Matching Wildcards in Rust
By Kirk J Krauss
What’s Here
- Optimized, tested, paste-in-and-use functions for matching wildcards:
- Fast wildcard matching for ASCII text.
- Case-sensitive and case-insensitive wildcard matching, based on the same algorithm, that’s UTF-8-ready.
- Rust implementation of the complete ASCII test set originally shared with – and informed by suggestions from – many contributors among the C/C++ developer community.
- New UTF-8 test set targeting matching wildcards in internationalized / symbolic content.
- Performance comparison against the original C/C++ routines.
- Thoughts on the philosophy that’s guided pre-existing means of matching wildcards in Rust.
Why Recode a Readily Callable C/C++ Pattern Matching Function in Rust?
The Rust™ programming language provides features crucial to high performance computing. Any compute-intensive task that can safely parallelize its work across multiple processors, using threads, stands to take full advantage of today’s commonplace multi-core systems. Yet no bugs are tougher to solve than the race conditions that can arise, in multithreaded code, developed using most any programming language besides Rust.
Rust achieves a remarkable degree of thread safety by enforcing a simple limitation: no more than one mutable reference to any memory block is permitted concurrently. Classic algorithms whose ordinary function involves multiple pointers to certain blocks have to be rethought, to be implemented in Rust. How to decide whether rethinking a particular algorithm might be useful? I’ve advocated studying the trade-offs between multiprocessor-exploitive design and thread safety, for tasks where these trade-offs may matter. One algorithm that would seem worth the rethinking is my algorithm for matching wildcards. On its own, it’s not multithreaded, but most of its native code implementations accept pointers to strings that can reside in heap memory shared among threads. Certain race conditions might confuse it.
The wildcards include the ‘*’ symbol, which can match any number (0+) of text elements (characters or code points), and the ‘?’ symbol, which can match exactly 1 element. This is probably the most common wildcard syntax. The venerable Windows command...
dir *.*
...originally meant, effectively, “Give me a listing of every pathname, within the current directory, that has a ‘.’ ASCII character in it.” (In current versions of Windows, the ‘.’ symbol is a path component representing the current directory.) The ‘?’ symbol has served all along as a single-element wildcard in the Windows command environment. In some contexts there are other syntaxes. With Rust’s own built-in pattern matching functionality, the ‘_’ symbol more or less replaces the traditional ‘*’ wildcard.
The loss of thread safety enforcement isn’t the only consideration to keep in mind when calling C/C++ code from Rust. There also are performance considerations. A C-style string requires a null terminator, and Rust code typically must tack on the null prior to passing a string to C/C++ code. The Rust code to do this may appear succinct, but the penalty is the slowdown caused by walking the entire string and possibly making an entire copy. The overhead can negate any performance benefit that an optimized C/C++ routine may have offered in the Rust environment.
Why live with overhead like that, when Rust’s string content is not only efficiently manageable without any need for C/C++, but also UTF-8-encoded? Most any routine that’s good for ASCII also may be good for UTF-8. With Rust, as we’ll see, high-performance code for use with ASCII text can be nearly identical to UTF-8-ready code. The maintainability of two nearly identical functions may not quite match that of just one function. Then again, there’s no easy fully-interoperable way – at least, none that comes to mind for me – to implement my algorithm in a UTF-8-ready form in C/C++. With Rust, it’s as easy as making a switch to one of the built-in data types. Though the UTF-8 implementation now coded in Rust may be applied for any matching wildcards scenario, as we’ll see, test findings show that the ASCII implementation provides about a 10x performance gain, for ASCII text, over the UTF-8 implementation.
Nevertheless, the UTF-8 version can perform millions of matching wildcards findings per second. It’s a competitive choice for general purpose cases of matching wildcards in case sensitive, case-insensitive, ASCII, and symbolic and internationalized UTF-8 contexts. The ASCII version is useful for situations where native code developed in Rust must perform about as well as pointer-based C/C++ code for matching wildcards. Testing with optimized release builds shows that the ASCII implementation in Rust can perform about as well as the C/C++ implementation from which it’s derived.
In a nutshell: if you know your matching wildcards needs involve just ASCII text, and you don’t need case insensitivity, the ASCII version is hard to beat. All the code you need is in Listing One, below. Otherwise, the UTF-8 version has got you covered. That’s in Listings Two and Three.
When I first needed code for matching wildcards, around 2007, I had no idea that I’d find myself developing a new algorithm. I thought the problem of matching a character string against a pattern containing the ‘*’ and ‘?’ symbols, for multi-character and single-character wildcards respectively, had been solved in the days of text-based terminals. I was working on a wildcard-based filter manager for a set of products whose job was to analyze native code for runtime quality factors including safe memory usage, performance, and code coverage. For these products, I wanted functionality that would be as foolproof as possible. A tool for ensuring software quality at runtime would look silly if it were to break down, itself, under pressure of some pathological user input.
Surprisingly, the only well-documented implementations I found at the time for matching wildcards were recursive. Recursive code may be safe, if it’s applied to data with known limits chosen to prevent a stack overflow. I preferred to avoid placing hard limits on what a user of my filter manager might want to filter. Certainly limitations based on fear of a stack overflow seemed needless, since I was sure there’d be a way to code the needed pattern matching logic without recursion. So I developed a C/C++ routine based on a single while loop and began testing it.
Testing the routine turned out to be far trickier than I’d expected. As I tweaked the routine, I found and fixed bugs, and refactored the while loop, until I had a somewhat lengthy set of testcases for various arrangements of the ‘*’ and ‘?’ wildcards. Realizing I was developing my way into a novel method for matching wildcards, I shared it with a team of developers who handled new inventions for the organization where I was working. Members of that team studied my code, including my set of testcases. Some of them suggested further test inputs. As a group, that team decided the code should be published, so that it would be free to use both within and outside of the organization.
