivalent UTF-8 content and places that content in it. If FREE_INVALID_CONTENT is set, deallocates the block containing the 8-bit ASCII string. Returns a pointer to the new buffer, or nullptr if the content comprises only 7-bit ASCII characters.
Signature
const char *pContent,
size_t sizeContent);
Parameters
Discussion
Example: Validation and Conversion Tests (abridged)
// Validates UTF-8 content via the two validation routines.
//
bool testvalidate(uint8_t *pContent, int *piCount, bool bExpectedResult)
{
bool bPassed = true;
if (bExpectedResult != ValidateUtf8(pContent, piCount))
{
bPassed = false;
}
if (bExpectedResult != LenValidateUtf8(pContent,
CodePointCountUtf8(pContent)))
{
bPassed = false;
}
return bPassed;
}
// Produces UTF-8 content from 8-bit ASCII text via the two conversion
// routines. Allocates a block to contain the converted form of any actual
// 8-bit content.
//
bool testconvert(uint8_t *pContent, uint8_t **pConvertedContentA)
{
uint8_t *pConvertedContentB;
int lenContent;
size_t sizeA = 0;
size_t sizeB = 0;
bool bPassed = true;
*pConvertedContentA = Convert8BitAsciiToUtf8((char *) pContent, &lenContent);
if (*pConvertedContentA)
{
sizeA = strlen((char *) *pConvertedContentA);
}
else
{
*pConvertedContentA = pContent;
}
pConvertedContentB = LenConvert8BitAsciiToUtf8((char *) pContent,
strlen((char *) pContent));
if (pConvertedContentB)
{
sizeB = strlen((char *) pConvertedContentB);
free((char *) pConvertedContentB);
}
if (sizeA != sizeB)
{
bPassed = false;
}
return bPassed;
}
bool testset_validateandconvert(void)
{
int iCountExtendedAscii = 0;
const int iExpectedCountExtendedAscii = 0; // Because it's not valid UTF-8.
uint8_t zExtendedAscii[8] = // Actual array element count.
{ 0xBE, 0xF7, 0xBD, 0xAC, 0x3D, 0x7E, 0xD8, 0x00 };
uint8_t *zConvertedExtendedAscii;
int iCountAscii = 0;
const int iExpectedCountAscii = 10;
uint8_t zAscii[1 + iExpectedCountAscii] = "No problem";
uint8_t *zConvertedAscii;
int iCountCherokee = 0;
const int iExpectedCountCherokee = 25;
uint8_t zCherokee[1 + (4 * iExpectedCountCherokee)] = "ᎤᏁᏝᏅᎯ ᎤᏓᏁᏗ ᎬᏩᏂᏐᎢ ᏂᎦᏓ ᎠᏂᎷᎩ";
uint8_t *zConvertedCherokee;
bool bAllPassed = true;
// Case with extended ASCII text.
bAllPassed &= testvalidate(/* pContent = */ zExtendedAscii,
/* iCount = */ &iCountExtendedAscii,
/* bExpectedResult = */ false);
// Cases with valid UTF-8 content.
bAllPassed &= testvalidate(zAscii, &iCountAscii, /* bExpectedResult = */ true);
bAllPassed &= testvalidate(zCherokee, &iCountCherokee, /* bExpectedResult = */ true);
if (bAllPassed)
{
bAllPassed &= (iCountExtendedAscii == iExpectedCountExtendedAscii);
bAllPassed &= (iCountAscii == iExpectedCountAscii);
bAllPassed &= (iCountCherokee == iExpectedCountCherokee);
if (bAllPassed)
{
// Calls to testconvert() allocate the blocks returned by reference.
bAllPassed &= testconvert(zExtendedAscii, &zConvertedExtendedAscii);
bAllPassed &= testconvert(zAscii, &zConvertedAscii);
bAllPassed &= testconvert(zCherokee, &zConvertedCherokee);
if (bAllPassed)
{
printf("Passed UTF-8 validation and conversion tests.\n");
}
else
{
printf("Failed 8-bit ASCII conversion tests.\n");
}
}
else
{
printf("Failed code point counting for null-terminated content.\n");
}
}
else
{
printf("Failed null-terminated UTF-8 validation tests.\n");
}
if (zConvertedExtendedAscii && zConvertedExtendedAscii != zExtendedAscii)
{
free((char *) zConvertedExtendedAscii);
}
if (zConvertedAscii && zConvertedAscii != zAscii)
{
free((char *) zConvertedAscii);
}
if (zConvertedCherokee && zConvertedCherokee != zCherokee)
{
free((char *) zConvertedCherokee);
}
return bAllPassed;
}
Case Folding Functions
SizeOfFoldedUtf8()
Given a buffer containing null-terminated UTF-8 content, anticipates the size of its folded equivalent, in bytes. Anticipates 4 bytes for the noncharacter 0xFFFFFFFF in place of any code-point-sized content that is not valid UTF-8. Does not check for invalid pointers.
Signature
const uint8_t *pContent);
Parameter
SizeOfFoldedLenUtf8()
Given a buffer containing UTF-8 content and a number of code points in the content, anticipates the size of the content’s folded equivalent, in bytes. Anticipates 4 bytes for the noncharacter 0xFFFFFFFF in place of any code-point-sized content that is not valid UTF-8. Does not check for invalid pointers.
Signature
const uint8_t *pContent,
int lenContent);
Parameters
ToFoldedUtf8()
Given a source buffer containing UTF-8 content, places its folded equivalent into the given destination buffer, up to the specified number of bytes. Places the noncharacter 0xFFFFFFFF into the destination buffer in place of any code-point-sized source content that is not valid UTF-8. For Latin, Greek, and most other symbol sets that embody the bicameral uppercase and lowercase concept, acts as an greedy iterative tolower() function for UTF-8. Does not check for buffer overflow, buffer overlap, or invalid pointers.
Signature
uint8_t *pDestination,
const uint8_t *pSource,
size_t sizeDestination);
Parameters
Discussion
Example: Case Folding Tests (abridged)
// Produces case-insensitive content via the included case folding routine.
//
bool testtofolded(uint8_t *pContent, uint8_t *pExpectedContent)
{
uint8_t *pFoldedContent;
bool bPassed = true;
size_t sizeContentA = SizeOfFoldedUtf8(pContent);
size_t sizeContentB = SizeOfFoldedLenUtf8(pContent,
CodePointCountUtf8(pContent));
if (sizeContentA != sizeContentB)
{
bPassed = false;
}
else
{
pFoldedContent = (uint8_t *) malloc(sizeContentA);
if (pFoldedContent)
{
pFoldedContent = ToFoldedUtf8(
pFoldedContent, pContent, sizeContentA);
if (!CompareUtf8(pFoldedContent, pExpectedContent))
{
bPassed = false;
}
free(pFoldedContent);
}
}
return bPassed;
}
// Tests that case fold ASCII and UTF-8 content.
//
bool testset_foldcopyandduplicate_ascii(void)
{
// 7-bit ASCII tests.
const int lenAsciiA = 13;
uint8_t szAsciiA[1 + lenAsciiA] = "Hello, World!";
const int lenAsciiF = 29;
uint8_t szAsciiF[1 + lenAsciiF] = "use std::convert::Infallible;";
bool bAllPassed = true;
// Verify case folding for short strings and single ASCII code points.
bAllPassed &= testtofolded((uint8_t *) "r", (uint8_t *) "r");
bAllPassed &= testtofolded((uint8_t *) "R", (uint8_t *) "r");
bAllPassed &= testtofolded((uint8_t *) "aaa", (uint8_t *) "aaa");
bAllPassed &= testtofolded((uint8_t *) "aAa", (uint8_t *) "aaa");
bAllPassed &= testtofolded((uint8_t *) "AAA", (uint8_t *) "aaa");
bAllPassed &= testtofolded((uint8_t *) "aaA", (uint8_t *) "aaa");
bAllPassed &= testtofolded((uint8_t *) "Mississippi", (uint8_t *) "mississippi");
bAllPassed &= testtofolded((uint8_t *) "ippississiM", (uint8_t *) "ippississim");
bAllPassed &= testtofolded((uint8_t *) "IPPISSISSIM", (uint8_t *) "ippississim");
bAllPassed &= testtofolded((uint8_t *) "_ _", (uint8_t *) "_ _");
bAllPassed &= testtofolded((uint8_t *) szAsciiA, (uint8_t *) "hello, world!");
bAllPassed &= testtofolded((uint8_t *) szAsciiF, (uint8_t *) "use std::convert::infallible;");
// Verify case folding for some non-ASCII content.