Given that guidance, I shared the routine and testcases with the editors of Dr. Dobb’s Journal, who published them in August of 2008. There was a spirited response from several DDJ readers who had suggestions for improved correctness and performance. I added the needed testcases and implemented the performance improvements, which had come to mind based on a cache-oriented view of the loop’s logic. The updates were published, to positive feedback.
The experience left me wondering if I’d missed any opportunities for yet more improvements. Over time, several other routines for matching wildcards using while loops became popular. As I contemplated the performance characteristics of the various methods. I used a performance profiler to discover how much time was spent in various basic blocks as my routine ran. Looking at the profiling results yielded insights that led me to rearrange the algorithm. I saw that the least commonly needed logic could be less commonly invoked than it had been within the 2008 code.
The result of that profiler-inspired redesign was another DDJ article featuring the updated code, published in 2014. This time, no concerns arose regarding either correctness or overall performance. But a simple idea from one reader eventually sent me back to the drawing board anyway.
The idea was about null, or empty, input strings. An implementation directly driven by the user, such as the filter manager that started me on the path of inventing algorithms for matching wildcards, might seldom have to deal with empty input. But in the world of big data, where high-performance pattern matching code could get heavy usage, empty input is normal. Big data often takes the form of sparse data, and suboptimal handling of empty strings can become costly at scale. A good design for that use case would call for up-front checks, followed by lowest-cost continuing end-of-string checks throughout processing prior to finding any ‘*’ wildcard.
Based on further profiler guidance, I split processing into two while loops – one that handles input up to any ‘*’ wildcard that may be present, and another that manages the set of pointers needed to track possible matching sequences after the wildcard. This resulted in the best average performance yet, at least for my testcases, and quite nicely improved performance for empty-string and all-tame scenarios. I also implemented a portable version of the algorithm that relies on array-style string indexing, rather than pointers. Both versions, and a more complete description of how I arrived at them, are available and free for public use. I’ve also implemented a JavaScript® version that’s very similar, code-wise, to the portable C/C++ version.

Throughout this history, many developers have contributed not only ideas inspiring the implementations themselves but also guidance toward a thorough set of testcases. That test set has played a key role in making the implementations both as correct and as fast as they are. As Cem Kaner has put it, “Designing good test cases is a complex art.” For the Rust implementations, I’ve come up yet more tests, this time with UTF-8 support in mind. I don’t know of any set of testcases for matching wildcards as complete as this set of testcases now coded in Rust.
Existing Means for Matching Wildcards in Rust
A fascinating aspect of Rust, besides its thread safety features, is that it’s built from the ground up to support UTF-8 encodings. This gives developers a standard internationalization mechanism for native code: no need to get used to any of several competing third-party components, overcomplicated libraries, or some collection of necessary iterators and accessors that would otherwise turn an algorithm for matching wildcards into a whole family of methods that would likely need validation of UTF-8 syntax, overloading of operators, and other complexity. UTF-8 includes standard code points for the ‘*’ and ‘?’ wildcards. As we shall see, Rust provides just what’s needed to develop a single routine for matching those wildcards in any internationalized context supported by UTF-8.
Rust’s regex crate also provides support for matching regular expressions. These can be tricky to use — and sometimes even the decision to work with them can be tricky. On one hand, they offer a wide range of character pattern matching features, including support for matching wildcards. On the other hand, they require a syntax of their own that may not be entirely consistent from one environment (such as Notepad++, where you can easily play around with them) to another (such as Rust).
In some cases, it makes perfect sense to apply the flexibility of regular expressions. But considering the relative simplicity of algorithms dedicated to ‘*’ and ‘?’ wildcard pattern matching, we can get far better performance. When I implemented my matching wildcards algorithm in JavaScript®, it provided performance at least two orders of magnitude improved over the simplest routine I could find based on JavaScript’s built-in RegExp() functionality. And my routine was running as interpreted code in FireFox.
I compared my interpreted JavaScript code against RegExp()-based code only because I found no other routines, at the time, for matching wildcards in JavaScript. For native code, a better comparison of implementations – that is, apples-to-apples – would involve pitting a routine developed in Rust against a pointer-based C/C++ routine. As far as I can tell, no one has developed a routine for matching wildcards in Rust that has performed well enough to call for a comparison against a C/C++ or other native code routine. Dedicated routines for matching ‘*’ and ‘?’ wildcards in Rust do exist. I’ve found one whose performance is compared to a regex-based implementation, similar to what I’ve done for my interpreted JavaScript routine.
The existing dedicated routines for matching ‘*’ and ‘?’ wildcards in Rust – at least, those that I’ve found – are unlike any code I’ve seen before. What they have in common: they wrap or emulate Rust’s built-in match expression. That language feature is commonly used for pattern matching involving values, data structures, or tuples. It wasn’t designed with text strings specifically in mind, and it doesn’t inherently recognize the ‘*’ and ‘?’ wildcards commonly used for text-based pattern matching.
Wrapping or emulating built-in functionality, in order to extend the features of a programming language toward supporting a needed use case, may be part of the Rust philosophy. This philosophy isn’t new with Rust. The strengths and limitations of program design via language extension has been subject to thoughtful consideration, long before Rust existed.
In 1984, among bookstores at hometown shopping malls and sidestreets, a slim volume appeared whose second paragraph made this broad statement about software development:
We need a consistent and practical methodology for thinking about software problems.
The book was titled Thinking Forth: A Language and Philosophy for Solving Problems, by Leo Brodie. Its first chapter provided “a history of the tools and techniques for writing more elegant programs” including (among other topics) successive refinement, structured and hierarchical design, information hiding, and the limitations of such techniques. That history concluded with a statement as relevant today as it was in 1984:
A design in which modules are grouped according to things that may change can readily accommodate change.
Leo Brodie’s book goes on to describe the Forth approach, characterizing it this way:
Forth is a language and an operating system. But that’s not all: It’s also the embodiment of a philosophy.
Key to that philosophy is the concept of language extensibility:
Forth programming consists of extending the root language toward the application, providing new commands that can be used to describe the problem at hand.
The author contrasts the Forth philosophy with trends such as object-oriented development and general-purpose code, with takeaways consistently embracing simplicity and resilience in the face of change:
Generality usually involves complexity. Don’t generalize your solution any more than will be required; instead, keep it changeable.
The Thinking Forth approach, which stands as an alternative to those still-popular trends, is relevant to programming languages other than Forth. The approach largely boils down to specific simplifications that can be applied in one circumstance or another. Unlike a matter of choosing a design pattern, generic function, or some popular best practice that might apply, the simplifications Leo Brodie suggests involve stepping back from the code and considering what it does, with the idea of making it simpler.
This may sound, well, simplistic. But the simplifications of Thinking Forth are expressed in the form of thought-provoking tips informed by real world experiences that the author presents in terms of working products, troublesome defects, and concerned customers. Too many of the trends in computing, since Thinking Forth disappeared from bookstore shelves, have been instigated by those who have little or no claim to that kind of experience. So it’s no surprise that software has become increasingly complex. Famous race conditions like the Therac-25 and Dirty COW incidents, among many others, are in part the result of neglecting the importance of simplicity, both in code and in overall product design. Which sort of simplicity might come to mind when developers begin “thinking Forth?” One of the simplications called for by the author is this:
To simplify, take advantage of what’s available.
That’s what the developers of the existing means of matching wildcards in Rust have done. We can see that it’s an overall-recommended approach since at least 1984, if not earlier. Still, in the context of simplification, Leo Brodie’s book points out the importance of “the correspondence between source code and machine execution... This simplification improves performance in several ways...” Yet of those several ways, those described in terms of language extension don’t apply to an algorithmic function comprising conditional logic.
On one hand, Forth programming revolves around extenisble lexicons:
Forth is expressed in words...
All words, whether included with the system or user-defined, exist in the “dictionary,” a linked list. A “defining word” is used to add new names to the dictionary.
In many scenarios, the lexicons indeed set the stage for code simplification. Words can be defined specifically to encapsulate conditional logic, thus minimizing control structures in typical code:
By using the Forth dictionary properly, we’re not actually eliminating conditionals; we’re merely factoring them out from our application code. The Forth dictionary is a giant string case statement. The match and execute functions are hidden within the Forth system.
On the other hand, there are situations where conditional logic must come to the forefront, to achieve both performance and elegance – even in Forth, a language deeply rooted in the concept of extending itself toward software solutions. Regarding the use of conditional logic, Leo Brodie writes:
The most elegant code is that which most closely matches the problem. Choose the control structure that most closely matches the control-flow problem.
Matching wildcards, like most any pattern matching algorithm, typically relies entirely on conditional logic. Philosopher Daniel Dennett has made a strong case for characterizing algorithms as platform-neutral. He makes an example of long division, which works on paper, parchment, whiteboards, light shows, or display screens.
Because matching wildcards is algorithmic, there’s no need for an implementation to require a family of functions, a mixture of higher-level and lower-level code, or a new instance of anything that would necessarily need to be packaged in a crate. Ideally, a routine for matching wildcards is coded as a single function that can be copied and pasted into the source file where it’s going to get called. And there it’s likely to remain, unchanging, as changes happen in the code around it. Over time, language features such as Rust’s pattern-matching facility may evolve, yet there will be little or no need to change an all-logic function that’s been independently optimized and tested.
The point of this philosophical investigation is not to criticize past efforts toward matching wildcards in Rust. Rather, the concept of extending the language’s built-in features toward handling the complexity involved is instructive. The result has been some unique approaches to the problem. Any Rust developer who’d like to understand a useful language extension scenerio, or a demonstration of the flexibility of the built-in pattern matching functionality, might get some good ideas from the existing means for matching wildcards in Rust. The existing code also may be reasonably fit for the purposes where it’s so far been applied. I’ve brought up philosophy to legitimize implementing an algorithmic solution, developed and tested using other programming languages, in Rust, given that those earlier Rust solutions are known and respected already.
There’s also the simple fact that not every solution for matching wildcards based on Rust’s pattern matching features is designed to handle UTF-8 encodings. Perhaps none of them are UTF-8-ready. Neither is the code on which I’ve based my implementation, but to the credit of the Rust language, it has made applying my algorithm to handle UTF-8 a matter of just relying on a built-in data type different from that used for ASCII. The simplicity of switching over to that data type is all the more impressive because before I even got started thinking UTF-8, I’d already implemented my algorithm in Rust thinking nothing but ASCII.
Matching Wildcards – ASCII Version
In Rust, a String is the most common data type used for representing a sequence of characters. It’s UTF-8-encoded and stored on the heap, so that it can be referenced across routines. It includes a length and a capacity, but not a null terminator. A terminating element at the end a UTF-8-encoded string would make little sense, in most circumstances. The code points that represent the String’s content are of variable length, so “walking” the String means knowing the size of each element. Knowing the element sizes and the overall String length, the iterator that ’s used to walk the String knows when it reaches the end, so there’s no need to check for a terminator.