bAllPassed &= testtofolded((uint8_t *) "Φ", (uint8_t *) "φ");
bAllPassed &= testtofolded((uint8_t *) "Ж", (uint8_t *) "ж");
bAllPassed &= testtofolded((uint8_t *) "Ⱎ", (uint8_t *) "ⱎ");
bAllPassed &= testtofolded((uint8_t *) "ⱎ", (uint8_t *) "ⱎ");
bAllPassed &= testtofolded((uint8_t *) "𞤒", (uint8_t *) "𞤴");
bAllPassed &= testtofolded((uint8_t *) "𞤴", (uint8_t *) "𞤴");
bAllPassed &= testtofolded((uint8_t *) "Ծ", (uint8_t *) "ծ");
bAllPassed &= testtofolded((uint8_t *) "ծ", (uint8_t *) "ծ");
bAllPassed &= testtofolded((uint8_t *) "αこ", (uint8_t *) "αこ");
bAllPassed &= testtofolded((uint8_t *) "🦢🦢🦢🦢", (uint8_t *) "🦢🦢🦢🦢");
bAllPassed &= testtofolded((uint8_t *) "𓅓𓅓", (uint8_t *) "𓅓𓅓");
bAllPassed &= testtofolded((uint8_t *) "Ἀα", (uint8_t *) "ἀα");
bAllPassed &= testtofolded((uint8_t *) "αἈ", (uint8_t *) "αἀ");
bAllPassed &= testtofolded((uint8_t *) "ἀα", (uint8_t *) "ἀα");
bAllPassed &= testtofolded((uint8_t *) "Дϩ𐖱", (uint8_t *) "дϩ𐖱");
bAllPassed &= testtofolded((uint8_t *) "дϩ𐖱", (uint8_t *) "дϩ𐖱");
bAllPassed &= testtofolded((uint8_t *) "𞤀 𞤢", (uint8_t *) "𞤢 𞤢");
if (bAllPassed)
{
printf("Passed case folding tests.\n");
}
else
{
printf("Failed case folding tests.\n");
}
return bAllPassed;
}
Buffer Management Functions
CodePointCountUtf8()
Given null-terminated UTF-8 content, returns the number of code points in it. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent);
Parameter
SizeOfUtf8()
Given null-terminated UTF-8 content, returns the number of bytes in it. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent);
Parameter
SizeOfLenUtf8()
Given UTF-8 content and a count of the code points in it, returns the number of bytes in it. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
int lenContent);
Parameters
LenSizeOfUtf8()
Given a byte range comprising UTF-8 content, returns the number of code points in the range. Returns -1 if the range does not begin or end at byte values consistent with valid code point boundaries. Performs no other pointer validation and no other UTF-8 validation besides null checking.
Signature
const uint8_t *pContent,
size_t sizeContent);
Parameters
Is7BitUtf8()
Given null-terminated UTF-8 content, determines whether it comprises entirely 7-bit “half ASCII” characters, which would make it compatible with ordinary C/C++ string routines. Returns true for a 7-bit ASCII string, and false otherwise. Performs no UTF-8 validation other than null checking.
Signature
uint8_t *pContent);
Parameter
IsLen7BitUtf8()
Given UTF-8 content and its length in code points, determines whether it comprises entirely 7-bit “half ASCII” characters. Returns true for a 7-bit ASCII string, and false otherwise. Performs no UTF-8 validation other than null checking.
Signature
uint8_t *pContent,
int lenContent);
Parameters
Example: ASCII Recognition Tests (abridged)
// Determines whether UTF-8 content comprises entirely 7-bit ASCII text.
//
bool testisascii(uint8_t *pContent, int lenContent, bool bExpectedResult)
{
bool bPassed = true;
if (bExpectedResult != Is7BitUtf8(pContent))
{
bPassed = false;
}
if (bExpectedResult != IsLen7BitUtf8(pContent, lenContent))
{
bPassed = false;
}
return bPassed;
}
// Tests that check as to whether content comprises entirely ASCII text.
bool testset_asciicheck(void)
{
// 7-bit ASCII test.
const int lenAscii = 13;
uint8_t szAscii[1 + lenAscii] = "Hello, World!";
const int lenAramaic = 153;
uint8_t zAramaic[1 + (4 * lenAramaic)] =
"הָכָא יִתְמַצֵּא מִלּוּתָא דְּסִיּוּן יַעֲקֹב מִן אַרִימַתְיָא. דִּי הוּא גִּבּוֹר וְטָהוֹר בְּרוּחָא יִמְצָא גְּלִיּוֹן קָדִישׁ בְּטוּרָא דְּאֲרָרְגָּה.";
// Based on _Monty Python and the Holy Grail_, script by Graham
// Chapman, John Cleese, and Eric Idle (1975)
bool bAllPassed = true;
// Verify that the 7-bit ASCII string checks out.
bAllPassed &= testisascii(szAscii, lenAscii, true);
// Verify that what's not 7-bit ASCII is recognized as such.
bAllPassed &= testisascii(zAramaic, lenAramaic, false);
if (bAllPassed)
{
printf("Passed ASCII recognition tests.\n");
}
else
{
printf("Failed ASCII recognition tests.\n");
}
return bAllPassed;
}
Functions That Copy Content
CopyUtf8()
Copies UTF-8 (or any) null-terminated content to the given destination buffer from the given source buffer. Does not check for buffer overflow, buffer overlap, or invalid pointers. Performs no UTF-8 validation other than null checking.
Signature
uint8_t *pDestination,
const uint8_t *pSource);
Parameters
LenCopyUtf8()
Copies UTF-8 content to the given destination buffer from the given source buffer, up to the specified number of code points. Does not check for buffer overflow, buffer overlap, or invalid pointers. Performs no UTF-8 validation other than null checking.
Signature
uint8_t *pDestination,
const uint8_t *pSource,
int lenContent);
Parameters
DuplicateUtf8()
Allocates a buffer and copies UTF-8 content to it from the given null-terminated source buffer. Does not check for an invalid source buffer pointer. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pSource);
Parameter
Discussion
LenDuplicateUtf8()
Allocates a buffer and copies UTF-8 content to it from the given source buffer, up to the specified number of code points. Does not check for an invalid source buffer pointer. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pSource,
int lenContent);
Parameters
Discussion
Example: Copy / Duplicate Tests (abridged)
// Copies UTF-8 content. Verifies that the copies match the original content.
//
bool testcopyandduplicate(uint8_t *pContent, int lenContent)
{
// Allocate blocks for use with *CopyUtf8().
size_t sizeContent = 1 + SizeOfLenUtf8(pContent, lenContent);
uint8_t *pContentCopyTerm = (uint8_t *) malloc(sizeContent);
uint8_t *pContentCopyLen = (uint8_t *) malloc(sizeContent);
bool bPassed = true;
if (pContentCopyTerm)
{
pContentCopyTerm = CopyUtf8(pContentCopyTerm, pContent);
}
if (pContentCopyLen)
{
pContentCopyLen = LenCopyUtf8(pContentCopyLen, pContent, sizeContent);
}
uint8_t *pContentDuplicateTerm = DuplicateUtf8(pContent);
uint8_t *pContentDuplicateLen = LenDuplicateUtf8(pContent, sizeContent);
// Verify results for null-terminated tests.
if (!pContentCopyTerm || !pContentDuplicateTerm ||
!CompareUtf8(pContent, pContentCopyTerm) ||
!CompareUtf8(pContent, pContentDuplicateTerm))
{
bPassed = false;
}
// Verify results for length-limited tests.
if (!pContentCopyLen || !pContentDuplicateLen ||
!LenCompareUtf8(pContent, pContentCopyLen, lenContent) ||
!LenCompareUtf8(pContent, pContentDuplicateLen, lenContent))
{
bPassed = false;
}
// Dellocate the blocks used for these tests.
if (pContentCopyTerm)
{
free((char *) pContentCopyTerm);
}
if (pContentCopyLen)
{
free((char *) pContentCopyLen);
}
if (pContentDuplicateTerm)
{
free((char *) pContentDuplicateTerm);
}
if (pContentDuplicateLen)
{
free((char *) pContentDuplicateLen);
}
return bPassed;
}
// Tests that copy and duplicate UTF-8 content involve these functions:
// IsLen7BitUtf8()
// CopyUtf8()
// LenCopyUtf8()
// DuplicateUtf8()
// LenDuplicateUtf8()
// CompareUtf8()
// LenCompareUtf8()
//
bool testset_foldcopyandduplicate(void)
{
const int lenAscii = 67;
uint8_t szAscii[1 + lenAscii] =
"Wasn't that a dainty dish / To set before the king?";
const int lenSymbols = 25;
uint8_t zSymbols[1 + (4 * lenSymbols)] = "ʚïɞ✧🦢🌿𓍊⋇𓋼𓍊.✧🍄✧.𓍊𓋼⋇𓍊🌿🦢✧ʚïɞ";
bool bAllPassed = true;
bAllPassed &= testcopyandduplicate(szAscii, lenAscii);
bAllPassed &= testcopyandduplicate(zSymbols, lenSymbols);
if (bAllPassed)
{
printf("Passed copy and duplicate tests.\n");
}
else
{
printf("Failed copy and duplicate tests.\n");
}
return bAllPassed;
}
Content Concatenation Functions
ConcatenateUtf8()
Given a buffer partially initialized with null-terminated UTF-8 content, copies additional null-terminated UTF-8 content to it, beginning by overwriting the original content’s terminating null and continuing to the additional content’s terminating null. Returns true if buffer size, specified in bytes, is sufficient to accommodate the total content, and false otherwise. Performs no UTF-8 validation other than null checking.