We can implement most text-walking algorithms in Rust by arranging them to use one of Rust’s mechanisms for iterating over Strings. But that won’t work for algorithms that rely on multiple mutable references to a String. Disallowing multiple mutable references is crucial to Rust’s way of providing for fearless concurrency. One way a race condition could occur, if multiple mutable references were allowed, would be for some thread to make changes to content that our routine for matching wildcards was concurrently trying to walk. What could go wrong? Ask anyone who’s spent hours debugging too many race conditions to share a short answer about just which misbehavior might be observed. The underlying possibilities are that the memory where the content resides could be deallocated, reallocated, or otherwise modified before the routine has finished processing the content.
Because race conditions affecting sophisticated code have often stymied the best efforts of competent developers to stamp them out, we can appreciate the fact that an algorithm can’t be implemented in Rust to use more than one live iterator to walk a heap-allocated String. For matching wildcards, we need only two indices into the characters comprising each String, instead. Rust allows us to index into a stack-allocated data type known as &str, which is easily (and efficiently) created from a String.
One problem remains: the &str, like the String from which it’s so efficiently created, is not null-terminated. What’s needed, for matching wildcards, is a set of length checks to replace the terminator checks that appear in the original C/C++ code. That code takes advantage of some optimizations based on the fact that the null character is distinct from any other characters in a string. We’re bound to see a slowdown, in any logic-driven Rust routine for matching wildcards, involving the need for the length checks plus the loss of those optimization opportunities.
The most direct conversion of the C/C++ code into Rust code would call for placing a length check wherever the original code has a null check. This would result in added logic that would become positively ugly in the second loop, where we’d have to pile multiple length checks (for both the “wild” and “tame” &strs) into an already-complex if statement. In this case, logic can be saved by logic: the only substantive change I’ve made to the algorithm, in the Rust implementation, is to cut down on the number of length checks by relying on them once they’ve been done, for each loop iteration. The logic of the second loop is only slightly rearranged to achieve that optimization, but the result is a function that looks considerably more elegant than it would in a “line-for-line translation” from the original code. The resulting Rust implementation, for ASCII text, appears in Listing One.
Listing One
// Rust implementation of FastWildCompare(), for ASCII text.
//
// Copyright 2025 Kirk J Krauss. This is a Derivative Work based on
// material that is copyright 2018 IBM Corporation and available at
//
// http://developforperformance.com/MatchingWildcards_AnImprovedAlgorithmForBigData.html
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// Compares two ASCII &str's. Accepts '?' as a single-character wildcard.
// For each '*' wildcard, seeks out a matching sequence of any characters
// beyond it. Otherwise compares the &str's a character at a time.
//
pub fn fast_wild_compare_ascii(
wild_str: &str,
tame_str: &str) -> bool
{
let mut iwild: usize = 0; // Index for both input &str's in upper loop
let mut itame: usize; // Index for tame &str, used in lower loop
let mut iwild_sequence: usize; // Index for prospective match after '*'
let mut itame_sequence: usize; // Index for prospective match in tame &str
// Find a first wildcard, if one exists, and the beginning of any
// prospectively matching sequence after it.
loop
{
// Check for the end from the start. Get out fast, if possible.
if tame_str.len() ‹= iwild
{
if wild_str.len() › iwild
{
while wild_str.as_bytes()[iwild] == '*' as u8
{
iwild += 1;
if wild_str.len() ‹= iwild
{
return true; // "ab" matches "ab*".
}
}
return false; // "abcd" doesn't match "abc".
}
else
{
return true; // "abc" matches "abc".
}
}
else if wild_str.len() ‹= iwild
{
return false; // "abc" doesn't match "abcd".
}
else if wild_str.as_bytes()[iwild] == '*' as u8
{
// Got wild: set up for the second loop and skip on down there.
itame = iwild;
loop
{
iwild += 1;
if wild_str.len() ‹= iwild
{
return true; // "abc*" matches "abcd".
}
if wild_str.as_bytes()[iwild] == '*' as u8
{
continue;
}
break;
}
// Search for the next prospective match.
if wild_str.as_bytes()[iwild] != '?' as u8
{
while wild_str.as_bytes()[iwild] != tame_str.as_bytes()[itame]
{
itame += 1;
if tame_str.len() ‹= itame
{
return false; // "a*bc" doesn't match "ab".
}
}
}
// Keep fallback positions for retry in case of incomplete match.
iwild_sequence = iwild;
itame_sequence = itame;
break;
}
else if wild_str.as_bytes()[iwild] != tame_str.as_bytes()[iwild] &&
wild_str.as_bytes()[iwild] != '?' as u8
{
return false; // "abc" doesn't match "abd".
}
iwild += 1; // Everything's a match, so far.
}
// Find any further wildcards and any further matching sequences.
loop
{
if wild_str.len() › iwild && wild_str.as_bytes()[iwild] == '*' as u8
{
// Got wild again.
loop
{
iwild += 1;
if wild_str.len() ‹= iwild
{
return true; // "ab*c*" matches "abcd".
}
if wild_str.as_bytes()[iwild] != '*' as u8
{
break;
}
}
if tame_str.len() ‹= itame
{
return false; // "*bcd*" doesn't match "abc".
}
// Search for the next prospective match.
if wild_str.as_bytes()[iwild] != '?' as u8
{
while tame_str.len() › itame &&
wild_str.as_bytes()[iwild] != tame_str.as_bytes()[itame]
{
itame += 1;
if tame_str.len() ‹= itame
{
return false; // "a*b*c" doesn't match "ab".
}
}
}
// Keep the new fallback positions.
iwild_sequence = iwild;
itame_sequence = itame;
}
else
{
// The equivalent portion of the upper loop is really simple.
if tame_str.len() ‹= itame
{
if wild_str.len() ‹= iwild
{
return true; // "*b*c" matches "abc".
}
return false; // "*bcd" doesn't match "abc".
}
if wild_str.len() ‹= iwild ||
wild_str.as_bytes()[iwild] != tame_str.as_bytes()[itame] &&
wild_str.as_bytes()[iwild] != '?' as u8
{
// A fine time for questions.
while wild_str.len() › iwild_sequence &&
wild_str.as_bytes()[iwild_sequence] == '?' as u8
{
iwild_sequence += 1;
itame_sequence += 1;
}
iwild = iwild_sequence;
// Fall back, but never so far again.
loop
{
itame_sequence += 1;
if tame_str.len() ‹= itame_sequence
{
if wild_str.len() ‹= iwild
{
return true; // "*a*b" matches "ab".
}
else
{
return false; // "*a*b" doesn't match "ac".
}
}
if wild_str.len() › iwild && wild_str.as_bytes()[iwild] ==
tame_str.as_bytes()[itame_sequence]
{
break;
}
}
itame = itame_sequence;
}
}
// Another check for the end, at the end.
if tame_str.len() ‹= itame
{
if wild_str.len() ‹= iwild
{
return true; // "*bc" matches "abc".
}
return false; // "*bc" doesn't match "abcd".
}
iwild += 1; // Everything's still a match.
itame += 1;
}
}
Matching Wildcards – UTF-8 Version
“Test, then code.” I consider that statement the most helpful software development tip I’ve come across since I sat at my first computer (which is long gone) with first editions of Leo Brodie’s books on Forth (which are still close by my current computer). Thinking Forth remains the relevant guide that it always has been, though I haven’t done any Forth development in a long time. One reason is that Forth, like most legacy environments, remains largely centered around ASCII. The same tends to be true of legacy algorithm implementations and the tests available for them.
The ASCII legacy remains so predominant that if there’s any drop-in-and-use native code routine dedicated to matching ‘*’ and ‘?’ wildcards in UTF-8-encoded content, I haven’t seen it before. A web search for a simple function for matching wildcards in native code – one that’s advertised as having been tested against UTF-8 content – turned up nothing, for me, at the time of writing. Yet our 21st century world communicates using UTF-8. It’s the standard encoding for web pages, email, and non-legacy databases, operating systems, and programming languages.
Ongoing efforts remain toward adoption of “UTF-8 everywhere” especially for native code. That dream takes time to come true. What could better signify ASCII’s prevalence than the unavailability of UTF-8-specific testcases – until now – for such everyday functionality as matching wildcards? There’s no reason to impose limitations on the ‘*’ and ‘?’ wildcards so that they can be applied among, say, just Latin characters. Communication in virtually all modern languages has picked up modern conventions. Not only words like “computer” but also the symbols often used in computing have become commonplace internationally. The possibilities opened by the variety of non-linguistic symbols incorporated, too, in UTF-8, could inspire some wildcard-matching creativity.
Why isn’t this the place where I share the new UTF-8 tests I’ve created, ahead of the code for handling them? The workflow didn’t happen that way, because my predecessors’ work on matching wildcards had me “thinking Forth” – specifically, with Leo Brodie’s tip in mind: ”To simplify, take advantage of what’s available.” There are times when “thinking Forth” leads straight to “thinking Rust” to arrive at a simple solution that’ll readily pass tests.
That is, I found myself once again considering both the tests and the methodology my algorithm would need, this time for UTF-8 enablement – then I realized Rust has the needed methodology. The thought process went like this: Since the ordinary Rust String is UTF-8-encoded, why not find a way of indexing into that content? As with our ASCII routine, we have the issue of implementing an index-based algorithm. For UTF-8, the indexed elements could have different sizes – but must they? What would it take to transfer a String’s content into an array-style set of 32-bit elements? The answer, in Rust, is provided via an arrangement known as a Boxed Slice.
Starting with the ASCII version and converting it for use with Slice content, we need only code a simple Slice-building step, prior to calling the routine, to convert the inbound Strings accordingly. Voilá, UTF-8-ready code! The downside is performance: conversion to Boxed Slices requires heap allocations and an up-front walkthrough, for both the “wild” and “tame” Strings.
That up-front overhead becomes the main performance drag. For most scenarios, the performance of the matching wildcards routine, itself, isn’t very different from that of its ASCII counterpart. But because that up-front conversion is so slow, the ASCII version is probably the way to go, for ASCII text. Because both versions are all-Rust code applied to copies of data that go away once they go out of scope, both benefit from Rust’s fearless concurrency strategy. Listing Two provides the code for the UTF-8 version, and Listing Three adds that up-front Boxed Slice setup that consumes the majority of the overall execution time:
Listing Two
// Rust implementation of FastWildCompare(), for UTF-8-encoded content.
//
// Copyright 2025 Kirk J Krauss. This is a Derivative Work based on
// material that is copyright 2018 IBM Corporation and available at
//
// http://developforperformance.com/MatchingWildcards_AnImprovedAlgorithmForBigData.html
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
// Accepts two Box'd slices of 32-bit code points, typically created from
// wildcard. For each '*' wildcard, seeks out a matching sequence of
// Strings, and compares their content. Accepts '?' as a single-code-point
// code points beyond it. Otherwise compares the content a code point at
// a time.
//
pub fn fast_wild_compare_utf8(
wild_slice: Box‹[char]›,
tame_slice: Box‹[char]›) -> bool
{
let mut iwild: usize = 0; // Index for both inputs in upper loop
let mut itame: usize; // Index for tame content, used in lower loop
let mut iwild_sequence: usize; // Index for prospective match after '*'
let mut itame_sequence: usize; // Index for match in tame content
// Find a first wildcard, if one exists, and the beginning of any
// prospectively matching sequence after it.
loop
{
// Check for the end from the start. Get out fast, if possible.
if tame_slice.len() ‹= iwild
{
if wild_slice.len() › iwild
{
while wild_slice[iwild] == '*'
{
iwild += 1;
if wild_slice.len() ‹= iwild
{
return true; // "ab" matches "ab*".