Signature
uint8_t *pContent,
size_t sizeContentBuffer,
const uint8_t *pAdditionalContent);
Parameters
LenConcatenateUtf8()
Given a buffer partially initialized with UTF-8 content comprising a specified number of code points, copies additional UTF-8 content to it, beginning after that given length and continuing to the length of the additional content, also given as a specified number of code points. Returns true if the buffer size, specified in bytes, is sufficient to accommodate the total content, and false otherwise. Performs no UTF-8 validation other than null checking.
Signature
uint8_t *pContent,
size_t sizeContentBuffer,
const uint8_t *pAdditionalContent,
int lenContent,
int lenAdditionalContent);
Parameters
Content Separation Functions
SeparateUtf8()
Given a pointer to UTF-8 content and a pointer to one or more delimiter code points, searches the content for the first occurrence of any delimiter. Replaces that code point in the content with a null terminator, including enough nulls to replace the entire code point. Returns a pointer to any first delimited content, or nullptr if there is no content.
Signature
uint8_t **ppContent,
const uint8_t *pTokenSet);
Parameters
Discussion
The function modifies the inbound content. It performs no UTF-8 validation other than null checking.
Tokenset search functionality checks from the content’s starting location for the first occurrence of any token in the set. Short tokensets provide for best performance.
SeparateAscii()
Given a pointer to an ASCII string and a pointer to one or more delimiter characters, searches the string for the first occurrence of a delimiter. Replaces that character in the string with a null terminator. Returns a pointer to any first delimited portion of the string, or nullptr if the string is empty. The function modifies the inbound content. It does not handle UTF-8.
Signature
char **ppszText,
const char *pszTokenSet);
Parameters
Discussion
Further Tokenset Search Functions
TokenFindUtf8()
Given a pointer to null-terminated UTF-8 content and a pointer to a null-terminated set of one or more delimiter code points, searches the content for the first occurrence of any delimiter. Bypasses any initial delimiters at the content’s start. In case a delimiter is found within the subsequent content, returns a pointer to the code point immediately prior to it. Returns nullptr if no delimiter is found. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pTokenSet);
Parameters
TokenLenFindUtf8()
Given a pointer to length-limited UTF-8 content and a pointer to a length-limited set of one or more delimiter code points, searches the content for the first occurrence of any delimiter. Bypasses any initial delimiters at the content’s start. In case a delimiter is found within the subsequent content, returns a pointer to the code point immediately prior to it. Returns nullptr if no delimiter is found. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pTokenSet,
int lenContent,
int lenTokenSet);
Parameters
Example: Separate, Concatenate, and Slice Tests (abridged)
// Separates token-delimited UTF-8 content, concatenates the separated
// portions so as to rebuild the content with single spaces where the tokens
// were, then slices the concatenated content (selects a substring).
//
// Verifies that a selected slice of the recombined content matches a
// passed-in parameter comprising expected content, by calling CompareUtf8()
// or LenCompareUtf8().
//
bool testseparateconcatenateandslice(uint8_t *pContent, uint8_t *pDelimiter,
int iFirst, int iLast, // slice indices
int lenContent, uint8_t *pExpectedSlice)
{
// Detokenized content gets rebuilt, via concatenation, into a buffer
// allocated up front.
uint8_t *pzDuplicateUtf8Base = DuplicateUtf8(pContent);
uint8_t *pzDuplicateUtf8 = pzDuplicateUtf8Base;
uint8_t *pzSlice = nullptr; // Allocated via call to *SliceUtf8().
bool bPassed = true;
// These variables are needed during steps along the way.
uint8_t *pzUtf8Portion;
bool bTopOfContent;
if (!pszSlice1 || !pzDetokenizedUtf8 || !pzDuplicateUtf8)
{
// Memory allocation failure.
return false;
}
else
{
// Initialize the new UTF-8 buffer.
pzDetokenizedUtf8[0] = 0;
sizeAscii = 0;
bTopOfContent = true;
// Concatenate tokenized content, a portion at a time, into the
// buffers.
if (pzDuplicateUtf8) do
{
// Get SeparateUtf8() + TrimUtf8() timing [Mode A].
pzUtf8Portion = TrimUtf8(SeparateUtf8(
&pzDuplicateUtf8, pDelimiter));
if (pzUtf8Portion)
{
if (lenContent)
{
if (bTopOfContent)
{
pzDetokenizedUtf8 = LenConcatenateUtf8(
pzDetokenizedUtf8, sizeBuf,
pzUtf8Portion,
CodePointCountUtf8(pzDetokenizedUtf8),
CodePointCountUtf8(pzUtf8Portion));
bTopOfContent = false;
}
else
{
pzDetokenizedUtf8 = LenConcatenateUtf8(
pzDetokenizedUtf8, sizeBuf,
(uint8_t *) " ",
CodePointCountUtf8(pzDetokenizedUtf8),
1);
pzDetokenizedUtf8 = LenConcatenateUtf8(
pzDetokenizedUtf8, sizeBuf,
pzUtf8Portion,
CodePointCountUtf8(pzDetokenizedUtf8),
CodePointCountUtf8(pzUtf8Portion));
}
}
else
{
if (bTopOfContent)
{
pzDetokenizedUtf8 = ConcatenateUtf8(
pzDetokenizedUtf8, sizeBuf,
pzUtf8Portion);
}
else
{
pzDetokenizedUtf8 = ConcatenateUtf8(
pzDetokenizedUtf8,
sizeBuf, (uint8_t *) " ");
pzDetokenizedUtf8 = ConcatenateUtf8(
pzDetokenizedUtf8, sizeBuf,
pzUtf8Portion);
}
}
}
} while (pzDuplicateUtf8);
if (pzDuplicateUtf8Base)
{
free((char *) pzDuplicateUtf8Base);
pzDuplicateUtf8Base = nullptr;
}
}
// Get the content between the first and last index.
if (lenContent)
{
// Select the content via the length-limited routine.
pzSlice = LenSliceUtf8(pzDetokenizedUtf8, iFirst, iLast, lenContent);
if (pzSlice)
{
if (!LenCompareUtf8(pzSlice, pExpectedSlice, lenContent))
{
// Mismatched slices.
bPassed = false;
}
}
}
else
{
// Select the content via the routine that checks for a
// terminating null.
pzSlice = SliceUtf8(pzDetokenizedUtf8, iFirst, iLast);
if (pzSlice)
{
if (!CompareUtf8(pzSlice, pExpectedSlice))
{
// Mismatched slices.
bPassed = false;
}
}
}
if (pzSlice)
{
free((char *) pzSlice);
}
if (pzDetokenizedUtf8)
{
free((char *) pzDetokenizedUtf8);
}
return bPassed;
}
// Tests that concatenate, separate, tokenize, and slice UTF-8 content
// involve these functions:
// ConcatenateUtf8()
// LenConcatenateUtf8()
// SeparateUtf8()
// LenSeparateUtf8()
// SliceUtf8()
// LenSliceUtf8()
//
// This first test set involves 7-bit ASCII strings and includes code for
// performance comparison of SeparateUtf8() vs. SeparateAscii() (Mode A) and
// *ConcatenateUtf8() vs. str*cat() (Mode B).
//
bool testset_separateconcatenateandslice_ascii(void)
{
// 7-bit ASCII tests.
const int lenAscii = 45;
uint8_t szAscii[1 + lenAscii] =
"what,do,we,do,with,a,comma-separated,list?";
const int lenArmenianWithStars = 26;
uint8_t zArmenianWithStars[1 + (4 * lenArmenianWithStars)] = "Կաթ ✶ հաց ✶ պանիր ✶ ձու"; // sep: ✶
const int iRelyNull = 0; // Rely on null string terminators.
bool bAllPassed = true;
bAllPassed &= testseparateconcatenateandslice(szAscii,
/* pDelimiter = */ (uint8_t *) ",", /* iFirst = */ 21, /* iLast = */ 41,
/* lenContent = */ iRelyNull,
/* pExpectedSlice = */ (uint8_t *) "comma-separated list");
bAllPassed &= testseparateconcatenateandslice(zArmenianWithStars,
/* pDelimiter = */ (uint8_t *) "✶", /* iFirst = */ 0, /* iLast = */ 3,
/* lenContent = */ lenArmenianWithStars, /* pExpectedSlice = */ (uint8_t *) "Կաթ");
if (bAllPassed)
{
printf("Passed separate, concatenate, and slice tests with UTF-8 content\n");
}
else
{
printf("Failed separate, concatenate, and slice tests with UTF-8 content\n");
}
return bAllPassed;
}
Index and Trim Functions
IndexUtf8()
Returns the UTF-8 code point at the given index within the content. The performance is terrible, relative to ASCII string indexing.