}
}
return false; // "abcd" doesn't match "abc".
}
else
{
return true; // "abc" matches "abc".
}
}
else if wild_slice.len() ‹= iwild
{
return false; // "abc" doesn't match "abcd".
}
else if wild_slice[iwild] == '*'
{
// Got wild: set up for the second loop and skip on down there.
itame = iwild;
loop
{
iwild += 1;
if wild_slice.len() ‹= iwild
{
return true; // "abc*" matches "abcd".
}
if wild_slice[iwild] == '*'
{
continue;
}
break;
}
// Search for the next prospective match.
if wild_slice[iwild] != '?'
{
while wild_slice[iwild] != tame_slice[itame]
{
itame += 1;
if tame_slice.len() ‹= itame
{
return false; // "a*bc" doesn't match "ab".
}
}
}
// Keep fallback positions for retry in case of incomplete match.
iwild_sequence = iwild;
itame_sequence = itame;
break;
}
else if wild_slice[iwild] != tame_slice[iwild] &&
wild_slice[iwild] != '?'
{
return false; // "abc" doesn't match "abd".
}
iwild += 1; // Everything's a match, so far.
}
// Find any further wildcards and any further matching sequences.
loop
{
if wild_slice.len() › iwild && wild_slice[iwild] == '*'
{
// Got wild again.
loop
{
iwild += 1;
if wild_slice.len() ‹= iwild
{
return true; // "ab*c*" matches "abcd".
}
if wild_slice[iwild] != '*'
{
break;
}
}
if tame_slice.len() ‹= itame
{
return false; // "*bcd*" doesn't match "abc".
}
// Search for the next prospective match.
if wild_slice[iwild] != '?'
{
while tame_slice.len() › itame &&
wild_slice[iwild] != tame_slice[itame]
{
itame += 1;
if tame_slice.len() ‹= itame
{
return false; // "a*b*c" doesn't match "ab".
}
}
}
// Keep the new fallback positions.
iwild_sequence = iwild;
itame_sequence = itame;
}
else
{
// The equivalent portion of the upper loop is really simple.
if tame_slice.len() ‹= itame
{
if wild_slice.len() ‹= iwild
{
return true; // "*b*c" matches "abc".
}
return false; // "*bcd" doesn't match "abc".
}
if wild_slice.len() <= iwild ||
wild_slice[iwild] != tame_slice[itame] &&
wild_slice[iwild] != '?'
{
// A fine time for questions.
while wild_slice.len() › iwild_sequence &&
wild_slice[iwild_sequence] == '?'
{
iwild_sequence += 1;
itame_sequence += 1;
}
iwild = iwild_sequence;
// Fall back, but never so far again.
loop
{
itame_sequence += 1;
if tame_slice.len() ‹= itame_sequence
{
if wild_slice.len() ‹= iwild
{
return true; // "*a*b" matches "ab".
}
else
{
return false; // "*a*b" doesn't match "ac".
}
}
if wild_slice.len() › iwild &&
wild_slice[iwild] == tame_slice[itame_sequence]
{
break;
}
}
itame = itame_sequence;
}
}
// Another check for the end, at the end.
if tame_slice.len() ‹= itame
{
if wild_slice.len() ‹= iwild
{
return true; // "*bc" matches "abc".
}
return false; // "*bc" doesn't match "abcd".
}
iwild += 1; // Everything's still a match.
itame += 1;
}
}
Code for calling the above function, so that it performs both case-sensitive and case-insensitive wildcard matching on the “tame” and “wild” Strings, is included among the correctness and performance testcases on GitHub. The UTF-8 testcases, which also are provided in Listing Five, make use of these lines of code that arrange for case-insensitive wildcard matching:
Listing Three
fn test(tame_string: String, wild_string: String,
b_expected_result: bool) -› bool
{
// ... This is an excerpt of a function called for every testcase ...
//
if b_expected_result != fast_wild_compare::fast_wild_compare_utf8(
wild_string.to_lowercase(
).chars().collect::‹Vec‹char››().into_boxed_slice(),
tame_string.to_lowercase(
).chars().collect::‹Vec‹char››().into_boxed_slice())
{
return false;
}
// ... Further test-specific code ...
return true;
}
Unusual though a heap allocation failure may be, the above code may have to handle a resulting panic, in case the system can’t arrange to allocate the needed memory blocks, or in case the heap has become corrupted. Panic preparedness may matter especially for production code that may see exposure to malicious input. Otherwise this code can be used, as-is, with or without the to_lowercase() call that makes the wildcard match case-insensitive.
The test set for matching wildcards in C/C++ was accumulated over several years with the input of many developers. The test strings are suitable for both the ASCII and UTF-8 Rust implementations. For testing either of the Rust implementations, the strings are passed to the test() function, an excerpt of which appears in Listing Three (above). Listing Four provides an excerpt of some of the tests.
Listing Four
fn test_wild()
{
// ... This is an excerpt of a function that passes strings to the
// above code in test() ...
//
let mut b_all_passed: bool = true;
// ...