Signature
uint8_t *pContent,
int iIndex);
Parameters
TrimUtf8()
Removes leading and trailing spaces from null-terminated UTF-8 content, modifying the content in place. Returns a pointer to the beginning of the content. In case the content occupies a heap memory block, in order to deallocate that block, the caller will need to retain the original pointer to it. Performs no UTF-8 validation other than null checking.
Signature
uint8_t *pContent);
Parameter
TrimAscii()
Removes leading and trailing spaces from a null-terminated ASCII string, modifying the string in place. Returns a pointer to the beginning of the string. In case the string occupies a heap memory block, in order to deallocate that block, the caller will need to retain the original pointer to it. This function does not handle UTF-8.
Signature
char *pszText);
Parameter
Slice Functions
SliceUtf8()
Returns a buffer containing the UTF-8 code points beginning at the given first index within the null-terminated content and ending at the last index.
Signature
const uint8_t *pContent,
int iFirst,
int iLast);
Parameters
Discussion
The developer is responsible for ensuring that the allocated buffer for UTF-8 content is deallocated via free(), once it is no longer in use. The performance is terrible, relative to ASCII substring functionality.
SliceAscii()
Similar to the SliceUtf8() function (above), but for ASCII text, and much faster.
Signature
const char *pContent,
int iFirst,
int iLast);
Parameters
Discussion
LenSliceUtf8()
Returns a buffer containing the UTF-8 code points beginning at the given first index within the length-limited content and ending at the last index.
Signature
const uint8_t *pContent,
int iFirst,
int iLast,
int lenContent);
Parameters
Discussion
The developer is responsible for ensuring that the allocated buffer for UTF-8 content is deallocated via free(), once it is no longer in use. The performance is terrible, relative to ASCII substring functionality.
LenSliceAscii()
Similar to the above function, but for ASCII text, and much faster.
Signature
const char *pContent,
int iFirst,
int iLast,
int lenContent);
Parameters
Discussion
Whole Content Comparison Functions
CompareUtf8()
Determines whether null-terminated UTF-8 content matches entirely. Returns true for matching content, and false otherwise.
Signature
const uint8_t *pContentA,
const uint8_t *pContentB);
Parameters
Discussion
CaseCompareUtf8()
Determines whether null-terminated UTF-8 content matches, entirely, after case folding. Returns true for matching content, and false otherwise. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContentA,
const uint8_t *pContentB);
Parameters
Discussion
LenCompareUtf8()
Determines whether UTF-8 content matches, up to a given number of code points or any terminating null. Returns true for matching content, and false otherwise. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContentA,
const uint8_t *pContentB,
int lenContent);
Parameters
Discussion
LenCaseCompareUtf8()
Determines whether UTF-8 content matches, up to a given number of code points or any terminating null, after case folding. Returns true for matching content, and false otherwise. Performs no UTF-8 validation other than null checking.
Signature
const uint8_t *pContentA,
const uint8_t *pContentB,
int lenContent);
Parameters
Discussion
SizeCompareUtf8()
Determines whether content matches, up to a specified number of bytes or any terminating null. Returns true for matching content, if the ranges begin and end at byte values consistent with valid code point boundaries, and false otherwise. Performs no further pointer validation and no further UTF-8 validation other than null checking.
Signature
const uint8_t *pContentA,
const uint8_t *pContentB,
size_t sizeContent);
Parameters
SizeCaseCompareUtf8()
Given a pair of byte ranges comprising UTF-8 content, determines whether the content matches after case folding. Returns true if the ranges begin and end at byte values consistent with valid code point boundaries and if there is a case-insensitive match. Returns false otherwise. Performs no further pointer validation and no further UTF-8 validation other than null checking.
Signature
const uint8_t *pContentA,
const uint8_t *pContentB,
size_t sizeContent);
Parameters
Example: Whole Content Comparison Tests (abridged)
// Compares content via each included whole-string comparison routine:
//
// CompareUtf8()
// CaseCompareUtf8()
// LenCompareUtf8()
// LenCaseCompareUtf8()
//
bool testcompare(uint8_t *pContentA, uint8_t *pContentB, int lenContent,
bool bCase, bool bExpectedResult)
{
size_t nSize; // Size of longer inbound content, in bytes
size_t nSizeContentB; // Size of content B
bool bPassed = true;
if (!lenContent)
{
if (bCase)
{
// Null-terminated, case-insensitive test.
if (bExpectedResult != CaseCompareUtf8(pContentA, pContentB))
{
bPassed = false;
}
}
else
{
// Null-terminated, case-sensitive test.
if (bExpectedResult != CompareUtf8(pContentA, pContentB))
{
bPassed = false;
}
}
}
else
{
if (bCase)
{
// Length-limited, case-insensitive test.
if (bExpectedResult != LenCaseCompareUtf8(pContentA, pContentB,
lenContent))
{
bPassed = false;
}
}
else
{
// Length-limited, case-sensitive test.
if (bExpectedResult != LenCompareUtf8(pContentA, pContentB,
lenContent))
{
bPassed = false;
}
}
}
if (bPassed && lenContent)
{
// Size-limited tests.
nSize = SizeOfLenUtf8(pContentA, lenContent);
nSizeContentB = SizeOfLenUtf8(pContentB, lenContent);
if (nSizeContentB > nSize)
{
nSize = nSizeContentB;
}
if (bCase)
{
if (bExpectedResult != SizeCaseCompareUtf8(pContentA, pContentB,
nSize))
{
bPassed = false;
}
}
else
{
if (bExpectedResult != SizeCompareUtf8(pContentA, pContentB,
nSize))
{
bPassed = false;
}
}
}
return bPassed;
}
// Correctness tests for case-sensitive and case-insensitive UTF-8-enabled
// routines for whole content comparison.
//
bool testset_compare(void)
{
int len = 0; // Rely on null string terminators.
bool bAllPassed = true;
do
{
bAllPassed &= testcompare(
(uint8_t *) "Oh, the monkeys have no tails in Zamboanga",
(uint8_t *) "Oh, the monkeys have no tails in Zamboanga",
(int) strlen("Oh, the monkeys have no tails in Zamboanga"),
/* bCase = */ false, /* bExpectedResult = */ true);
bAllPassed &= testcompare(
(uint8_t *) "Oh, the monkeys have no tails in Zamboanga",
(uint8_t *) "Oh, the monkeys have no tails in zamboanga",
(int) strlen("Oh, the monkeys have no tails in zamboanga"),
/* bCase = */ false, /* bExpectedResult = */ false);
// A snippet from the Rök Runestone inscription.
bAllPassed &= testcompare(
(uint8_t *) "ᛋᚭᚷᚹᛗ (ᛗ)ᛟᚷᛗᛖᚿᛃ (ᚦ)ᚭᛞ ᚺᛟᚭᛦ ᛃᚷᛟᛚᛞ ᚷᚭ ᛟᚭᛦᛃ ᚷᛟᛚᛞᛃᚿ ᛞ ᚷᛟᚭᚿᚭᛦ ᚺᛟᛋᛚᛃ",
(uint8_t *) "ᛋᚭᚷᚹᛗ (ᛗ)ᛟᚷᛗᛖᚿᛃ (ᚦ)ᚭᛞ ᚺᛟᚭᛦ ᛃᚷᛟᛚᛞ ᚷᚭ ᛟᚭᛦᛃ ᚷᛟᛚᛞᛃᚿ ᛞ ᚷᛟᚭᚿᚭᛦ ᚺᛟᛋᛚᛃ",
!len ? len : CodePointCountUtf8((uint8_t *) "ᛋᚭᚷᚹᛗ (ᛗ)ᛟᚷᛗᛖᚿᛃ (ᚦ)ᚭᛞ ᚺᛟᚭᛦ ᛃᚷᛟᛚᛞ ᚷᚭ ᛟᚭᛦᛃ ᚷᛟᛚᛞᛃᚿ ᛞ ᚷᛟᚭᚿᚭᛦ ᚺᛟᛋᛚᛃ"),
/* bCase = */ false, /* bExpectedResult = */ true);
// Positive and negative mixed-case comparisons.
bAllPassed &= testcompare(
(uint8_t *) "τεθνάκην δ' ὀλίγω 'πιδεύης φαίνομ' ἀλαία",
(uint8_t *) "ΤΕΘΝΆΚΗΝ Δ' ὈΛΊΓΩ 'ΠΙΔΕΎΗΣ ΦΑΊΝΟΜ' ἈΛΑΊΑ",
!len ? len : CodePointCountUtf8((uint8_t *) "τεθνάκην δ' ὀλίγω 'πιδεύης φαίνομ' ἀλαία"),
false, false);
bAllPassed &= testcompare(
(uint8_t *) "τεθνάκην δ' ὀλίγω 'πιδεύης φαίνομ' ἀλαία",
(uint8_t *) "ΤΕΘΝΆΚΗΝ Δ' ὈΛΊΓΩ 'ΠΙΔΕΎΗΣ ΦΑΊΝΟΜ' ἈΛΑΊΑ",
!len ? len : CodePointCountUtf8((uint8_t *) "τεθνάκην δ' ὀλίγω 'πιδεύης φαίνομ' ἀλαία"),
true, true);
} while (!len++);
return bAllPassed;
}
Partial Content Comparison Functions
FindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – returns a pointer to any first matching sequence within the larger content. Returns nullptr if no match is found. Performs no pointer validation and no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent,
uint8_t **ppLast);
Parameters
LenFindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – and a certain number of code points in each, returns a pointer to any first matching sequence within the larger content. Returns nullptr if no match is found. Performs no pointer validation and no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent,
int lenContent,
int lenSlice,
uint8_t **ppLast);
Parameters
CaseFindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – returns a pointer to any first matching sequence, within the larger content, after case folding. Returns nullptr if no match is found. Performs no pointer validation and no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent,
uint8_t **ppLast);
Parameters
LenCaseFindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – and a certain number of code points in each, returns a pointer to any first matching sequence, within the larger content, after case folding. Returns nullptr if no match is found. This function does not handle UTF-8. It performs no pointer validation..
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent,
int lenContent,
int lenSlice,
uint8_t **ppLast);
Parameters
LenFindAscii()
Given a pointer to an ASCII string and a pointer to a prospectively matching portion of text – i.e., what may be a substring – and a certain number of characters in each, returns a pointer to any first matching sequence within the larger string. Returns nullptr if no match is found. This function performs no pointer validation and does not handle UTF-8..
Signature
const char *pszText,
const char *pszSearchText,
int lenText,
int lenSlice,
char **ppLast);
Parameters
CaseFindAscii()
Given a pointer to an ASCII string and a pointer to a prospectively matching portion of text – i.e., what may be a substring – returns a pointer to any first matching sequence, within the larger string, after case folding. Returns nullptr if no match is found. This function does not handle UTF-8. It performs no pointer validation..
Signature
const char *pszText,
const char *pszSearchText,
char **ppLast);
Parameters
LenCaseFindAscii()
Given a pointer to an ASCII string and a pointer to a prospectively matching portion of text – i.e., what may be a substring – and a certain number of characters in each, returns a pointer to any first matching sequence, within the larger string, after case folding. Returns nullptr if no match is found. This function does not handle UTF-8. It performs no pointer validation..
Signature
const char *pszText,
const char *pszSearchText,
int lenText,
int lenSlice,
char **ppLast);
Parameters
IndexFindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – returns an index of any first matching sequence within the larger content. Returns -1 if no match is found. Performs no pointer validation and no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent);
Parameters
IndexLenFindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – and a certain number of code points in each, returns an index of to any first matching sequence within the larger content. Returns -1 if no match is found. Performs no pointer validation and no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent,
int lenContent,
int lenSlice);
Parameters
IndexCaseFindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – returns an index of any first matching sequence, within the larger content, after case folding. Returns -1 if no match is found. Performs no pointer validation and no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent);
Parameters
IndexLenCaseFindUtf8()
Given a pointer to UTF-8 content and a pointer to a prospectively matching portion of content – i.e., what may be a substring – and a certain number of code points in each, returns an index of any first matching sequence, within the larger content, after case folding. Returns -1 if no match is found. Performs no pointer validation and no UTF-8 validation other than null checking.
Signature
const uint8_t *pContent,
const uint8_t *pSearchContent,
int lenContent,
int lenSlice);
Parameters
IndexLenFindAscii()
Given a pointer to an ASCII string and a pointer to a prospectively matching portion of text – i.e., what may be a substring – and a certain number of characters in each, returns an index of any first matching sequence within the larger string. Returns -1 if no match is found. This function does not handle UTF-8. It performs no pointer validation..
Signature
const char *pszText,
const char *pszSearchText,
int lenText,
int lenSlice);
Parameters
IndexCaseFindAscii()
Given a pointer to an ASCII string and a pointer to a prospectively matching portion of text – i.e., what may be a substring – returns an index of any first matching sequence, within the larger string, after case folding. Returns -1 if no match is found. This function does not handle UTF-8. It performs no pointer validation..
Signature
const char *pszText,
const char *pszSearchText);
Parameters
IndexLenCaseFindAscii()
Given a pointer to an ASCII string and a pointer to a prospectively matching portion of text – i.e., what may be a substring – and a certain number of characters in each, returns an index of any first matching sequence, within the larger string, after case folding. Returns -1 if no match is found. This function does not handle UTF-8. It performs no pointer validation..
Signature
const char *pszText,
const char *pszSearchText,
int lenText,
int lenSlice);
Parameters
Example: Partial Content Comparison Tests (abridged)
// Compares content via each included substring comparison routine.
//
// FindUtf8()
// CaseFindUtf8()
// LenFindUtf8()
// LenCaseFindUtf8()
// LenFindAscii()
// LenCaseFindAscii()
//
bool testfind(uint8_t *pContent, uint8_t *pPattern,
int lenContent, int lenSliceContent,
bool bCase, int iExpectedOffset)
{
uint8_t *pSlice, *pSliceEnd;
char *pszSlice, *pszSliceEnd;
int iOffset;
bool bPassed = true;
if (!lenContent && !lenSliceContent)
{
if (bCase)
{
// Null-terminated, case-insensitive (Mode B) test.
pSlice = CaseFindUtf8(pContent, pPattern, &pSliceEnd);
}
else
{
// Null-terminated, case-sensitive (Mode A) test.
pSlice = FindUtf8(pContent, pPattern, &pSliceEnd);
}
}
else
{
if (bCase)
{
// Length-limited, case-insensitive (Mode B) test.
pSlice = LenCaseFindUtf8(pContent, pPattern,
lenContent, lenSliceContent, &pSliceEnd);
}
else
{
// Length-limited, case-sensitive (Mode A) test.
pSlice = LenFindUtf8(pContent, pPattern,
lenContent, lenSliceContent, &pSliceEnd);
}
}
if (pSlice)
{
iOffset = LenSizeOfUtf8(pContent, (size_t) (pSlice - pContent));
if (iExpectedOffset != iOffset)
{
bPassed = false;
}
}
else if (iExpectedOffset >= 0)
{
bPassed = false;
}
return bPassed;
}
// Correctness tests for case-sensitive and case-insensitive UTF-8-enabled
// routines for partial content comparison.
//
bool testset_find(void)
{
const int iNotFound = -1; // A mismatch gives us a negative offset.
const int iFoundAtFront = 0; // The strings begin with a match.
int len = 0; // Rely on null string terminators.
bool bAllPassed = true;
do
{
// Positive and negative mixed-case comparisons.