// Cases with repeating character sequences.
b_all_passed &= test("abcccd".into(), "*ccd".into(), true);
b_all_passed &= test("mississipissippi".into(), "*issip*ss*".into(), true);
b_all_passed &= test("xxxx*zzzzzzzzy*f".into(), "xxxx*zzy*fffff".into(), false);
b_all_passed &= test("xxxx*zzzzzzzzy*f".into(), "xxx*zzy*f".into(), true);
b_all_passed &= test("xxxxzzzzzzzzyf".into(), "xxxx*zzy*fffff".into(), false);
b_all_passed &= test("xxxxzzzzzzzzyf".into(), "xxxx*zzy*f".into(), true);
b_all_passed &= test("xyxyxyzyxyz".into(), "xy*z*xyz".into(), true);
b_all_passed &= test("mississippi".into(), "*sip*".into(), true);
b_all_passed &= test("xyxyxyxyz".into(), "xy*xyz".into(), true);
b_all_passed &= test("mississippi".into(), "mi*sip*".into(), true);
b_all_passed &= test("ababac".into(), "*abac*".into(), true);
b_all_passed &= test("ababac".into(), "*abac*".into(), true);
b_all_passed &= test("aaazz".into(), "a*zz*".into(), true);
b_all_passed &= test("a12b12".into(), "*12*23".into(), false);
b_all_passed &= test("a12b12".into(), "a12b".into(), false);
b_all_passed &= test("a12b12".into(), "*12*12*".into(), true);
// ... The tests continue ...
if b_all_passed
{
println!("Passed wildcard tests");
}
else
{
println!("Failed wildcard tests");
}
}
For complete UTF-8 testing, code points comprising multiple bytes require testing against the ‘?’ and ‘*’ wildcards’ single-byte code points. Those “wild” bytes are 0x3A and 0x3F, respectively. A string may contain a multiple-byte code point, where the low-order seven bits, of one of the bytes in the code point, also happen to be interpretable as a 0x3A or a 0x3F. (The code point would have to be interpreted as a single-byte ASCII character – effectively, masked with 0x7F – for the confusion to arise.) If the routine for matching wildcards were to consider those seven bits a wildcard, just because they turned up within a multiple-byte code point, it might return a false positive or a false negative result. A false positive result could involve incorrect wildcard matching against a code point that includes more than just the bits of a 0x3A or 0x3F byte. A false negative result is possible when the rest of the code point doesn’t match the bits that remain if those bits were to be mistaken for a separate wildcard code point.
Test cases that check for these multiple-byte scenarios, including a few test strings whose code points include the lower-order seven bits of the 0x3A and 0x3F bytes, are provided in this all-new test_utf8() routine.
Listing Five
// Correctness tests for a case-insensitive arrangement for invoking a
// UTF-8-enabled routine for matching wildcards. See relevant code /
// comments in test().
//
fn test_utf8()
{
let mut b_all_passed: bool = true;
// Simple correctness tests involving various UTF-8 symbols and
// international content.
b_all_passed &= test("🐂🚀♥🍀貔貅🦁★□√🚦€¥☯🐴😊🍓🐕🎺🧊☀☂🐉".into(),
"*☂🐉".into(), true);
b_all_passed &= test("AbCD".into(), "abc?".into(), true);
b_all_passed &= test("AbC★".into(), "abc?".into(), true);
b_all_passed &= test("▲●🐎✗🤣🐶♫🌻ॐ".into(), "▲●☂*".into(), false);
b_all_passed &= test("𓋍𓋔𓎍".into(), "𓋍𓋔?".into(), true);
b_all_passed &= test("𓋍𓋔𓎍".into(), "𓋍?𓋔𓎍".into(), false);
b_all_passed &= test("♅☌♇".into(), "♅☌♇".into(), true);
b_all_passed &= test("⚛⚖☁".into(), "⚛🍄☁".into(), false);
b_all_passed &= test("⚛⚖☁o".into(), "⚛⚖☁O".into(), true);
b_all_passed &= test("⚛⚖☁O".into(), "⚛⚖☁0".into(), false);
b_all_passed &= test("गते गते पारगते पारसंगते बोधि स्वाहा".into(),
"गते गते पारगते प????गते बोधि स्वाहा".into(), true);
b_all_passed &= test(
"Мне нужно выучить русский язык, чтобы лучше оценить Пушкина.".into(),
"Мне нужно выучить * язык, чтобы лучше оценить *.".into(), true);
b_all_passed &= test(
"אני צריך ללמוד אנגלית כדי להעריך את גינסברג".into(),
" אני צריך ללמוד אנגלית כדי להעריך את ???????".into(), false);
b_all_passed &= test(
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.".into(),
"* શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે * શીખવું પડશે.".into(), true);
b_all_passed &= test(
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.".into(),
"??????????? શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે * શીખવું પડશે.".into(), true);
b_all_passed &= test(
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે અંગ્રેજી શીખવું પડશે.".into(),
"ગિન્સબર્ગની શ્રેષ્ઠ પ્રશંસા કરવા માટે મારે હિબ્રુ ભાષા શીખવી પડશે.".into(), false);
// These tests involve multiple=byte code points that contain bytes
// identical to the single-byte code points for '*' and '?'.
b_all_passed &= test("ḪؿꜪἪꜿ".into(), "ḪؿꜪἪꜿ".into(), true);
b_all_passed &= test("ḪؿUἪꜿ".into(), "ḪؿꜪἪꜿ".into(), false);
b_all_passed &= test("ḪؿꜪἪꜿ".into(), "ḪؿꜪἪꜿЖ".into(), false);
b_all_passed &= test("ḪؿꜪἪꜿ".into(), "ЬḪؿꜪἪꜿ".into(), false);
b_all_passed &= test("ḪؿꜪἪꜿ".into(), "?ؿꜪ*ꜿ".into(), true);
if b_all_passed
{
println!("Passed UTF-8 tests");
}
else
{
println!("Failed UTF-8 tests");
}
}
Calling a C/C++ routine from Rust using the cc-rs library is as easy as referencing its source code in a build.rs script, declaring the routine to be called in an unsafe extern "C" block in the Rust source file, and building the project using the cargo tool. This build.rs script refers to a file that includes source code for the 2-loop pointer-based and index-based C/C++ routines for matching wildcards.