bAllPassed &= testfind(
(uint8_t *) "𐐀𐑌𐑊𐐪𐑉𐐽 𐐏𐐬𐑉 𐑅𐐬𐑊𐑆 𐐻𐐬𐐶𐐨𐑉𐐼 𐐊𐑄𐐲𐑉𐑆",
(uint8_t *) "𐐲𐑄𐐲𐑉𐑆",
!len ? len : CodePointCountUtf8((uint8_t *) "𐐀𐑌𐑊𐐪𐑉𐐽 𐐏𐐬𐑉 𐑅𐐬𐑊𐑆 𐐻𐐬𐐶𐐨𐑉𐐼 𐐊𐑄𐐲𐑉𐑆"),
!len ? len : CodePointCountUtf8((uint8_t *) "𐐊𐑄𐐲𐑉𐑆"),
/* bCase = */ false, iNotFound);
bAllPassed &= testfind(
(uint8_t *) "𐐀𐑌𐑊𐐪𐑉𐐽 𐐏𐐬𐑉 𐑅𐐬𐑊𐑆 𐐻𐐬𐐶𐐨𐑉𐐼 𐐊𐑄𐐲𐑉𐑆",
(uint8_t *) "𐐲𐑄𐐲𐑉𐑆",
!len ? len : CodePointCountUtf8((uint8_t *) "𐐀𐑌𐑊𐐪𐑉𐐽 𐐏𐐬𐑉 𐑅𐐬𐑊𐑆 𐐻𐐬𐐶𐐨𐑉𐐼 𐐊𐑄𐐲𐑉𐑆"),
!len ? len : CodePointCountUtf8((uint8_t *) "𐐊𐑄𐐲𐑉𐑆"),
/* bCase = */ true, /* iExpectedResult = */ 23);
bAllPassed &= testfind(
(uint8_t *) "𐐀𐑌𐑊𐐪𐑉𐐽 𐐏𐐬𐑉 𐑅𐐬𐑊𐑆 𐐻𐐬𐐶𐐨𐑉𐐼 𐐊𐑄𐐲𐑉𐑆",
(uint8_t *) "𐐻𐐬𐐶𐐨r𐐼",
!len ? len : CodePointCountUtf8((uint8_t *) "𐐀𐑌𐑊𐐪𐑉𐐽 𐐏𐐬𐑉 𐑅𐐬𐑊𐑆 𐐻𐐬𐐶𐐨𐑉d 𐐊𐑄𐐲𐑉𐑆"),
!len ? len : CodePointCountUtf8((uint8_t *) "𐐻𐐬𐐶𐐨r𐐼"),
/* bCase = */ true, iNotFound);
bAllPassed &= testfind(
(uint8_t *) "𞤀𞤤𞤳𞤵𞤤𞤫 𞤁𞤢𞤲𞤣𞤢𞤴𞤯𞤫 𞤂𞤫𞤻𞤮𞤤 𞤃𞤵𞤤𞤵𞤺𞤮𞤤",
(uint8_t *) "𞤫 𞤂𞤫𞤻𞤮𞤤",
!len ? len : CodePointCountUtf8((uint8_t *) "𞤀𞤤𞤳𞤵𞤤𞤫 𞤁𞤢𞤲𞤣𞤢𞤴𞤯𞤫 𞤂𞤫𞤻𞤮𞤤 𞤃𞤵𞤤𞤵𞤺𞤮𞤤"),
!len ? len : CodePointCountUtf8((uint8_t *) "𞤫 𞤂𞤫𞤻𞤮𞤤"),
/* bCase = */ false, /* iExpectedOffset = */ 14);
bAllPassed &= testfind(
(uint8_t *) "𞤀𞤤𞤳𞤵𞤤𞤫 𞤁𞤢𞤲𞤣𞤢𞤴𞤯𞤫 𞤂𞤫𞤻𞤮𞤤 𞤃𞤵𞤤𞤵𞤺𞤮𞤤",
(uint8_t *) "𞤫 𞤂𞤫𞤻𞤮𞤤",
!len ? len : CodePointCountUtf8((uint8_t *) "𞤀𞤤𞤳𞤵𞤤𞤫 𞤁𞤢𞤲𞤣𞤢𞤴𞤯𞤫 𞤂𞤫𞤻𞤮𞤤 𞤃𞤵𞤤𞤵𞤺𞤮𞤤"),
!len ? len : CodePointCountUtf8((uint8_t *) "𞤫 𞤂𞤫𞤻𞤮𞤤"),
/* bCase = */ true, /* iExpectedOffset = */ 14);
} while (!len++);
if (bAllPassed)
{
printf("Passed partial content comparison tests.\n");
}
else
{
printf("Failed partial content comparison tests.\n");
}
return bAllPassed;
}
Matching Wildcards Functions
The included functionality for matching wildcards – WildCompareUtf8() and related functions – comprises UTF-8-enabled variations of the FastWildCompare() function released in 2018. That ASCII-specific function is coded based on a rearrangement of WildTextCompare(), which was published in Dr. Dobb’s Journal in 2014. The FastWildCompare() function represents a significant performance improvement over WildTextCompare() in scenarios where the inbound text is empty or when no wildcards are in it.
The WildTextCompare() function, in turn, is a rearrangement of GeneralTextCompare(), which was published in Dr. Dobb’s Journal in 2008. The WildTextCompare() function represents a 5x performance improvement over GeneralTextCompare(), for wildcard-driven input, achieved based on empirical algorithmics. Findings based on line-by-line runtime analysis, with a performance profiler and a range of tests, drove a redesign in which the algorithm’s least-commonly-invoked logic was moved out of the main flow of control.
For more details on the evolution of this functionality for matching wildcards, refer to its interactive development timeline on the main developforperformance page.
WildCompareUtf8()
Implementation of FastWildCompare(), for null-terminated content comprising UTF-8 code points.
Signature
const uint8_t *pWild,
const uint8_t *pTame);
Parameters
Discussion
WildLenCompareUtf8()
Implementation of FastWildCompare(), for length-limited content comprising UTF-8 code points.
Signature
const uint8_t *pWild,
const uint8_t *pTame,
int lenWild,
int lenTame);
Parameters
Discussion
WildCaseCompareUtf8()
Case folding implementation of FastWildCompare(), for null-terminated content comprising UTF-8 code points.
Signature
const uint8_t *pWild,
const uint8_t *pTame);
Parameters
Discussion
WildLenCaseCompareUtf8()
Case folding implementation of FastWildCompare(), for length-limited content comprising UTF-8 code points.
Signature
const uint8_t *pWild,
const uint8_t *pTame,
int lenWild,
int lenTame);
Parameters
Discussion
Example: Matching Wildcards Tests (abridged)
// Compares a tame/wild content pair via each included routine for matching
// wildcards:
//
// WildCompareUtf8()
// WildCaseCompareUtf8()
// WildLenCompareUtf8()
// WildLenCaseCompareUtf8()
//
bool testwildcompare(uint8_t *pTame, uint8_t *pWild,
int lenTame, int lenWild,
bool bCase, bool bExpectedResult)
{
bool bPassed = true;
if (!lenTame && !lenWild)
{
if (bCase)
{
// Null-terminated, case-insensitive test.
if (bExpectedResult != WildCaseCompareUtf8(pWild, pTame))
{
bPassed = false;
}
}
else
{
// Null-terminated, case-sensitive test.
if (bExpectedResult != WildCompareUtf8(pWild, pTame))
{
bPassed = false;
}
}
else
{
if (bCase)
{
// Length-limited, case-insensitive test.
if (bExpectedResult != WildLenCaseCompareUtf8(
pWild, pTame, lenWild, lenTame))
{
bPassed = false;
}
}
else
{
// Length-limited, case-sensitive test.
if (bExpectedResult != WildLenCompareUtf8(
pWild, pTame, lenWild, lenTame))
{
bPassed = false;
}
}
}
return bPassed;
}
// Correctness tests for case-sensitive and case-insensitive UTF-8-enabled
// routines for matching wildcards.
//
bool testset_wildcompare_utf8(void)
{
int len = 0; // Rely on null string terminators.
bool bAllPassed = true;
do
{
// Simple correctness test with mixed content.
bAllPassed &= testwildcompare(
(uint8_t *) "🐂🚀♥🍀貔貅🦁★□√🚦€¥☯🐴😊🍓🐕🎺🧊☀☂🐉", (uint8_t *) "*☂🐉",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "🐂🚀♥🍀貔貅🦁★□√🚦€¥☯🐴😊🍓🐕🎺🧊☀☂🐉"),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "*☂🐉"),
/* bCase = */ false, /* bExpectedResult = */ true);
// Case-sensitive scenarios.
bAllPassed &= testwildcompare(
(uint8_t *) "AbCD", (uint8_t *) "abc?",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "AbCD"),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "abc?"),
/* bCase = */ true, /* bExpectedResult = */ true);
bAllPassed &= testwildcompare(
(uint8_t *) "AbC★", (uint8_t *) "abc?",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "AbC★"),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "abc?"),
/* bCase = */ true, /* bExpectedResult = */ true);
// Tests with symbolic content.
bAllPassed &= testwildcompare(
(uint8_t *) "b௵🌚Lah", (uint8_t *) "b?🌚?aH",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "b௵🌚Lah"),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "b?🌚?aH"),
/* bCase = */ true, /* bExpectedResult = */ true);
bAllPassed &= testwildcompare(
(uint8_t *) "b௵🌚Lah", (uint8_t *) "b?🌚?aH",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "b௵🌚Lah"),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "b?🌚?aH"),
/* bCase = */ false, /* bExpectedResult = */ false);
// Tests with internationalized content.
bAllPassed &= testwildcompare(
(uint8_t *) "ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.",
(uint8_t *) "??????????? શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે * શીખવું પડશે.",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે."),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "??????????? શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે * શીખવું પડશે."),
/* bCase = */ true, /* bExpectedResult = */ true);
bAllPassed &= testwildcompare(
(uint8_t *) "ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.",
(uint8_t *) "ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે હિબ્રુ ભાષા શીખવી પડશે.",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે."),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે હિબ્રુ ભાષા શીખવી પડશે."),
/* bCase = */ false, /* bExpectedResult = */ false);
} while (!len++);
if (bAllPassed)
{
printf("Passed matching wildcards tests.\n");
}
else
{
printf("Failed matching wildcards tests.\n");
}
return bAllPassed;
}
Targeted Wildcard Search Functions
The targeted wildcard search concept is described with introductory comments and graphical examples as part of the FastUtf8 overview. There’s also a discussion of the design of the ::pFindWild() and ::casepFindWild() methods for targeted wildcard search, together with an outline of a use case for handling user input. The underlying WildFindUtf8() case-sensitive function is documented here, along with related case-insensitive and length-limited functions. These functions implement the entire targeted wildcard search technique described in the design documentation related to the Uniseries::pFindWild() method, which merely determines which of these functions to invoke based on Uniseries flags.
The code of WildFindUtf8() and its family of functions is based on the code for matching wildcards found in WildCompareUtf8() and its family of functions. Conceptually, the WildFindUtf8() function is designed as though WildCompareUtf8() is situated within a larger loop that scans the inbound *ppFirst content for any code point that may serve as the beginning of a match against the pSearchPattern content. Each of the case-insensitive and length-limited functions of this Wild[Len][Case]FindUtf8() family is similarly designed as though the respective Wild[Len][Case]CompareUtf8() function is similarly incorporated.
WildFindUtf8()
Given null-terminated UTF-8 content, and given a null-terminated UTF-8 search pattern that can include ‘*’ and ‘?’ wildcards, searches the content for a match.
Signature
uint8_t **ppFirst,
const uint8_t *pSearchPattern,
uint8_t **ppLast,
uint8_t **ppTarget);
Parameters
Discussion
*ppLast will point to the location within the content where the match ends, and
*ppTarget will point to the location where the last matching portion of the content begins, i.e., the content corresponding to the portion of the search pattern after the last ‘*’ wildcard.
Returns a pointer to the beginning of the match, corresponding to the beginning of the search pattern. Performs no UTF-8 validation other than null checking.
WildLenFindUtf8()
Given length-limited UTF-8 content, and given a length-limited UTF-8 search pattern that can include ‘*’ and ‘?’ wildcards, searches the content for a match.
Signature
uint8_t **ppFirst,
const uint8_t *pSearchPattern,
int lenContent,
int lenPattern,
uint8_t **ppLast,
uint8_t **ppTarget);
Parameters
Discussion
WildCaseFindUtf8()
Given null-terminated UTF-8 content, and given a null-terminated UTF-8 search pattern that can include ‘*’ and ‘?’ wildcards, searches the content for a match. The comparison is performed with case folding, for a case-insensitive match.
Signature
uint8_t **ppFirst,
const uint8_t *pSearchPattern,
uint8_t **ppLast,
uint8_t **ppTarget);
Parameters
Discussion
WildLenCaseFindUtf8()
Given length-limited UTF-8 content, and given a length-limited UTF-8 search pattern that can include ‘*’ and ‘?’ wildcards, searches the content for a match. The comparison is performed with case folding, for a case-insensitive match.
Signature
uint8_t **ppFirst,
const uint8_t *pSearchPattern,
int lenContent,
int lenPattern,
uint8_t **ppLast,
uint8_t **ppTarget);
Parameters
Discussion
Example: Targeted Wildcard Search Tests (abridged)
// Value for an expected non-matching result.
size_t g_noMatch = ~(size_t) 0;
// Compares a content pair via each included routine for full-pattern-match
// search and for targeted wildcard search.
//
// When expectedTarget == g_noMatch (-1), an exact match is expected, not a
// wildcard match. The test will verify results from these functions:
//
// FindUtf8()
// CaseFindUtf8()
// LenFindUtf8()
// LenCaseFindUtf8()
// LenFindAscii()
// LenCaseFindAscii()
//
// When expectedMatch == g_noMatch, neither a wildcard match nor an exact
// match is expected.
//
// When expectedMatch and expectedTarget are set to positive integers, the
// test will verify results from these functions:
//
// WildFindUtf8()
// WildCaseFindUtf8()
// WildLenFindUtf8()
// WildLenCaseFindUtf8()
//
bool testwildfind(uint8_t *pContent, uint8_t *pPattern, int lenContent,
int lenPattern, size_t expectedFirst, size_t expectedLast,
size_t expectedMatch, size_t expectedTarget, bool bCase)
{
uint8_t *pMatch;
uint8_t *pTarget;
uint8_t *pFirst;
uint8_t *pLast;
bool bPassed = true;
int len = CodePointCountUtf8(pContent);
if (!lenContent && !lenPattern)
{
if (bCase)
{
// Null-terminated, case-insensitive test.
pFirst = CaseFindUtf8(pContent, pPattern, &pLast);
if (expectedTarget == g_noMatch)
{
if (pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast)
{
bPassed = false;
}
}
else if (pFirst && len)
{
bPassed = false;
}
pFirst = pContent;
pMatch = WildCaseFindUtf8(&pFirst, pPattern, &pLast, &pTarget);
if (expectedMatch != g_noMatch)
{
if (len &&
(pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast ||
pMatch - pContent != expectedMatch ||
pTarget - pContent != expectedTarget))
{
bPassed = false;
}
}
else if (pMatch)
{
bPassed = false;
}
}
else
{
// Null-terminated, case-sensitive test.
pFirst = FindUtf8(pContent, pPattern, &pLast);
if (expectedTarget == g_noMatch)
{
if (pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast)
{
bPassed = false;
}
}
else if (pFirst && len)
{
bPassed = false;
}
pFirst = pContent;
pMatch = WildFindUtf8(&pFirst, pPattern, &pLast, &pTarget);
if (expectedMatch != g_noMatch)
{
if (len &&
(pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast ||
pMatch - pContent != expectedMatch ||
pTarget - pContent != expectedTarget))
{
bPassed = false;
}
}
else if (pMatch)
{
bPassed = false;
}
}
}
else
{
if (bCase)
{
// Length-limited, case-insensitive test.
pFirst = LenCaseFindUtf8(
pContent, pPattern, lenContent, lenPattern, &pLast);
if (expectedTarget == g_noMatch)
{
if (pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast)
{
bPassed = false;
}
}
else if (pFirst && len)
{
bPassed = false;
}
pFirst = pContent;
pMatch = WildLenCaseFindUtf8(&pFirst, pPattern, lenContent,
lenPattern, &pLast, &pTarget);
if (expectedMatch != g_noMatch)
{
if (len &&
(pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast ||
pMatch - pContent != expectedMatch ||
pTarget - pContent != expectedTarget))
{
bPassed = false;
}
}
else if (pMatch)
{
bPassed = false;
}
}
else
{
// Length-limited, case-sensitive test.
pFirst = LenFindUtf8(
pContent, pPattern, lenContent, lenPattern, &pLast);
if (expectedTarget == g_noMatch)
{
if (pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast)
{
bPassed = false;
}
}
else if (pFirst && len)
{
bPassed = false;
}
pFirst = pContent;
pMatch = WildLenFindUtf8(&pFirst, pPattern, lenContent, lenPattern,
&pLast, &pTarget);
if (expectedMatch != g_noMatch)
{
if (len &&
(pFirst - pContent != expectedFirst ||
pLast - pContent != expectedLast ||
pMatch - pContent != expectedMatch ||
pTarget - pContent != expectedTarget))
{
bPassed = false;
}
}
else if (pMatch)
{
bPassed = false;
}
}
}
return bPassed;
}
// Correctness tests for case-sensitive and case-insensitive UTF-8-enabled
// routines for targeted wildcard search.
//
bool testset_targetedsearch_global(void)
{
int len = 0; // Rely on null string terminators.
bool bAllPassed = true;
size_t expectedFirst, expectedLast, expectedMatch, expectedTarget;
do
{
// Simple correctness test with mixed content.
expectedFirst = 4;
expectedLast = 22;
expectedMatch = 6;
expectedTarget = 13;
bAllPassed &= testwildfind(
(uint8_t *) "🌻miSsissip🌻🌻pi", (uint8_t *) "mi*Sip*",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "🌻miSsissip🌻🌻pi"),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "mi*Sip*"),
expectedFirst, expectedLast, expectedMatch, expectedTarget,
/* bCase = */ true);
// Tests with internationalized content.