Listing Six
// build.rs
use cc;
fn main() {
cc::Build::new()
.file("src/fastwildcompare.cpp")
.compile("fastwildcompare");
}
The only modification needed, for that source code to be built via cargo, is that the FastWildCompare() and FastWildComparePortable() functions are declared as extern "C". These functions also are similarly declared in the Rust source file where they’re called for performance comparison against the two Rust implementations.
Listing Seven
// Standard modules for use with the String type, C/C++ functions, and
// performance tests.
use std::ffi::CString;
use std::os::raw::c_char;
use std::time::Instant;
// Declarations for ASCII and UTF-8 functions for matching wildcards in Rust.
mod fast_wild_compare;
// Declarations for performance comparison with C++ versions of the algorithm
// on which the ASCII and UTF-8 functions are baseed.
unsafe extern "C" {
pub fn FastWildCompare(
ptame: *mut cty::c_char,
pwild: *mut cty::c_char,
) -> bool;
pub fn FastWildComparePortable(
ptame: *mut cty::c_char,
pwild: *mut cty::c_char,
) -> bool;
}
Performance comparison itself is easy to arrange via placement of a call to Instant::now(), which returns an instant structure, just ahead of each call to an implementation for matching wildcards, plus a call to the instant’s elapsed() method just afterwards. For half a million iterations, the 200+ testcases of the ASCII test set are passed to each of the implementations. Timings for each are accumulated in file-scope variables, in the single-threaded example code. Use of file-scope data isn’t thread-safe, but it tends to reduce latency factors that may otherwise affect the timing results, in a way that retains human readability. A couple of thread-safe alternatives would be to pass the accumulated timing data around as function parameters or to accumulate it in thread-local or task-local storage.
How do the four implementations stack up to one another? The added logic for length checking, in the Rust implementations, creates some overhead compared to relying on terminating nulls that benefit the C/C++ implementations as a matter of course. Despite that, the all-Rust implementation for ASCII text is no slouch. A difference as small as a few seconds, while handling over a hundred million calls for matching wildcards, won’t be noticeable in most everyday scenarios. Here’s the result of a test run on an AMD FX-8300™ 3.3 GHz system running Windows 10®:
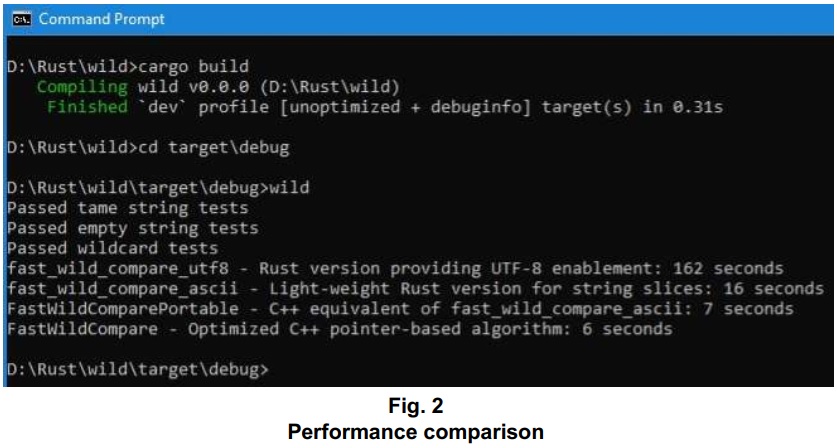
As for the UTF-8 implementation, there’s nothing surprising about the 10x performance drag compared to the ASCII implementation in Rust. That’s the slowdown associated primarily with the up-front heap allocations and string walks. Because those steps are necessary, the time required for them is included in these results. In cases where a Boxed Slice can serve more purposes than just matching wildcards – such as further index-based access to one or both of the inbound UTF-8-encoded Strings – that’s when the optimized logic of fast_wild_compare_utf8() can have the most prospectively noticeable benefit. Instead of a 10x difference, performance of fast_wild_compare_utf8() and fast_wild_compare_ascii() is probably similar, if those up-front steps are factored out.
Repeating the test run using a release build, on Windows, the numbers are improved across the board, especially for the two Rust implementations. There remains about a 10x performance difference between the ASCII and UTF-8 versions. The Rust and C/C++ ASCII implementations reach a fairly close match in performance. The results may of course vary, given platform-specific (and other) factors that can affect optimizations for release builds.
Even with that 10x difference, this drop-in function for matching wildcards is a first. It’s designed and demonstrated to be UTF-8-ready and implemented in what’s arguably the most thread safe native code context there is. The testcases that come with it comprise what’s probably the most thorough matching wildcards test set there is. And it’s got a sure performance edge over methods that aren’t specific to the ‘*’ and ‘?’ wildcards. No routine is perfect, but I’m reminded of the first time I shared code for matching wildcards: there’s now, as there was then, nothing to quite match it.
Complete source code associated with this article is available at GitHub > kirkjkrauss > MatchingWildcardsInRust. The above source code listings are formatted using the SyntaxHighlighter library, copyright (c) 2004-2013, Alex Gorbatchev.
Cited materials include:
Brodie, Leo. Thinking Forth: A Language and Philosophy for Solving Problems. Englewood Cliffs, NJ: Prentice-Hall, Inc. 1984.
Kaner, Cem. “What IS a Good Test Case?” Orlando, FL: STAR East 2003.
All other materials copyright © 2025 developforperformance.com.
Rust™ and Cargo™ are trademarks of the Rust Foundation. AMD FX™ is a trademark or registered trademark of Advanced Micro Devices, Inc. Windows® is a trademark or registered trademark of Microsoft Corp. JavaScript™ is a trademark of Oracle Corporation. Forth™ is a trademark of FORTH, Inc.