expectedFirst = expectedLast = expectedTarget = 0;
expectedMatch = g_noMatch;
bAllPassed &= testwildfind(
(uint8_t *) "🐍Мне нужно выучить русский язык, чтобы лучше оценить Пушкина.",
(uint8_t *) "мне нужно выучить * язык, чтобы лучше оценить *.",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "🐍Мне нужно выучить русский язык, чтобы лучше оценить Пушкина."),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "мне нужно выучить * язык, чтобы лучше оценить *."),
expectedFirst, expectedLast, expectedMatch, expectedTarget,
/* bCase = */ false);
expectedFirst = 4;
expectedLast = 113;
expectedMatch = 37;
expectedTarget = 98;
bAllPassed &= testwildfind(
(uint8_t *) "🐍Мне нужно выучить русский язык, чтобы лучше оценить Пушкина.",
(uint8_t *) "мне нужно выучить * язык, чтобы * ???????.",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "🐍Мне нужно выучить русский язык, чтобы лучше оценить Пушкина."),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "мне нужно выучить * язык, чтобы * ???????."),
expectedFirst, expectedLast, expectedMatch, expectedTarget,
/* bCase = */ true);
expectedFirst = 13;
expectedLast = 168;
expectedMatch = 29;
expectedTarget = 132;
bAllPassed &= testwildfind(
(uint8_t *) "😍😍😍 ᛋᚭᚷᚹᛗ (ᛗ)ᛟᚷᛗᛖᚿᛃ (ᚦ)ᚭᛞ ᚺᛟᚭᛦ ᛃᚷᛟᛚᛞ ᚷᚭ ᛟᚭᛦᛃ ᚷᛟᛚᛞᛃᚿ ᛞ ᚷᛟᚭᚿᚭᛦ ᚺᛟᛋᛚᛃ",
(uint8_t *) "ᛋᚭᚷᚹᛗ * (ᚦ)ᚭᛞ ᚺᛟᚭᛦ ᛃᚷᛟᛚᛞ ᚷᚭ ᛟᚭᛦᛃ * ᛞ ?????? ᚺᛟᛋᛚᛃ",
/* lenTame = */ !len ? len : CodePointCountUtf8((uint8_t *) "😍😍😍 ᛋᚭᚷᚹᛗ (ᛗ)ᛟᚷᛗᛖᚿᛃ (ᚦ)ᚭᛞ ᚺᛟᚭᛦ ᛃᚷᛟᛚᛞ ᚷᚭ ᛟᚭᛦᛃ ᚷᛟᛚᛞᛃᚿ ᛞ ᚷᛟᚭᚿᚭᛦ ᚺᛟᛋᛚᛃ"),
/* lenWild = */ !len ? len : CodePointCountUtf8((uint8_t *) "ᛋᚭᚷᚹᛗ * (ᚦ)ᚭᛞ ᚺᛟᚭᛦ ᛃᚷᛟᛚᛞ ᚷᚭ ᛟᚭᛦᛃ * ᛞ ?????? ᚺᛟᛋᛚᛃ"),
expectedFirst, expectedLast, expectedMatch, expectedTarget,
/* bCase = */ false);
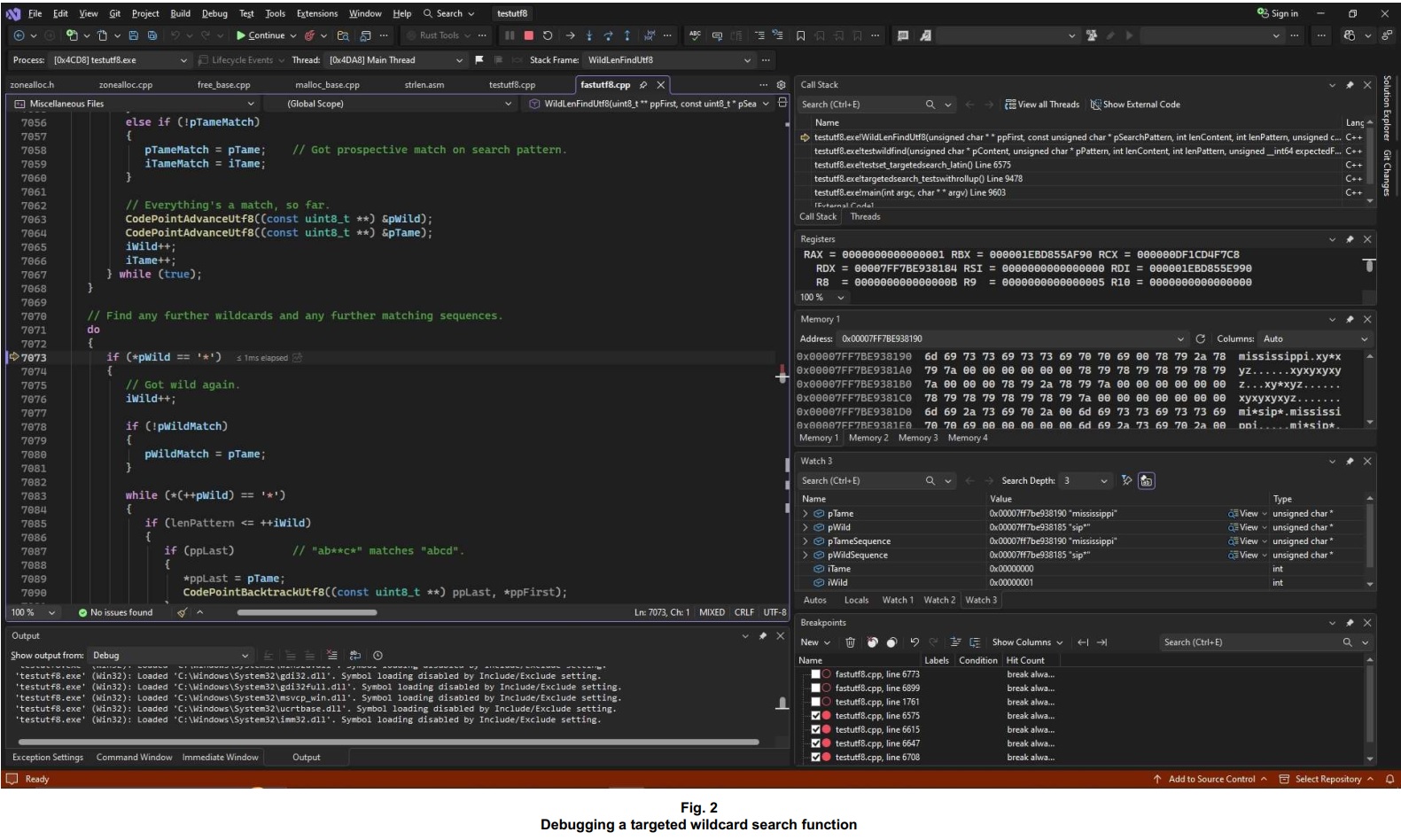
// The test getting debugged in the screenshot below.
expectedFirst = 0;
expectedLast = 10;
expectedMatch = 0;
expectedTarget = 9;
bAllPassed &= testwildfind(
(uint8_t *) "mississippi", (uint8_t *) "*sip*",
CodePointCountUtf8((uint8_t *) "mississippi"),
CodePointCountUtf8((uint8_t *) "*sip*"),
expectedFirst, expectedLast, expectedMatch, expectedTarget, /* bCase = */ false);
} while (!len++);
if (bAllPassed)
{
printf("Passed targeted wildcard search tests.\n");
}
else
{
printf("Failed targeted wildcard search tests.\n");
}
return bAllPassed;
}
Considerations for C++ Developers
The functions described above are provided mainly for legacy C compatibility. Are there scenarios where C++ code might preferably call them instead of working with FastUtf8::Uniseries objects? Most Uniseries operators and methods are based on the above functions, and all of the functions are covered one way or another via a Uniseries interface. A situation where you might skip the Uniseries and invoke one of these C functions directly might look like one of these:
- you need to mix UTF-8 functionality with a case folding (or other) internationalization technique from a different source, e.g., for compatibility with encodings besides UTF-8,
- you’d like to bypass Uniseries construction with its up-front UTF-8 validation step, or
- you’re developing code compatible with legacy C.
In most situations where UTF-8 is your encoding of choice, C++ code can best rely on Uniseries objects. The objects are aware of their own content – specifically, whether it’s all 7-bit ASCII text – and the Uniseries methods are optimized accordingly. The step of Uniseries construction does involve UTF-8 validation, which entails a slowdown relative to construction of a typical ASCII string object. But once that’s done, any remaining ASCII processing can happen with virtually no slowdown, even if your project includes code that’ll do revalidation for safety. Other than that performance impact at Uniseries construction time, UTF-8-ready code can run with about the same 7-bit ASCII performance as code that lacks UTF-8-enablement.
Complete source code for the Fast UTF-8 project for legacy C is available at GitHub > kirkjkrauss > FastUtf8 > LegacyC. The above source code listings are extracted from the testutf8.c file included with that code. The listings are formatted using the SyntaxHighlighter library, copyright (c) 2004-2013, Alex Gorbatchev.
All other materials copyright © 2026 developforperformance.com.
C++ and its logo are trademarks of the Standard C++ Foundation. Windows® and Visual Studio® are trademarks or registered trademarks of Microsoft Corp. Unix® is a registered trademark of The Open Group. Linux® is a registered trademark of Linus Torvalds. Ubuntu® is a registered trademark of Canonical Ltd.